XiaoMi-AI文件搜索系统
World File Search SystemSequence

基于汉密尔顿路径的DNA序列分析方法
有关哈密顿路径的背景信息:汉密尔顿路径的概念来自图理论的数学领域。以爱尔兰数学家和物理学家威廉·罗恩·汉密尔顿(William Rowan Hamilton)的名字命名的汉密尔顿路径,[8]是一条仅访问图中每个顶点的路径[15]。简单地将图形视为节点或顶点的集合,然后用边缘连接这些顶点。汉密尔顿路径是一条以一个顶点开始,精确地访问所有其他顶点,并以另一个顶点结束[1]。它本质上是在整个图表中循环的,而无需重复。哈密顿路径与图理论“哈密顿周期”中的另一个概念密切相关。虽然一条汉密尔顿路径完全访问了每个顶点一次,但不一定要以同一顶点开始和结束,但汉密尔顿圆圈形成了一个封闭环,仅访问每个顶点一次,然后以同一顶点[20]理解和研究汉密尔顿路径在诸如数学,计算机科学和网络分析等各种领域具有重要意义。在这项研究中,我们讨论了Hamiltonian途径在DNA和蛋白质测序中的应用。DNA测序确定DNA分子中核苷酸的顺序[17]。探索哈密顿道路及其特征的重要性有多种理由。1。优化问题的有效性:首先,重要的是要注意,图中的哈密顿路径代表提供最高优化级别的最终路径或序列。这在各种实际应用中具有巨大的价值,例如物流计划,调度,解决旅行者问题以及确定多个位置之间最迅速或最有效的途径。

在全局序列数据集中追踪无脊椎动物疱疹病毒
Malacoherpesviridae的家族目前仅由两种感染软体动物的病毒,Ostreid疱疹病毒1(OSHV-1)和卤素疱疹病毒1(HAHV-1)表示,既导致了水产养殖物种的有害感染。还通过在两栖类药物(分支群瘤物种)和Annelid Worm(Capitella teleta)中的基因组测序项目(Capitella teleta)中检测到类似麦芽菌病毒的序列,这表明水生动物中有隐藏的马拉科植物病毒的多样性存在。在这里,为了扩展有关Malacoherpesvirus多样性的知识,我们在基因组,转录组和元基因组数据集中搜索了Malacoherpesvirus亲戚的存在,包括来自Tara Oceans探险队,并报告了4个新颖的Malacoherpesvirus类基因组(Malacoike Genomes(Malacohemes)(Malacohemes(malacohv1-4))。基因组分析建议腹足动物和双壳类作为这些新的马拉科佩病毒的最可能的宿主。基于家族B DNA聚合酶的系统发育分析分别将新型的MalacoHV1和MalacOHV3作为OSHV-1和HAHV-1的姐妹谱系,而MalacoHV2和MalacOHV4表现出更高的差异。发现与两栖动物相关的病毒基因组与malacohv4相关,形成了Mollusc和Annelid malacoherpesviruse的姊妹进化枝,这表明这两种病毒组合的早期分歧。总而言之,尽管在可用序列数据库中相对较少,但先前未描述的马拉科佩病毒Malacohv1-4在水生生态系统中循环,并且在不断变化的环境条件下应被视为可能是新兴病毒。

