XiaoMi-AI文件搜索系统
World File Search SystemScores
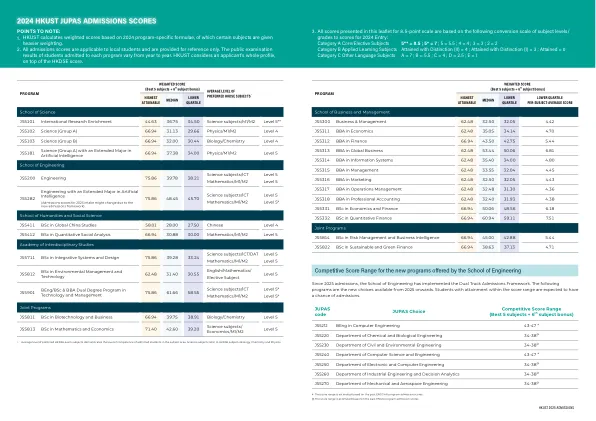
2024 HKUST JUPAS录取分数
3。在此传单中提出的8.5分量表中提出的所有分数均基于以下对2024年入境的受试者水平/等级的转换量表:类别A核心/选修课5 ** = 8.5; 5* = 7; 5 = 5.5; 4 = 4; 3 = 3; 2 = 2 b类应用的学习科目以区别为单位(ii)= 4;以区别(i)= 3;获得= 0类C其他语言主题a = 7; b = 5.5; C = 4; d = 2.5; E = 1
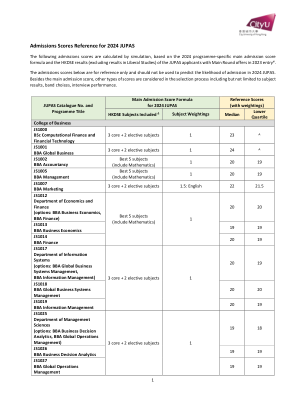
2024 年联招入学分数参考
© 版权所有。此处提供的信息完全归城大所有。城大提醒公众,未经城大事先知情或书面同意而由他人复制的任何此类信息可能不完整、误导和/或不准确。城大对未经授权使用此类数据不承担任何责任。


2024-25牵引力和屈曲分数:耐克
牵引评分基于在合成草皮实验室测试期间防滑钉模式的释放特性。屈曲评分基于弯曲到潜在的有害水平时的防滑钉抗抗性。尽管这些得分与现场损伤率没有相关,但在两种测试中,较高的得分被认为是更好的实验室表现。玩家应选择专门为美式足球需求而设计的鞋类。

关于 c 测试分数的有效性和可靠性:一项元分析......
4.2.5.1 报告特征 ................................................................................................116 4.2.5.2 背景 ..............................................................................................................120 4.2.5.3 参与者 ..............................................................................................................122 4.2.5.4 使用 ..............................................................................................................124 4.2.5.5 效果大小 ......................................................................................................126 4.2.5.6 描述性 .............................................................................................................128 4.2.5.7 可靠性(C 检验和标准) .............................................................................130 4.2.5.8 C 检验构造 ................................................................................................132 4.2.5.9 C 检验开发 ................................................................................................135 4.3 结果综合 .............................................................................................................................138
关于 c 测试分数的有效性和可靠性:一项元分析......
4.2.5.1 报告特征 ................................................................................................116 4.2.5.2 背景 ..............................................................................................................120 4.2.5.3 参与者 ..............................................................................................................122 4.2.5.4 使用 ..............................................................................................................124 4.2.5.5 效果大小 ......................................................................................................126 4.2.5.6 描述性 .............................................................................................................128 4.2.5.7 可靠性(C 检验和标准) .............................................................................130 4.2.5.8 C 检验构造 ................................................................................................132 4.2.5.9 C 检验开发 ................................................................................................135 4.3 结果综合 .............................................................................................................................138


