XiaoMi-AI文件搜索系统
World File Search SystemScale

Scale AI, Inc.-RIN 3064-ZA24
AI 可解释性对于金融服务至关重要,因为许多决策直接影响机构的资金流入和流出。基于决策树或回归构建的模型是有益的,因为输出直接受到一组定义参数的影响。但是,这些模型过于简单,缺乏处理更复杂数据类型或任务的稳健性。深度学习模型正在成为 AI 应用程序的标准,因为它们能够更有效地学习数据集中的细微特征,并在各种金融服务工作流程中以更高的准确度执行。但是,深度学习的一个主要缺点是更难直接解释预测背后的原因,这在为金融服务用例部署 AI 模型时是一个挑战,因为了解决策过程很重要(例如贷款申请)。

大规模人工智能科学
奖项详情和要求:奖项期限和资金申请:三个技术重点领域各设一个奖项:多物理应用、生物系统或材料发现。提案可申请三年的支持。技术重点领域提案的资金申请预计为三年的奖项期限内约 600 万美元(包括间接费用)。每个团队必须至少有三所 UC 校区参与,最好是四所,外加一个或两个 UC 管理的 NNSA 国家实验室(洛斯阿拉莫斯和劳伦斯利弗莫尔国家实验室)的参与。超过允许最高限额的年度项目总成本可由其他支持或捐款来源支付(请参阅下文的“NNSA 国家实验室捐款”)。总预算必须与提议的活动和提案的潜在影响相称。资金应优先用于支持 UC 学生和博士后学者的研究和培训,特别是支持促进研究生获得学位的活动。拟议的预算应寻求有效利用资源,以最大限度地提高研究成果并最大限度地降低管理成本。完整提案中需要列出每个合作机构的详细预算和理由。允许和不允许的成本:完整的申请说明将包括允许和不允许的成本说明。加州大学各校区以及 NNSA 和 DOE 科学办公室国家实验室均可将其批准的间接成本率 (MTDC 基础) 计入奖项。作为一般指导,请注意,本奖项提供的资金可能不包括任何机密研究活动、患者护理费用、临床试验、专利执行费用、筹款费用、设备维护或对非加州大学附属实体的分奖项。不允许国家实验室或国家用户设施购买设备。如果提供了令人信服的理由,则可以要求加州大学各校区购买设备,并且整个加州大学系统都可以使用和访问该设备。设备必须永久位于加州大学的校园位置,不得购买用于永久安装在非加州大学位置。

McGinty-Nottale 尺度方程 (MNSE)
简介 在理论物理的动态领域,统一和调和不同理论的追求往往会催化突破性的进步。本文介绍了 MNSE,这是一个创新的理论框架,它将麦金蒂方程 (MEQ) 与 Laurent Nottale 的标度相对论相结合。MEQ 因将分形几何融入量子场论 (QFT) 而闻名,它与标度相对论的时空分形结构和标度相关物理定律前提相交叉。由此产生的 MNSE 提出了我们对量子力学理解的深刻转变,为时空和量子现象的复杂性质提供了一个细致入微的视角。本文旨在剖析这种整合的复杂性,阐明 MNSE 如何重新定义我们对量子通信的理解,并描述其对全球连接和信息安全的巨大影响。

COO 与 AI:把握尺度
首席运营官需要确保其组织掌握基本知识。首先要确保数据来自公司外部,并与所有利益相关者共享。其次,提供持续的技能培训,为员工做好准备。员工需要确信建议是准确的,这可以通过确保建议是可解释的来实现。第三,在扩展人工智能时考虑道德问题,确保将人工智能考虑因素纳入您的核心价值观和强大的合规流程,并实施特定的技术指南,以确保人工智能系统安全、透明且负责,以保护员工、消费者和其他利益相关者。