在生物序列中用于KNN搜索的神经嵌入
生物序列最近的邻居搜索在生物信息学中起有趣的作用。减轻二次复杂性对常规距离计算的痛苦,神经距离嵌入(将项目序列置于几何空间中)已被公认为是有希望的范式。为了维持序列之间的距离顺序,这些模型所有部署三重态损失并使用直观方法来选择三胞胎的子集,以从广阔的选择空间中进行训练。但是,我们观察到,这种训练通常使模型只能区分一小部分距离顺序,从而使其他人未被认可。此外,天真地选择了更多的三胞胎进行最新的网络下的培训,不仅增加了成本,而且还增加了模型性能。在本文中,我们介绍了Bio-KNN:KNN搜索框架 - 生物序列的工作。它包括一种系统的三重态选择方法和一个多头网络,增强了所有距离订单的识别而不增加培训费用。最初,我们提出了一种基于聚类的方法,将所有三重态分为具有相似支持的几个群集,然后使用创新策略从这些群集中选择三胞胎。同时,我们注意到同一网络中同时培训不同类型的三胞胎无法实现预期的性能,因此我们提出了一个多头网络来解决此问题。我们的网络采用卷积神经网络(CNN)来提取所有群集共享的本地效果,然后分别学习一个分别为每个群集学习多层启示(MLP)头。此外,我们将CNN视为特殊的头部,从而将以前模型中忽略的关键特征整合到我们的模型中以获得相似性识别。广泛的实验表明,我们的生物KNN在两个大规模数据集上的最先进方法显着优于而没有增加培训成本。

使用小波和多解决卷积设计序列模型
Gu等。 (2021)。 用结构化状态空间有效地对长序列进行建模。 li等。 (2022)。 是什么使卷积模型在长序列建模上很棒?Gu等。(2021)。用结构化状态空间有效地对长序列进行建模。li等。(2022)。是什么使卷积模型在长序列建模上很棒?

细菌和线粒体超氧化物歧化酶之间的序列同源性
1969 年,人们发现一种以前未知功能的牛红细胞蛋白具有催化超氧化物自由基歧化活性 (1-3)。这种酶,即超氧化物歧化酶,是一种金属蛋白,每分子含有 2 (1.8-2.0) 个铜原子和 2 (1.7-1.9) 个锌原子,分子量为 33,000,由两个大小相同的亚基组成 (4, 5)。从其他真核生物中纯化的铜锌歧化酶在分子量、亚基结构、氨基酸组成、铜锌含量以及对纯化所用的氯仿-乙醇混合物的稳定性方面与牛红细胞歧化酶相似 (2, 3)。细菌来源的酶代表一类独特的超氧化物歧化酶,其每个分子含有 1-2 个锰原子作为金属辅因子,对氯仿-乙醇处理不稳定,其氨基酸组成与铜锌歧化酶明显不同(2、3、6-8)。细菌酶的分子量约为 40,000,每个酶含有两个分子量为 20,000 的亚基。最近又分离出两种超氧化物歧化酶,其稳定性、纯化特性和氨基酸组成与细菌锰歧化酶相似。一种来自鸡肝线粒体(8)的超氧化物歧化酶每个分子含有 2.3 个锰原子,虽然它是四聚体,但其亚基分子量与细菌含锰酶相同。另一种是含有铁(每个分子约 1 个原子)而不是锰的,已从大肠杆菌中分离出来(9),是一种二聚体,其亚基大小相同(分子量 19,000)。已在各种需氧、厌氧和耐氧厌氧微生物中测量了超氧化物歧化酶活性水平(10)。从观察到的相关性来看,

MotifDb:蛋白质-DNA 结合序列基序的注释集合
tbl.tfClassExample <- data.frame(motifName=c("MA0006.1", "MA0042.2", "MA0043.2"), chrom=c("chr1", "chr1", "chr1"), start=c(1000005, 1000085, 1000105), start=c(1000013, 1000092, 1000123), score=c(0.85, 0.92, 0.98), stringsAsFactors=FALSE) # 这里我们说明如何添加具有所需名称的列:tbl.tfClassExample$shortMotif <- tbl.tfClassExample$motifName tbl.out <- associateTranscriptionFactors(MotifDb, tbl.tfClassExample, source="TFClass", expand.rows=TRUE) dim(tbl.out) # 许多 tfs 已映射,主要是 FOX 家族基因 tbl.motifDbExample <- data.frame(motifName=c("Mmusculus-jaspar2016-Ahr::Arnt-MA0006.1", "Hsapiens-jaspar2016-FOXI1-MA0042.2", "Hsapiens-jaspar2016-HLF-MA0043.2"), chrom=c("chr1", "chr1", "chr1"), start=c(1000005, 1000085, 1000105), start=c(1000013, 1000092, 1000123), score=c(0.85, 0.92, 0.98),字符串因子=FALSE)

