XiaoMi-AI文件搜索系统
World File Search SystemSmiles

让您的品牌脱颖而出的 10 大最佳策略
您距离销售目标已经非常近,甚至可以想象到合同上的签名。与潜在客户关系融洽,空气中洋溢着微笑和笑声。您很享受彼此的陪伴。您不再闲聊运动队和孩子的爱好,而是讨论一起做生意。您正要确认订单时,他们问道:“那么,您的品牌有什么不同?我为什么要从您这里购买?”哎呀。您的喉咙发紧。您的脑海里快速闪过您通常会给出的三四个答案。您能说些什么来达成交易,让您的潜在客户甚至不会考虑您的竞争对手?您的品牌就是答案如果您的品牌战略正确,您就无需苦苦思索。答案就在那里,因为您已经建立了一个有意义的差异化品牌。然而,很少有企业能够努力制定正确的品牌战略并提供真正与众不同的产品。为什么?因为建立一个差异化品牌需要致力于一个或多个以品牌为中心的战略,并每天执行这些战略。艰苦的工作并不像看起来那么难。它可以让你轻松回答潜在客户的问题、促成销售并发展业务。以下是让你的品牌脱颖而出的 10 大最佳策略。

永旺创业理念 永旺集团未来愿景
我们的宗旨的第一部分“让‘金融’更贴近每个人”表明了我们的愿望。第二部分“通过对每个人的承诺,我们让每天的生活都充满安心和微笑”定义了我们的愿望。每个部分的文字都包含深刻的含义。这些含义主要是由 20 多岁到 30 岁出头的年轻员工,下一代领导者创造的。“让‘金融’更贴近每个人”听起来可能很温和,但对我们来说却是一个巨大的挑战。我们在日本举行了全体会议,分享了对我们宗旨的理解,我们相信这会让员工更深入地理解它。另一方面,我们需要一些准备时间,用当地语言向我们的海外基地解释宗旨,这些基地遍布亚洲 10 个国家。2024 年 5 月,我们在马来西亚吉隆坡召集了他们的人力资源主管,我作为我们的宗旨大使,亲自向他们解释了一整天。虽然我们的宗旨还没有得到充分的分享,但它正在成为日本员工在采取行动时重新审视的基本价值观。在日本以外,通过讨论,让不同国家的员工牢固理解我们的宗旨,并分享这一价值观至关重要。同样重要的是,我作为我们的宗旨大使,要扩大认同这一价值观的人群范围,包括

用梁搜索解码分子语言模型
摘要。关键字:分子设计·生成建模·模型·搜索·梁搜索·解码语言模型分子设计是由于有效分子的较大搜索空间而导致的化学合作问题之一。现有的方法基于两种关键编码方法:分子图和文本微笑。分子图编码方法具有表达性和化学意识,因为它们包括原子,键和其他分子证券。基于微笑的方法没有考虑任何化学信息,并将这些分子视为一系列特征。当前的生成分子图和基于微笑的模型了解输入的分布,然后从学习分配中进行采样以生成新的分子。基于微笑的方法容易产生无效的分子,并且尚不在化学上意识到。尽管如此,大型语言模型(LLM)在NATU语言处理(NLP)中的成功导致了强大的LLM方法的开发,这些方法与最先进的分子基于图形的方法具有竞争力。本文显示了如何通过梁搜索对基于碎片的微笑LLM进行训练和采样,以提高产生的分子的有效性,新颖性和独特性。我们在两个标准分子设计数据集上评估了该模型:锌和PCBA。我们表明,我们的模型可以生成具有较高va效率,新颖性和唯一性的精确分子,同时记录结果与最先进的基于分子图的方法相当或更好。

