XiaoMi-AI文件搜索系统
World File Search SystemSIFT

使用平均强度、SVM 和 SIFT 检测驾驶员疲劳
驾驶员疲劳是事故的主要原因之一。这增加了对车辆中驾驶员疲劳检测机制的需求,以减少事故期间的人员和车辆损失。在提出的方案中,我们从安装在车辆内的摄像头拍摄视频。从拍摄的视频中,我们使用 Viola-Jones 算法定位眼睛。一旦眼睛被定位,就会使用三种不同的技术(即平均强度、SVM 和 SIFT)将它们分类为睁开或闭合。如果发现眼睛闭了很长时间,则表示疲劳,因此会发出警报提醒驾驶员。我们的实验表明,SIFT 的表现优于平均强度和 SVM,在五个视频的数据集上实现了 97.45% 的平均准确率,每个视频的长度为两分钟。DOI:10.9781/ijimai.2017.10.002

结合 SIFT 和 SGM 算法进行立体图像密集匹配
关键词:立体匹配,半全局匹配,SIFT,密集匹配,视差估计,普查 摘要:半全局匹配(SGM)通过平等对待不同路径方向进行动态规划。它没有考虑不同路径方向对成本聚合的影响,并且随着视差搜索范围的扩大,算法的准确性和效率急剧下降。本文提出了一种融合SIFT和SGM的密集匹配算法。该算法以SIFT匹配的成功匹配对为控制点,在动态规划中指导路径,并截断误差传播。此外,利用检测到的特征点的梯度方向来修改不同方向上的路径权重,可以提高匹配精度。基于 Middlebury 立体数据集和 CE-3 月球数据集的实验结果表明,所提算法能有效切断误差传播,缩小视差搜索范围,提高匹配精度。

使用SIFT功能
摘要 - 无人驾驶汽车(UAV)在各种应用中都是必不可少的,包括监视,城市场景分析和农业监测。准确的高度估计对于无人机操作至关重要,尤其是在GPS,压力高度计和雷达等传统传感器可能失败的环境中。本文探讨了红外和热成像的使用,用于对无人机的相对高度估计,从而强调了它们的显着优势,而不是传统的RGB图像。红外和热成像在弱光和不利天气条件下提供了卓越的表现,从而提供了更清晰的可见性和更可靠的特征检测。通过杠杆来使尺度不变特征变换(SIFT)特征,此方法利用热图像的固有优势来估计基于连续图像中匹配的键盘的尺寸变化的高度变化。对两个红外热无UAV数据集的实验结果证明了这种方法的有效性,与暹罗网络结合使用以增强功能匹配,显示出估计准确性的显着提高。索引项 - 临时,红外热图像,无人机,海拔估计,暹罗网络。

的筛选生产成本,然后提高电费关税'
八打灵再也:政府必须在提高人们对人民的关税之前,必须解释发电的成本。从2025年7月开始,马来西亚半岛可能会生效14%的电价增长,等待政府的决定。团体表示,影响工业用户和国内用户的关税增加是在生活成本上涨的时候。水与能源研究协会马来西亚总裁S. Piarapakaran呼吁政府在生产电力的成本上保持透明,以确保仅将有效的成本传递给关税。“在监管期4中,TNB(Tenaga nasional bhd)的基本关税增加约为5sen/kWh,高于以前的监管期。“诸如绿色电价,可再生能源工厂的待机费用和直接谈判也必须解决,以防止企业和公众不必要的费用。”

手写签名识别的 LBP、HOG 和 SIFT 技术的比较分析
摘要——手写签名识别是生物特征认证的关键组成部分,需要稳健高效的特征提取技术才能获得最佳性能。本研究对三种主要的特征提取方法进行了比较分析:局部二值模式 (LBP)、方向梯度直方图 (HOG) 和尺度不变特征变换 (SIFT)。我们使用一个包含 2,000 个签名的精选数据集(包括真实实例和熟练的伪造签名),评估了每种技术在准确性、计算效率和稳健性方面的有效性。我们的研究结果表明,虽然 HOG 表现出卓越的准确性,但 LBP 在计算速度方面表现出色,而 SIFT 则展示了处理各种捕获场景的潜力。这项研究为开发先进的签名识别系统提供了宝贵的见解,强调了定制特征提取对增强生物特征认证的重要性。

