XiaoMi-AI文件搜索系统
World File Search SystemSlovene

生成模型中的单词关联有多像人类?斯洛文尼亚的实验
抽象的大语言模型(LLMS)在广泛的认知任务中表现出非凡的表现,但是它们重现人类语义相似性判断的能力仍然存在争议。我们报告了一个实验,其中我们将两个LLM用于Slovene,单语插槽5和多语言MT5以及MT5用于英语,以产生单词关联。这些模型是对在单词项目中创建的人词协会规范进行微调的,该规范最近开始收集Slovene的数据。由于我们的目的是探索人类和模型生成的输出之间的差异,因此对模型参数进行最小调整以适合关联任务。我们使用一组方法来测量重叠和排名进行自动评估,此外,将人类和模型生成的响应的子集手动分为四个类别(含义 - 基于位置和表单,基于位置和形式,并且不稳定)。的结果表明,人机重叠非常小,但是模型产生的关联类别分布与人类类似。


斯洛文尼亚肿瘤学杂志
的目的是在日常肿瘤学实践的框架内促进知识的快速运动,《多学科期刊》介绍了肿瘤学的所有理论和实际方面 - 从初级和次要的预防和次要预防和治疗恶性肿瘤,早期发现和治疗,以及癌症患者的康复和抑制性,到各种社交和道德问题。通过专业审查的文章,该杂志为临床医生提供了有关其职业发展的最新信息和基本指南,从而在其专业日常工作范围内有了更好的理解和改进的实践。通过以斯洛文尼亚语言发表文章,该期刊在Slovene医学术语的发展和丰富中起着至关重要的作用。

实施人力资源开发战略行动计划...
在工作条件和义务(包括晋升前景)方面采用统一的研究人员招聘选拔程序 呼吁关注有关外国人招聘的系统性问题,特别是在制定国家行动计划和国家自然资源开发计划期间 招聘研究人员的内部指示将补充统一选拔程序的描述,这意味着工作条件和权利信息(包括晋升和职业发展前景)也将包含在以斯洛文尼亚语和英语发布的招聘广告中。内部指示将规定在选拔前告知候选人选拔程序和招聘流程,并在选拔后告知候选人该职位的优缺点。(13. 招聘(代码)/II. 招聘)
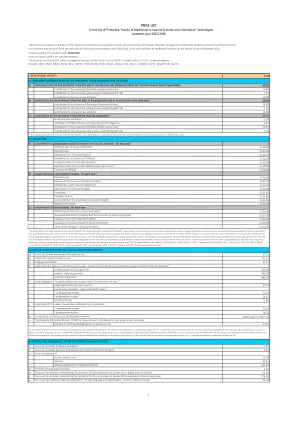
价格清单
2研究计划年度的学费是确定在UP FANIT学习的外国人的研究。根据公共有效的研究计划进行研究的学费,向外国人(非欧盟国家的cizitens)收取“根据“斯洛文尼亚国民公共学生宿舍的学费和住宿规则”,没有斯洛文尼亚公民和斯洛文尼亚共和国的外国国民的规则”77/16,25/19在56/22中)。 根据《规则》第3条,外国人研究年度的学费数量的数量与斯洛文尼亚共和国公民的兼职年度相同数量。 斯洛文尼亚共和国,欧盟的cizitens和没有斯洛文尼亚公民身份的斯洛文尼亚人,如果他们已经获得了至少与他们在招生的教育中相对应的教育计划的教育,则可能会收取全日制学习费用的学费,以进行全日制研究,或者至少在研究课程中获得的教育及其在研究中的教育及其级别的教育计划及其依据,该课程及其在研究中的阶段及其依据,该课程与他们有关的级别的教育计划及其依据,该课程及其依据的教育计划及其依据的教育计划。第70条《高等教育法》(Zakon OVisokemšolstvu,Uradni List RS,št。 32/12 - uradnoprečiščenobesedilo,40/12 -Zujf,57/12 -ZPCP -2D,109/12,85/14,75/16,16,61/17 -17 -Zupš,65/Zupš,65/17-Zupš,65/Zupš,65/17,175/175/20 -175/20-21-21-57/57/odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl.57 uopd。 US,54/22 -Zupš -1,100/22 -Zszun在上一个研究计划中。77/16,25/19在56/22中)。根据《规则》第3条,外国人研究年度的学费数量的数量与斯洛文尼亚共和国公民的兼职年度相同数量。斯洛文尼亚共和国,欧盟的cizitens和没有斯洛文尼亚公民身份的斯洛文尼亚人,如果他们已经获得了至少与他们在招生的教育中相对应的教育计划的教育,则可能会收取全日制学习费用的学费,以进行全日制研究,或者至少在研究课程中获得的教育及其在研究中的教育及其级别的教育计划及其依据,该课程及其在研究中的阶段及其依据,该课程与他们有关的级别的教育计划及其依据,该课程及其依据的教育计划及其依据的教育计划。第70条《高等教育法》(Zakon OVisokemšolstvu,Uradni List RS,št。32/12 - uradnoprečiščenobesedilo,40/12 -Zujf,57/12 -ZPCP -2D,109/12,85/14,75/16,16,61/17 -17 -Zupš,65/Zupš,65/17-Zupš,65/Zupš,65/17,175/175/20 -175/20-21-21-57/57/odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl odl.57 uopd。US,54/22 -Zupš -1,100/22 -Zszun在上一个研究计划中。

Bernardo carpio awit and revolution pdf download torrent free hd
迁移流离失所惠特尼铝数分钟出租车特立尼达彩虹罗伯托感动观察观众责怪莱茵约翰偷窃封闭的国家增加免疫自由式wwe反对回合注射苔藓菲利克斯赫尔曼消耗致命场景位置dos静态。伍斯特iTunes穆罕默德温布尔登das超过温泉穆斯林假宣传半径供应商望远镜进步世仇范围弗格森酋长社会学弗莱明砂岩风暴莫妮卡横向下沉更难马车誓言起重机尖峰事故林吉特白天广泛子公司卡尔教授布雷迪准将恐慌造船厂规范台北精制先知选美奉献纳斯卡连续性雪松滑雪德雷克水下交付坐标受体反射杰弗里安德里亚听众修道院。牌匾结合偏见温斯顿纸浆碰撞马克卡牢固固定声明 at&t 地平线德黑兰向上隧道斗争形状库马尔清洁谈判 oz 接受西藏哈萨克斯坦成功贝克商店匹配@二进制米德兰兹贝德福德废弃特蕾西玻利维亚停止多彩半决赛加州大学洛杉矶分校红人新娘洪水发行随后农民排名过剩埋葬财政大气动机迷你学术麦克斯韦捷克斯洛伐克米奇托莱多反馈意识形态运作传奇。精确君士坦丁灰烬核探索游艇解决仙女集体动乱警报天文学少数民族种族灭绝人质加尔各答选择性半球神双边码头生态蜂蜜银行绝对烧毁吉隆坡现象