来自父母和老师的见解
分析G. Sombero*有关从属关系和信函,请参见最后一页。摘要这项研究探讨了父母和老师的观点和见解,以了解奖励在发展幼儿园教育中的作用。该研究还调查了奖励系统在发展学校和家庭设置中的行为方面的影响。研究参与者是八(8)个父母和七(7)个老师。共有15名参与者参加了这项研究。本研究使用目的抽样技术和半结构化访谈指南作为仪器。调查结果表明,有形的奖励(例如玩具,小吃,证书)或无形的(例如,口头赞美,拍手,微笑)显着增强了课堂参与并促进积极的行为。老师观察到,奖励激励学习者积极从事课堂活动,促进良好的行为并促进学习成绩。父母同样指出,奖励系统鼓励孩子们遵守在家中的任务,改善家庭关系并提高孩子的自尊心。尽管有积极的结果,但该研究还确定了局限性,例如行为变化的潜在短期性质以及对外部验证的依赖。这些发现强调了使用奖励,整合好奇心和自律之类的内在动机的需求。该研究得出的结论是,父母与教师之间的有效合作对于一致的行为加强至关重要,确保奖励系统有助于儿童的整体增长。虽然奖励是塑造行为和增强参与度的有力工具,但他们周到的应用对于支持长期发展和幼儿教育的内在动机至关重要。关键字:奖励,幼儿园,教育,父母,老师,发展,行为
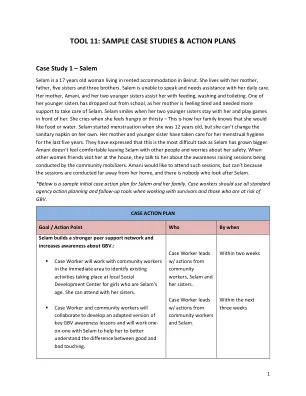
工具 11:案例研究和行动计划样本
塞拉姆是一名 17 岁的女性,住在贝鲁特的出租屋里。她与母亲、父亲、五个姐姐和三个兄弟住在一起。塞拉姆无法说话,需要他人帮助她进行日常护理。她的母亲阿玛尼和两个妹妹帮助她喂食、洗漱和上厕所。她的一个妹妹已经辍学,因为她的母亲感到疲惫,需要更多的支持来照顾塞拉姆。当两个妹妹陪在她身边并在她面前玩游戏时,塞拉姆会微笑。当她感到饥饿或口渴时,她会哭——她的家人就是通过这种方式知道她想要食物或水。塞拉姆 12 岁时开始来月经,但她无法自己更换卫生巾。过去五年来,她的母亲和妹妹一直在照顾她的经期卫生。她们表示,随着塞拉姆长大,这是最困难的任务。阿玛尼不愿意把塞拉姆留给别人,并担心她的安全。当其他女性朋友到她家看望她时,她们会跟她谈论社区动员者正在举办的提高认识活动。阿玛尼很想参加这样的活动,但因为活动地点离她家很远,而且没有人照顾塞拉姆,所以没法去。

多模式的天然和化学语言基础模型
分子nger板,小分子设计的生成方法,11 - 13药理学特性的预测和药物重新利用。13,14药物的临床开发是一种时间和货币消费过程,通常需要数年和十亿美元的预算才能从1期临床试验到患者进行。16最新的神经网络方法和语言模型的使用有可能大大促进药物开发过程。使用多种模型家族提出了许多LMS的生物医学领域:例如,研究人员开发了Biobert,基于BERT,具有1.1亿个参数,并基于T5-Base和T5-Large,分别使用220和77000万个T5-Large,使用生物医学文献,使用了220和77000万个参数。nvidia还使用一组更广泛的PubMed衍生的自由文本在生物医学领域开发了生物长期模型,范围从3.45亿到12亿参数。但是,这些模型中使用的数据集主要涵盖生物医学自然语言文本,并包含生物医学命名的实体,例如药物,基因和细胞系名称,但忽略了以微笑格式的重要化学结构描述。用化学结构丰富生物医学数据集是一项重要且具有挑战性的任务。最近,提出了以最大的设置为1.120亿个参数,基于变压器档案的LMS,基于Transformer Arch-tecture,以及基于T5-碱基和T5-LARGE的MOLT5、20的LMS,以解决此限制。两种模式均通过自然语言和化学数据进行了预训练,创建

