XiaoMi-AI文件搜索系统
World File Search SystemRewards




EV 智能奖励 NM
宝马:i3 2016-2021年、3系插电式混合动力汽车 2016+、5系PHEW 2017+、7系插电式混合动力汽车 2017+、i8 2014-2021年、X3 PHEV 2020-2021年、X5 插电式混合动力汽车 2016+、i4 2021+、i5 2024+、i7 2023+ 大众:e-Golf 2020、ID.4 2021+、Tiguan PHEV 2023+ 丰田:RAV4 Prime 2021+、Prius Prime 2022+、bZ4x 2023+ 雪佛兰:Bolt 2017+、Volt 2015-2019 起亚:EV6 2022+、EV9 2024+雷克萨斯: RX450h 2023+、RZ 2023+ 充电器:ChargePoint:Home Flex Wallbox Pulsar Plus Emporia 请注意,要将您的车辆连接到我们,您需要有效的联网服务订阅。如果您没有看到您的电动汽车或充电器,请联系我们!我们会将您添加到候补名单中,并在集成可用时与您联系。6. 如何注册该计划?

奖励政策内幕 2024-04
关于确定受益计划计算一次性付款和其他加速分配形式的要求。这些最终法规与 2016 年发布的拟议法规基本相似,但有一些技术变化和澄清。背景《国内税收法典》(“法典”)第 417 条和实施条例规定了确定受益计划在确定未以正常年金形式支付的参与人福利的现值时必须遵循的各种规则。例如,如果现值低于 7,000 美元(或计划设定的较低门槛),计划可以规定立即兑现终止雇员的福利。此外,如果福利以“减少”的形式支付(例如社会保障水平收入选项),则计划必须使用法典第 417(e) 条规定的利率和死亡率假设。 2016 年 11 月,财政部和国税局发布了拟议法规,对《税法》第 417(e) 条关于确定福利计划现值计算的要求做出了多项技术性更改。拟议法规还包括一些变化,以反映《税法》的最新修订,包括 2006 年《养老金保护法》,并消除过时的措辞。最终法规概述最终法规的重要亮点如下:



长期存储的审查
28。除了不可排除法律的任何责任,包括不可判有的担保,AGL(包括其各自的官员,雇员,代理人和相关机构)不包括任何人身伤害的所有责任(包括疏忽);或任何损失或损害(包括失去机会),无论是直接,间接,特殊或结果,都以任何方式出现在促销中;包括从以下情况下引起的(i)任何技术困难或设备故障(无论是否在AGL的控制下)可能会延迟或阻止成功完成晋升或任何相关活动; (ii)任何盗窃,未经授权的访问或第三方干预; (iii)由于任何理由超出了对AGL的合理控制,因此任何迟到,丢失,更改,损坏或误导的入场或奖励索赔(无论是否在AGL收到后); (iv)在这些条款和条件中所述的奖品价值的任何变化; (v)获胜者或参赛者产生的任何税收责任;或(vi)任何人使用或滥用奖品。
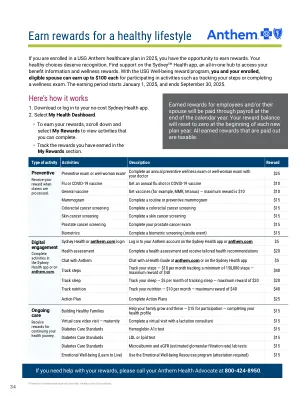
Anthem 2025 奖励计划
如果您在 2025 年加入 USG Anthem 医疗保健计划,您就有机会获得奖励。您的健康选择值得认可。在 Sydney SM Health 应用程序上寻求支持,这是一个访问您的福利信息和健康奖励的一体化中心。通过 USG 健康奖励计划,您和您已加入的合格配偶可以通过参与跟踪您的步数或完成健康检查等活动,每人最多可获得 100 美元。赚取期从 2025 年 1 月 1 日开始,到 2025 年 9 月 30 日结束。

GFLOWNET廉价奖励
生成流动网络(GFLOWNETS)最近出现了一类生成模型,是通过从非均衡奖励分布中学习来生成多样化和高质量分子结构的合适框架。以前朝这个方向的工作通常通过使用预定义的分子碎片作为构建块来限制探索,从而限制了可以访问的化学空间。在这项工作中,我们引入了原子Gflownets(A-GFNS),这是一种基本生成模型,利用单个原子作为基础,以更全面地探索类似药物的化学空间。我们使用离线药物样分子数据集提出了一种无监督的预训练方法,该方法在廉价但信息丰富的分子描述符上(例如药物类似性,拓扑极性表面积和合成可及性得分)对A-GFN进行了评论。这些特性是代理奖励,将A-GFN引导到具有理想的药理特性的化学空间区域。我们通过实施目标的微调过程来进一步进一步,该过程适应A-GFN以优化特定目标属性。在这项工作中,我们在锌15离线数据集上预认识了A-GFN,并采用了强大的评估指标来显示与药物设计中其他相关基线方法相比,我们的方法的有效性。