深度筛分卷积神经网络,用于从3D超声图像中进行总脑体积估计
早产儿是一个高度脆弱的人群。这些婴儿的总脑体积(TBV)可以通过脑超声(US)成像来准确估算,从而可以对新生儿重症监护(NICU)入院期间对早期大脑生长进行纵向研究。对3D图像的TBV自动估算可提高诊断速度,并逃避专家手动分段3D图像的必要性,这是一项精致且耗时的任务。我们开发了一种深入学习方法来从3D超声图像中估算TBV。它从深度卷积神经网络(CNN)带来了延伸的残留连接和额外的层,灵感来自模糊C均值(FCM),以进一步将特征分离为不同的区域,即筛分层。因此,我们称此方法为深卷积神经网络(DSCNN)。使用从两个不同的超声设备中获取的两个数据集进行了TBV估计,以包括Alexnet-3D,Resnet-3D和VGG-3D在内的三种最新方法进行验证。结果突出显示了预测与观察到的TBV值之间的密切相关性。回归激活图用于解释DSCNN,从解剖学的角度探索那些更一致和合理的像素来允许TBV估计。因此,它可用于从3D图像中直接估算TBV,而无需进一步的图像分割。

自动快速且强大的技术来细化提取...
4. 吕勒奥理工大学土木环境与自然资源工程系,瑞典吕勒奥 97187 摘要:尺度不变特征变换 (SIFT) 自动提取控制点 (CP) 的能力在遥感图像中非常著名,然而,其结果不准确,有时由于生成少量错误 CP 对而导致匹配不正确,其匹配具有很高的误报。本文介绍了一种包含修改的方法,通过以不同方式应用绝对差和 (SAD) 来提高 SIFT CP 匹配的性能,适用于新一代光学卫星(称为近赤道轨道卫星 (NEqO))和多传感器图像。所提出的方法可以提高 CP 匹配率,并显著提高正确匹配率。本研究中的数据来自覆盖吉隆坡-北干地区的 RazakSAT 卫星。该方法包括三部分:(1)应用 SIFT 自动提取地面控制点;(2)使用经验阈值的 SAD 算法细化地面控制点匹配;(3)通过将原始 SIFT 结果与所提方法的结果进行比较来评估细化后的地面控制点场景。结果表明该模型具有准确和精确的性能,证明了所提方法的有效性和鲁棒性。关键词:地面控制点自动提取、绝对差和、近赤道卫星、多传感器、改进的 SIFT。1.
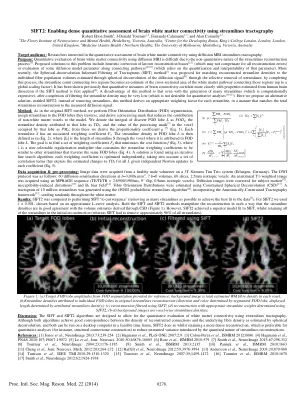
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。

致编辑的信:推出新的索引...
后基因组时代,人们已经开发出多种计算方法(例如 PolyPhen、SIFT 和 GERP)来对单核苷酸变异 (SNV) 和短插入/缺失对人类基因组的影响进行排序。组合注释依赖性消耗 (CADD) 就是这些计算方法之一。它是一种基于 60 多个基因组特征(包括 GERP、ENCODE、phyloP、SIFT、PolyPhen)建立的综合指数,用于衡量人类基因组中遗传变异的风险。因此,该方法可以更可靠地评估 SNV 的有害性。CADD 工具分数(C 分数)是根据从进化约束、周围序列背景、表观遗传测量、功能预测和基因模型注释中得出的几种基因组特征计算得出的(Kircher 等人,2014;Rentzsch 等人,2019)。 CADD 是一种广泛使用的指数,用于测量 SNV 对人类严重孟德尔遗传疾病的因果影响。