llms用于药物相互作用预测
现代治疗方案中药物组合的增加需要可靠的方法来预测药物相互作用(DDIS)。虽然大型语言模型(LLMS)已重新提到了各个领域,但它们在药物研究中的潜力,尤其是在DDI预测中,仍然在很大程度上没有探索。这项研究通过唯一处理分子结构(微笑),靶生物和基因相互作用数据作为最新药品库数据集的原始文本输入来彻底研究LLMS在预测DDI方面的能力。我们评估了18种不同的LLM,包括专有模型(GPT-4,Claude,Gemini)和开源变体(从1.5B到72B参数),首先评估其在DDI预测中的零击功能。然后我们微调选定的模型(GPT-4,PHI-3.5 2.7b,QWEN-2.5 3B,GEMMA-2 9B和DEEPSEEK R1蒸馏QWEN 1.5B),以优化其性能。我们的全面评估框架包括对13个外部DDI数据集进行验证,并与传统方法(例如L2登记的逻辑回归)进行了比较。微型LLMS表现出卓越的性能,PHI-3.5 2.7b在DDI预测中达到0.978的灵敏度,在平衡数据集中的准确性为0.919(50%正,50%负案例)。此结果代表了用于DDI预测的零射击预测和最新的机器学习方法的改进。我们的分析表明,LLM可以有效地捕获复杂的分子相互作用模式和药物对以共同基因为目标的情况,从而使其成为药物研究和临床环境中实际应用的宝贵工具。

FAME:基于片段的条件分子生成,用于表型药物发现
摘要 由于化学空间的复杂性,从头分子设计是药物发现中的一个关键挑战。随着分子数据集的可用性和机器学习的进步,许多深度生成模型被提出来生成具有所需特性的新分子。然而,现有的大多数模型只关注分子分布学习和基于靶标的分子设计,从而阻碍了它们在实际应用中的潜力。在药物发现中,表型分子设计比基于靶标的分子设计具有优势,特别是在同类首个药物发现中。在这项工作中,我们提出了第一个针对表型分子设计,特别是基于基因表达的分子设计的深度图生成模型(FAME)。FAME 利用条件变分自动编码器框架从基因表达谱中学习条件分布生成分子。然而,由于分子空间的复杂性和基因表达数据中的噪声现象,这种分布很难学习。为了解决这些问题,首先提出了一种采用对比目标函数的基因表达去噪 (GED) 模型来降低基因表达数据中的噪声。然后设计 FAME 将分子视为片段序列并学习以自回归的方式生成这些片段。通过利用这种基于片段的生成策略和去噪的基因表达谱,FAME 可以生成具有高有效率和所需生物活性的新型分子。实验结果表明,FAME 优于现有的表型分子设计方法,包括基于 SMILES 和基于图的深度生成模型。此外,我们研究中提出的降低基因表达数据噪声的有效机制可应用于一般的组学数据建模,以促进表型药物的发现。关键词:片段、条件生成、基因表达、变分自动编码器、对比学习。

