XiaoMi-AI文件搜索系统
World File Search SystemTechnique

一种优化的经验技术...
介绍。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。16 波反射.........• , .。。。。。。。。。。。。。。。。。。。。。。。。。16 穿孔墙概念 • • .• • • • • • • • • • • • • • • • • • • • • • • • • • • • • • 18 模型尺寸标准。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。19 部分开放墙壁的波反射••••••.。。• 。。20 波浪消除。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21 斜孔对波反射的影响••••••••••24 壁厚的影响。• • • • • • • • • • • • • • • • • 。• • 。• 。• • • • • • 27 孔尺寸要求。。• 。• • • • • • • • • • 。• • • • • • • • • • • • • • • • 30 边界层对波反射的影响• • • .• • • 33 总结备注......... , .。• • • • • • 31 墙面收敛和发散 • • • • • • • • • • • • • • • • • .....................。。34

手术技术手册
[1] Michael DR, MD,《无骨水泥髋臼杯的演变回顾》,ORTHOSuperSite,2008 年 12 月 1 日。[2] Medacta 文件中的数据。[3] YK Lee、KC Kim、WL Jo、YC Ha、J. Parvizi、KH Koo。髋臼金属壳内锥角对陶瓷内衬的错位力和分离力的影响。《关节成形术杂志》2017 年 4 月;32(4):1360-1362。[4] YK Lee、JY Lim、YC Ha、TY Kim、WH Jung、KH Koo。预防 Delta 陶瓷对陶瓷全髋关节置换术后陶瓷内衬断裂。《骨科与创伤外科档案》2021 年 7 月;141(7):1155-1162。 [5] L. Dall'Ava、H. Hothi、J. Henckel、A. Di Laura、P. Shearing、A. Hart。当前 3D 打印髋臼钛植入物的比较分析。3D 打印医学 2019;5:15。[6] P. Robotti、A. Sabbioni、L. Glass、B. George,《热等离子喷涂大孔钛涂层》,ITSC 2013,国际热喷涂会议,2013 年 5 月 13 日至 15 日,韩国釜山。[7] JE Biemond 等人,《3 维电子束产生的植入物表面骨长入潜力的体内评估以及酸蚀和羟基磷灰石涂层等附加处理的效果》,J. Biomat。 Appl,2011 年 1 月 27 日在线发表,0885328210391495。[8] R. Ferro de Godoy 等人,通过创新粉末冶金方法制造的钛大孔结构的体内评估。eCM XIII 论文集:骨固定、修复和再生,2012 年 6 月 24-26 日,瑞士达沃斯。[9] A. Goodship 等人,通过放电等离子烧结产生的工程表面拓扑结构的体内生长潜力评估,第 9 届世界生物材料大会论文集,2012 年 6 月 1-5 日,中国成都。



FICHE技术生物肥料
近年来,使用有机添加剂,活跃的天然代谢产物或有用的微生物是讨论的主题,作为一种更耐用的植物生产的生态策略。我们观察到全世界对微生物接种剂的兴趣及其与植物相互作用的有针对性使用。有用的微生物确实可以通过增加对土壤和环境不利条件的耐受性或改善其养分储存能力来促进植物的生长。每当特定微生物接种物的开发(称为生物肥料)具有有益作用非常困难。特别是挑战之一是农业应用与各种精神环境条件之间的适当性。目前销售的一些BI施用者的质量较差,或者其应用很复杂。如此多的缺点导致农民和农民的信心丧失。尽管如此,提高微生物配方的质量以及理解生物学机制的进展已逐渐提高该领域的应用程序的盈利能力。此表总结了该领域的研究最新进展。



Greenlight 技术聚焦
GreenLight ™ 激光系统用于软组织的切开/切除、汽化、消融、止血和凝固,包括针对良性前列腺增生 (BPH) 的前列腺光选择性汽化。激光系统禁用于以下患者:不适合手术、因患者病史而禁用适当麻醉、组织钙化、需要在 >2 毫米血管中止血、有无法控制的出血性疾病、患有前列腺癌、患有急性尿路感染 (UTI) 或严重尿道狭窄。可能的风险和并发症包括但不限于刺激症状(排尿困难、尿急、尿频)、逆行射精、尿失禁、勃起功能障碍、肉眼血尿、尿路感染、膀胱颈挛缩/出口阻塞、尿潴留、前列腺穿孔、尿道狭窄。
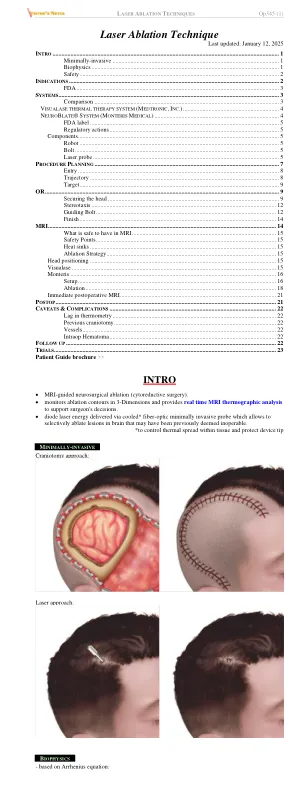
激光消融技术
What is safe to have in MRI ................................................................................................ 15 Safety Points ........................................................................................................................ 15 Heat sinks ............................................................................................................................ 15 Ablation Strategy ................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................. ......................................................................................................................................... 16

清洁针技术
清洁针技术(CNT)手册旨在主要由国家许可的针灸师和学生在学校批准的针灸和草药认证委员会批准的学校中的正式教学课程中使用。作为有关针灸针刺和相关技术的最佳实践的说法,该手册也可以由国家执照的医疗保健专业人员在其他学科中的医疗保健专业人员中有益地使用,这些专业人员在其合法实践范围内以及在美国以外的针刺范围内具有适当授权在其范围内具有适当律师的针刺范围内的针灸和相关方式来实践各自的国家法官。该手册不打算在未经正规培训和监管授权的情况下使用以实践针灸。手册侧重于安全性,不是针对特定健康状况的适当治疗的指南。手册旨在反映出版日期的最佳实践,但关于最佳实践的看法可能会有所不同,并且会随着时间而变化。鼓励正在进行的有关学术和从业者社区中最佳实践的研究和辩论。理事会对于由于从业人员使用或依赖本手册中包含的任何安全协议而可能造成的任何伤害概不负责。