编辑:序列的差分分析读取计数数据...
EDGER作者始终感谢接收软件包功能或文档中的错误报告。对于改进的精心考虑的建议也是如此。有关EDGER的所有其他问题或问题都应发布到生物导体支持网站https://support.bioconductor.org。请向支持网站发送一般帮助和建议的请求,而不是向个人作者发送。将问题发布到生物导体支持站点具有许多优势。首先,支持网站包括一个经验丰富的Edger用户社区,他们可以回答最常见的问题。第二,EDGER作者努力确保任何用户发布到生物导体的用户都会获得帮助。第三,支持网站允许其他具有相同问题的人从答案中获得。首次发布到支持网站的用户将发现阅读http://www.bioconductor.org/help/support/posting-guide的发布指南很有帮助。
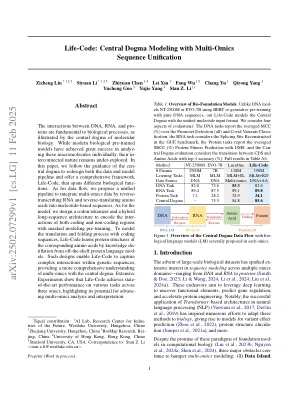
生命代码:具有多词序列统一的中央教条建模
如分子生物学的中心教条所示,DNA,RNA和蛋白之间的相互作用是生物过程的基础。现代生物学预训练的模型在分析这些大分子方面取得了巨大的成功,但它们的感染性质仍未得到探索。在本文中,我们遵循Central Dogma的指导来重新设计数据和模型管道,并提供一个全面的框架,即生命代码,这些框架涵盖了不同的生物功能。至于数据流,我们提出了一条统一的管道来通过将RNA转录并反向翻译为基于核苷酸的序列来整合多词数据。至于模型,我们设计了一个密码子令牌和混合长期架构,以用遮罩的建模预训练编码编码和非编码区域的相互作用。通过编码序列对翻译和折叠过程进行建模,生命代码通过从现成的蛋白质语言模型中的知识分离来学习相应的氨基酸的蛋白质结构。这样的设计使生命代码能够在遗传序列中捕获复杂的相互作用,从而更全面地了解了与中央教条的多摩学。广泛的实验表明,生命代码在三个OMIC的各种任务上实现了状态绩效,突出了其进步多摩学分析和解释的潜力。

CRISPR-Cas9 弯曲和扭曲 DNA 来读取其序列
在细菌防御和基因组编辑应用中,CRISPR 相关蛋白 Cas9 搜索数百万个 DNA 碱基对,以定位与原型间隔区相邻基序 (PAM) 相邻的 20 个核苷酸、向导 RNA 互补的靶序列。靶标捕获需要 Cas9 使用未知的 ATP 独立机制在候选序列处解开 DNA。在这里,我们展示了 Cas9 在 PAM 结合时急剧弯曲和下扭转 DNA,从而将 DNA 核苷酸从双链体中翻转并转向向导 RNA 进行序列询问。在询问途径的不同状态下捕获的 Cas9:RNA:DNA 复合物的低温电子显微镜 (EM) 结构以及溶液构象探测表明,整体蛋白质重排伴随着未堆叠的 DNA 铰链的形成。弯曲诱导的碱基翻转解释了如何

高中健康 I 范围和顺序示例
概述 COMAR 13A.04.18.01 要求地方学校系统提供符合州框架的综合健康教育计划。本文件是如何在高中一级课程中满足马里兰州健康教育框架的标准和指标的示例。其中包括 90 节 45 分钟课程的指标和目标。根据《马里兰州注释法典》教育条款 §4-111(a) (1),制定具体课程决定的责任在于地方教育机构。