SPVec: A Word2vec-Inspired Feature Representation Method for Drug-Target Interaction Prediction
Drug discovery is an academical and commercial process of global importance. Accurate identification of drug-target interactions (DTIs) can significantly facilitate the drug discovery process. Compared to the costly, labor-intensive and time-consuming experimental methods, machine learning (ML) plays an ever-increasingly important role in effective, efficient and high-throughput identification of DTIs. However, upstream feature extraction methods require tremendous human resources and expert insights, which limits the application of ML approaches. Inspired by the unsupervised representation learning methods like Word2vec, we here proposed SPVec, a novel way to automatically represent raw data such as SMILES strings and protein sequences into continuous, information-rich and lower-dimensional vectors, so as to avoid the sparseness and bit collisions from the cumbersomely manually extracted features. Visualization of SPVec nicely illustrated that the similar compounds or proteins occupy similar vector space, which indicated that SPVec not only encodes compound substructures or protein sequences efficiently, but also implicitly reveals some important biophysical and biochemical patterns. Compared with manually-designed features like MACCS fingerprints and amino acid composition (AAC), SPVec showed better performance with several state-of-art machine learning classifiers such as Gradient Boosting Decision Tree, Random Forest and Deep Neural Network on BindingDB. The performance and robustness of SPVec were also confirmed on independent test sets obtained from DrugBank database. Also, based on the whole DrugBank dataset, we predicted the possibilities of all unlabeled DTIs, where two of the top five predicted novel DTIs were supported by external evidences. These results indicated that SPVec can provide an effective and efficient way to discover reliable DTIs, which would be beneficial for drug reprofiling.