了解 3D™ AI CAD 中的案例评分
包含数据库中约 32.1% 的癌症病例,约 4.3% 的非癌症病例处于此范围。在 100,000 名女性的人口中,癌症发病率为 5.1/1000,平均有 510 例癌症和 99,490 例非癌症。预计平均会有约 164 例癌症病例得分为 76-100(32.1% x 510 例癌症),约 2,700 例非癌症病例得分为 0(4.3% x 99,490)。因此,在约 4,200 例病例得分为 76-100 的病例中,每 27 例中约有 1 例是癌症 164/(4300+164)。在此示例中,为了清楚起见,对数字进行了四舍五入;更精确的数字如表 1 所示。可以对其他病例评分箱进行类似的分析,从观察到的数据库分布中推断,以估计一般筛查环境中的预期数字,从而得出给定病例评分中可能是癌症的分数的估计值。
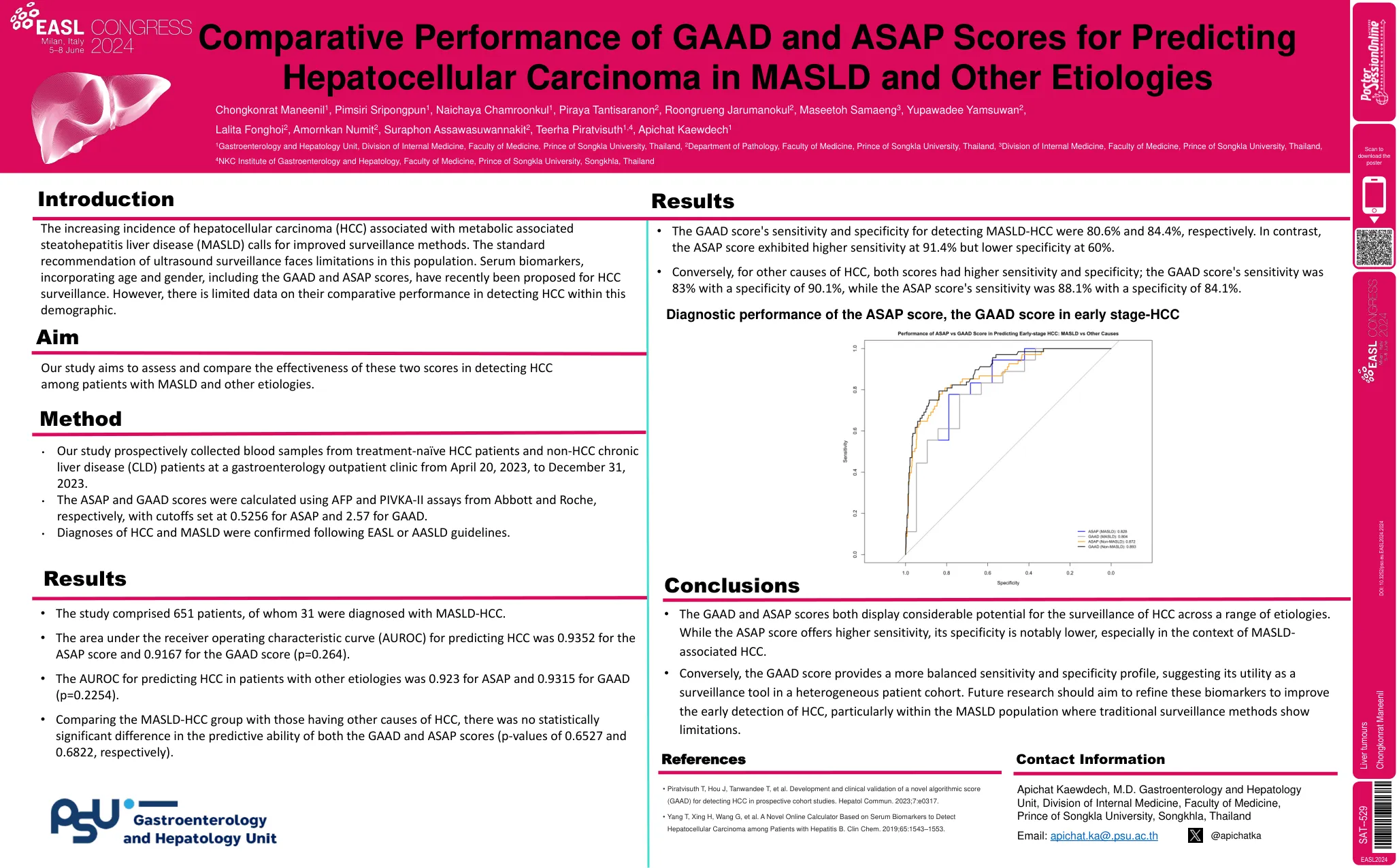
Sophia l Ling 1,Bishma Jayahthilaka2,3,...
与代谢相关的脂肪性肝炎肝病(MASLD)相关的肝细胞癌(HCC)的发生率增加,要求改善监测方法。超声监视的标准建议面临该人群的局限性。血清生物标志物(包括GAAD和ASAP评分在内的年龄和性别)最近提出了HCC监视。但是,在该人群中检测HCC时,其比较性能的数据有限。

2024 JUPAS录取分数9 jupas参加 -
b和c受试者),由申请人在JUPAS主回合中获得相应研究计划的申请人获得的受试者加权(如果申请人使用替代中文和/或HKDSE以外的其他英语结果来满足入学要求,将增加Engl和Chin的3分; b)中间位置(中间); c)JUPAS主回合的下四分位数位置(3/4向下)提供每个程序的排名列表。并非所有课程仅根据HKDSE的结果选择学生,而接受每个课程的学生的实际结果可能每年都有不同(取决于申请人在特定年份中获得的总体结果,申请申请的申请人人数,申请的变化,选择标准的变化,例如面试绩效,访谈表现,非acapacempormic corvelys等, ),本节中的信息仅供参考,不应用于预测随后几年的任何计划的入学机会。 *分数公式的注释:以下每个程序的分数公式仅适用于2024年条目。 对于2025年条目的每个程序的更新得分公式,请参阅网站:https://admissions.hkbu.edu.hk/uploads/en en/download/pdf/2025-pers.pdf。),本节中的信息仅供参考,不应用于预测随后几年的任何计划的入学机会。*分数公式的注释:以下每个程序的分数公式仅适用于2024年条目。对于2025年条目的每个程序的更新得分公式,请参阅网站:https://admissions.hkbu.edu.hk/uploads/en en/download/pdf/2025-pers.pdf。