无性水平和扩散规模
羊栖菜是东亚地区一种具有商业价值的大型藻类,了解这种大型藻类的繁殖策略对于保护和恢复至关重要。在这里,我们使用种群遗传学方法来确定羊栖菜的繁殖策略。为此,我们执行了两种采样程序:随机采样和方形采样。对于随机采样,我们在相距 700 米的 A、B、C 和 D 地点以 > 1 米的间隔采集了 80 个样本。对于方形采样,我们在 B 和 D 两个地点使用由 10 厘米网格组成的 50 厘米 × 50 厘米方形采集了 207 个样本。使用 14 个(随机采样)或 13 个微卫星(方形采样)通过基因分型识别这些样本中的克隆同源体。对于通过随机采样获得的样本,仅检测到三对克隆对。对于通过样方取样获得的样本,每个样方包含 4– 7 个基株,平均大小为 23.2 ± 14.3 厘米(标准差),最大为 70.7 厘米。地点 B 的无性水平高于地点 D,这可能是由于暴露时间较长。地点 B 位于该物种潮间带的后缘。通过有性生殖的基因流动超过 65% 局限于样方内,而至少 10% 延伸至数米至数公里。综合起来,这些结果表明 S. fusiforme 在小范围内通过有性和无性传播其后代,在更大范围内通过有性传播,无性水平取决于暴露产生的压力。

大规模水文学中的博士学位大规模水文学中的博士学位
我们邀请申请在大规模水文学中的博士职位,重点是计算和数据驱动方法,而不是传统的水文专业知识。该立场将着重于开发和应用计算方法来解决大规模水文学中的复杂问题,例如水文建模,洪水风险评估,水资源管理和气候变化对水系统的影响。您将使用基于机器学习和基于过程的模型来大规模识别流量生成的驱动因素。

在规模上解锁效率和敏捷性
在这种技术进化的最前沿是Kubernetes,这是一个开源的容器编排平台,已成为该行业的事实上标准。其变革性影响重塑了组织如何部署,扩展和管理容器化应用程序的基础。容器化的基本概念涉及将应用程序及其依赖关系封装在轻巧的便携式容器中。与传统的虚拟化方法形成鲜明对比的是,容器共享主机OS内核。这会导致启动时间明显更快,并可以更有效地利用资源。
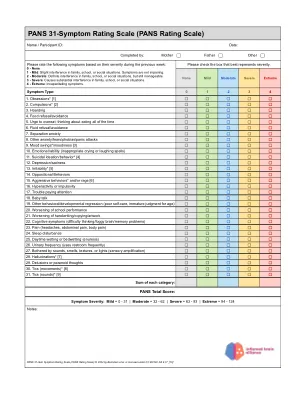
PANS 31-响应评级量表
[8]它们是突然的混蛋或动作,例如有力的眼睛闪烁或从一侧到另一侧的快速头。一些抽动可能更微妙,例如鼻子颤抖。它们在正常行为中发生。其他电动抽动包括猛拉头部,手臂或腿,或以看起来很奇怪或太频繁的方式伸展嘴或下巴。

大规模住宅开发
Rathdown County Council Lands at Blackglen Road, Sandyford, Dublin 18 Dear Sir / Madam, We, Brock McClure Planning & Development Consultants, 63 York Road, Dún Laoghaire, Co. Dublin are instructed by our client, Zolbury Ltd, Unit 9, Ardcavan Business Park, Ardcavan, Co. Wexford, to lodge this LRD application to to Dún Laoghaire Rathdown县议会在大规模住宅开发(LRD)过程中。该请求与192号提案有关。住宅单位,育儿设施,形式为6 no。新的公寓楼(A1 - B4)和40座公寓(C1,C2,C2A)和14座房屋(D1&D2),位于都柏林Sandyford的Blackglen Road的土地上,都柏林18。该计划的演变是通过与DúnLaoghaireRathdown县议会互动而产生的。申请人和设计团队正式与DúnLaoghaireRathdown县议会进行初步讨论,于2024年3月13日在拟议开发项目的草稿中介绍了草案。从第247节中与DúnLaoghaire-Rathdown县议会代表的第247节进行了预定会议,并考虑了设计团队根据收到的反馈准备了一项最新提案,该建议是根据《 2000年规划与发展法》第32B条提出的(已修改了)(参见PAC/LRD2/005/005/005/005/24)。随后的LRD会议于2024年7月25日与规划机构举行。随后规划机构于2024年8月23日发表了意见。现在提交的提案中解决了计划当局提出的所有事项。提供以下详细信息:,如果申请人在与计划机构的意见差异方面偏离了偏差,那么就遵守国家政策而言,支持该提案有一个明确的理由。正如DúnLaoghaire-rathdown县议会所确认的那样,该LRD计划申请请求包括通过电子计划门户进行的1份数字副本。我们还确认,公众可以在以下网站上查看所有材料的数字副本:www.bgrlrd.ie。