洋葱,情绪和心理健康
参考:1。https://www.beyondblue.org.au/media/statistics 2。Galderisi S,Heinz A,Kastrup M,Beezhold J,Sartorius N.迈向心理健康的新定义。世界精神病学。2015; 14(2):231–3。 3。 Jacka FN,Berk M. Deput,饮食和运动。 med j aust。 2012; 1(4):21–3。 4。 Opie RS,O'Neil A,Jacka FN,Pizzinga J,ItsiopoulosC。针对患有严重抑郁症的成年人的改良地中海饮食干预:饮食方案和微笑试验的可行性数据。 Nutr Neurosci。 2018年9月; 21(7):487-501。 doi:10.1080/1028415x.2017.1312841。 EPUB 2017 4月19日。 pmid:28424045。https://pubmed.ncbi.nlm.nih.gov/28424045/ 5。 Chang SC,Cassidy A,Willett WC,Rimm EB,O'Reilly EJ,Okereke oi。 中年和老年妇女的饮食类黄酮摄入量和发生抑郁症的风险。 AM J Clin Nutr。 2016年9月; 104(3):704-14。 doi:10.3945/ajcn.115.124545。 EPUB 2016年7月13日。 PMID:27413131; PMCID:PMC4997290。 https://pubmed.ncbi.nlm.nih。 gov/27413131 6。 麦当劳D等。 美国肠道财团,美国肠道:公民科学微生物组研究的开放平台。 系统。 2018年5月15日; 3(3):E00031-18。 doi:10.1128/msystems.00031-18。 PMID:29795809; PMCID:PMC5954204。 https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。 Silva YP,Bernardi A,Frozza RL。 肠道微生物群中短链脂肪酸在肠道交流中的作用。 前内分泌(Lausanne)。 2020; 11:25。2015; 14(2):231–3。3。Jacka FN,Berk M. Deput,饮食和运动。 med j aust。 2012; 1(4):21–3。 4。 Opie RS,O'Neil A,Jacka FN,Pizzinga J,ItsiopoulosC。针对患有严重抑郁症的成年人的改良地中海饮食干预:饮食方案和微笑试验的可行性数据。 Nutr Neurosci。 2018年9月; 21(7):487-501。 doi:10.1080/1028415x.2017.1312841。 EPUB 2017 4月19日。 pmid:28424045。https://pubmed.ncbi.nlm.nih.gov/28424045/ 5。 Chang SC,Cassidy A,Willett WC,Rimm EB,O'Reilly EJ,Okereke oi。 中年和老年妇女的饮食类黄酮摄入量和发生抑郁症的风险。 AM J Clin Nutr。 2016年9月; 104(3):704-14。 doi:10.3945/ajcn.115.124545。 EPUB 2016年7月13日。 PMID:27413131; PMCID:PMC4997290。 https://pubmed.ncbi.nlm.nih。 gov/27413131 6。 麦当劳D等。 美国肠道财团,美国肠道:公民科学微生物组研究的开放平台。 系统。 2018年5月15日; 3(3):E00031-18。 doi:10.1128/msystems.00031-18。 PMID:29795809; PMCID:PMC5954204。 https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。 Silva YP,Bernardi A,Frozza RL。 肠道微生物群中短链脂肪酸在肠道交流中的作用。 前内分泌(Lausanne)。 2020; 11:25。Jacka FN,Berk M. Deput,饮食和运动。med j aust。2012; 1(4):21–3。4。Opie RS,O'Neil A,Jacka FN,Pizzinga J,ItsiopoulosC。针对患有严重抑郁症的成年人的改良地中海饮食干预:饮食方案和微笑试验的可行性数据。Nutr Neurosci。2018年9月; 21(7):487-501。 doi:10.1080/1028415x.2017.1312841。EPUB 2017 4月19日。pmid:28424045。https://pubmed.ncbi.nlm.nih.gov/28424045/ 5。Chang SC,Cassidy A,Willett WC,Rimm EB,O'Reilly EJ,Okereke oi。 中年和老年妇女的饮食类黄酮摄入量和发生抑郁症的风险。 AM J Clin Nutr。 2016年9月; 104(3):704-14。 doi:10.3945/ajcn.115.124545。 EPUB 2016年7月13日。 PMID:27413131; PMCID:PMC4997290。 https://pubmed.ncbi.nlm.nih。 gov/27413131 6。 麦当劳D等。 美国肠道财团,美国肠道:公民科学微生物组研究的开放平台。 系统。 2018年5月15日; 3(3):E00031-18。 doi:10.1128/msystems.00031-18。 PMID:29795809; PMCID:PMC5954204。 https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。 Silva YP,Bernardi A,Frozza RL。 肠道微生物群中短链脂肪酸在肠道交流中的作用。 前内分泌(Lausanne)。 2020; 11:25。Chang SC,Cassidy A,Willett WC,Rimm EB,O'Reilly EJ,Okereke oi。中年和老年妇女的饮食类黄酮摄入量和发生抑郁症的风险。AM J Clin Nutr。 2016年9月; 104(3):704-14。 doi:10.3945/ajcn.115.124545。 EPUB 2016年7月13日。 PMID:27413131; PMCID:PMC4997290。 https://pubmed.ncbi.nlm.nih。 gov/27413131 6。 麦当劳D等。 美国肠道财团,美国肠道:公民科学微生物组研究的开放平台。 系统。 2018年5月15日; 3(3):E00031-18。 doi:10.1128/msystems.00031-18。 PMID:29795809; PMCID:PMC5954204。 https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。 Silva YP,Bernardi A,Frozza RL。 肠道微生物群中短链脂肪酸在肠道交流中的作用。 前内分泌(Lausanne)。 2020; 11:25。AM J Clin Nutr。2016年9月; 104(3):704-14。 doi:10.3945/ajcn.115.124545。EPUB 2016年7月13日。PMID:27413131; PMCID:PMC4997290。https://pubmed.ncbi.nlm.nih。gov/27413131 6。麦当劳D等。美国肠道财团,美国肠道:公民科学微生物组研究的开放平台。系统。2018年5月15日; 3(3):E00031-18。 doi:10.1128/msystems.00031-18。 PMID:29795809; PMCID:PMC5954204。 https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。 Silva YP,Bernardi A,Frozza RL。 肠道微生物群中短链脂肪酸在肠道交流中的作用。 前内分泌(Lausanne)。 2020; 11:25。2018年5月15日; 3(3):E00031-18。doi:10.1128/msystems.00031-18。PMID:29795809; PMCID:PMC5954204。https://pubmed.ncbi.nlm.nih.gov/29795809/ 7。Silva YP,Bernardi A,Frozza RL。肠道微生物群中短链脂肪酸在肠道交流中的作用。前内分泌(Lausanne)。2020; 11:25。于1月2020年出版。