XiaoMi-AI文件搜索系统
World File Search SystemSUPPLEMENTARY

欧洲人权公约——补充备忘录
1 可在此处访问:ECHR 备忘录 (publishing.service.gov.uk) 2 可在此处访问:4240 (parliament.uk) 3 可在此处访问:ECHR (publishing.service.gov.uk)

补充信息 Functionnectome 作为...
• 在 MacOS/Unix/Linux 上,使用“ls”命令。例如,假设我的所有文件都存储在以下路径中:“ /myhome/current_project/subject????/ functionalFiles/ fMRI_acquisition.nii.gz ”,其中“ ???? ”是每个主题都不同的唯一 ID(例如数字)。使用尽可能多的“?”ID 号中的数字越多。要显示所有文件路径,只需输入命令(在终端中):“ ls -1 /myhome/current_project/subject????/funFiles/fMRI_acquisition.nii.gz ” 这里,“ls”将列出所有路径,“-1”选项将每行显示一个路径。• 在 Windows 上,使用“dir”命令,类似于上面提到的“ls”。





补充信息 (ESI)
a 反应条件:0.5 mmol HMF;无氧化催化剂;O 2 ,1.0 MPa;H 2 O,10 ml;温度,120 o C;反应时间,18 h;NaHCO 3 /HMF=2。b DFF、HMFCA、FFCA 和 FDCA 分别表示 2,5-二甲酰基呋喃、5-羟甲基-2-呋喃羧酸、5-甲酰基-2-呋喃羧酸和 2,5-呋喃二羧酸。c 碳平衡基于可检测产物,包括 DFF、FFCA、HMFCA、FDCA、甲酸、乙酰丙酸、2,5-呋喃二甲醇 (DHMF) 等。d 其他包括腐殖质和 HPLC 无法检测到的其他产物。

补充材料 - repisalud
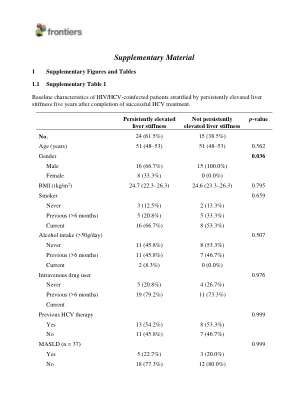
统计:数据是通过具有伽马分布(LOG-LINK)的广义线性模型(GLM)计算的。多变量模型按年龄,性别,HCV治疗(基于IFN的治疗或DAAS),在治疗后一年进行LSM调整,并且在两次之间经过的时间,以前是通过逐步方法(前进)选择的(请参阅结果部分)。Q值代表使用错误发现率(FDR; Benjamini和Hochberg程序)进行多次测试校正的p值。统计上的显着差异以粗体显示。缩写:AMR,算术平均比例; AAMR,调整后的AMR; 95%CI,95%的置信区间; P,意义水平; q,校正的意义水平; BTLA,B和T淋巴细胞衰减剂; CD,分化簇; GITR,糖皮质激素诱导的TNFR相关; HVEM,疱疹病毒入学调解人; IDO,吲哚胺2,3-二氧酶; lag-3,淋巴细胞激活基因-3; PD-1,程序性细胞死亡蛋白1; PD-L1,编程的死亡配体1; PD-L2,编程死亡配体2; TIM-3,T细胞免疫球蛋白和含有3的粘蛋白膜。

补充材料抗议
插入中包含的插补方法均已先前已开发,测试和广泛使用(Chilimoniuk等人。2024; Hastie等。2000; Pantanowitz和Marwala,2009年; Stekhoven等。2011; Troyanskaya等。2001; van Buuren等。 1999; van Buuren等。 2006; van Buuren等。 2011; Wright和Ziegler,2017年)。 如果在分析中选择了优化,则植入确定不同方法的插补错误率,并向用户建议数据集的最佳性能插补方法。 通过在所有方法和超参数范围内的网格搜索中,对给定数据集的插补的最佳方法进行。 确定了三种不同类型的丢失的误差级:完全随机丢失(MCAR),而不是随机丢失(MNAR),而在随机(MAR)中丢失。 优化搜索中使用的超参数值在补充表1中显示。2001; van Buuren等。1999; van Buuren等。 2006; van Buuren等。 2011; Wright和Ziegler,2017年)。 如果在分析中选择了优化,则植入确定不同方法的插补错误率,并向用户建议数据集的最佳性能插补方法。 通过在所有方法和超参数范围内的网格搜索中,对给定数据集的插补的最佳方法进行。 确定了三种不同类型的丢失的误差级:完全随机丢失(MCAR),而不是随机丢失(MNAR),而在随机(MAR)中丢失。 优化搜索中使用的超参数值在补充表1中显示。1999; van Buuren等。2006; van Buuren等。 2011; Wright和Ziegler,2017年)。 如果在分析中选择了优化,则植入确定不同方法的插补错误率,并向用户建议数据集的最佳性能插补方法。 通过在所有方法和超参数范围内的网格搜索中,对给定数据集的插补的最佳方法进行。 确定了三种不同类型的丢失的误差级:完全随机丢失(MCAR),而不是随机丢失(MNAR),而在随机(MAR)中丢失。 优化搜索中使用的超参数值在补充表1中显示。2006; van Buuren等。2011; Wright和Ziegler,2017年)。如果在分析中选择了优化,则植入确定不同方法的插补错误率,并向用户建议数据集的最佳性能插补方法。通过在所有方法和超参数范围内的网格搜索中,对给定数据集的插补的最佳方法进行。确定了三种不同类型的丢失的误差级:完全随机丢失(MCAR),而不是随机丢失(MNAR),而在随机(MAR)中丢失。优化搜索中使用的超参数值在补充表1中显示。