XiaoMi-AI文件搜索系统
World File Search SystemTex

第八届国际会议
在这个半天的教程中,我们将首先介绍可重复研究的概念和重要性。然后,我们将介绍如何使用 R 、 LA TEX 和 Sweave 自动生成统计报告以确保可重复的研究。我们将介绍每个软件组件:R ,用于执行所需统计分析(包括生成图形)的免费交互式编程语言和环境;LA TEX ,用于生成统计报告书面部分的排版系统;Sweave ,用于将 R 代码嵌入到 LaTeX 文档中、编译 R 代码以及将所需输出插入到生成的统计报告中的灵活框架。然后,我们将使用详细示例介绍使用这三个软件组件从头开始生成可重复的统计报告的步骤。我们还将演示在数据或分析发生变化时重新生成报告以及自动更新输出的能力。我们将展示 Sweave 的更多高级用法和自定义功能,以便制作更漂亮的报告并使研究更具可重复性,并讨论 Sweave 和 knitr 之间的差异。此外,本教程将提供实践课程,在此期间将生成和修改实践报告、有用的提示和所需的资源/参考资料。

德克萨斯州侵权索赔法和责任,第2部分法律问答
TML法律服务助理总监Amber McKeon-Mueller Texas Tort索赔法和责任,第2部分法律问答Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q和 a娱乐用途法规通过向公共娱乐目的开放财产的城市等土地所有者提供额外的保护,进一步限制了城市对房屋缺陷的责任。 参见Tex。 civ。 prac。 &rem。 代码§§75.001-.007(娱乐使用法规)。 欠某人使用该市财产进行休闲使用的责任是侵犯侵入者的责任。 id。 §75.002(f)。 (有关涉及侵入者的责任的讨论,请参见第1部分)。 在适用时,法规会通过要求原告建立更高的疏忽标准,称为严重过失或恢复伤害的意图,从而有效地免疫城市免受与该物业娱乐活动相关的普通过失索赔的疫苗接种。 请参阅ID。 §75.002(c) - (d),(f);斯蒂芬·奥斯汀州立大学。 诉Flynn,228 S.W. 3d 653,659(Tex。) 2007)。 该法规仅适用于以下娱乐用途,其通过一系列活动来定义:Texas Tort索赔法和责任,第2部分法律问答Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q和a娱乐用途法规通过向公共娱乐目的开放财产的城市等土地所有者提供额外的保护,进一步限制了城市对房屋缺陷的责任。参见Tex。civ。prac。&rem。代码§§75.001-.007(娱乐使用法规)。欠某人使用该市财产进行休闲使用的责任是侵犯侵入者的责任。id。§75.002(f)。(有关涉及侵入者的责任的讨论,请参见第1部分)。在适用时,法规会通过要求原告建立更高的疏忽标准,称为严重过失或恢复伤害的意图,从而有效地免疫城市免受与该物业娱乐活动相关的普通过失索赔的疫苗接种。请参阅ID。§75.002(c) - (d),(f);斯蒂芬·奥斯汀州立大学。诉Flynn,228 S.W. 3d 653,659(Tex。2007)。 该法规仅适用于以下娱乐用途,其通过一系列活动来定义:2007)。该法规仅适用于以下娱乐用途,其通过一系列活动来定义:
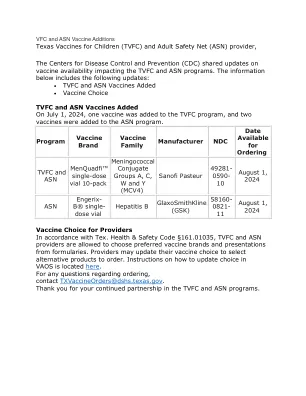
VFC和ASN疫苗添加
根据Tex的提供商选择疫苗。健康与安全法规§161.01035,TVFC和ASN提供商可以从配方中选择首选的疫苗品牌和演示文稿。提供商可以更新其疫苗选择,以选择订购的替代产品。有关如何更新VAO中选择的说明,请参见此处。有关订购的任何问题,请联系txvaccineorders@dshs.texas.gov。感谢您在TVFC和ASN程序中的持续合作伙伴关系。

Victor Gomes
UNDERGRADUATE Psychology of Language, honors Developmental Psychology, honors Philosophy of Language Philosophy of Mind, honors Mind & Metaphor, honors Language & Power Semantics Social Psychology, honors Directed Reading in Cognitive Anthropology SKILLS LANGUAGES Human, native: Portuguese, native • English, native Human, basic skills: • Spanish • French • Italian Machine, familiar: Python • R • JavaScript • L A TEX

Seth Berl – | 博士、文学硕士、理学学士、电气工程学士
操作系统:Microsoft Windows、Linux 和 UNIX、Macintosh、VxWorks 编程语言:C(++)、Python、Perl、LabVIEW、VHDL、HTML、PHP、Javascript、CSS、SQL、LA TEX 架构与协议:ARM、HTTP、USB、OHCI、SCSI、FAT、UART、SPI、I2C 软件:Matlab、Mathematica、AutoCAD 和 Inventor、Adobe Suite、Wireshark、IAR Embedded Workbench 调试:JTAG、J-Link、示波器、逻辑分析仪、内存管理

独立前印度经济的主要特征
在 1947 年印度独立之前,英国统治了印度两个世纪。英国经济政策的主要目标是将印度变成英国现代工业基础扩张的供给经济。独立前,印度经济强劲,主要以农业和手工业为主。纺织品和宝石等田间手工艺品的卓越品质为印度产品赢得了全球市场。

[.AG 323.3 (20 Aug 58) 1 IV •. 美国陆军医学研究与发展司令部。自 1958 年 8 月 20 日起,美国陆军医学研究与发展司令部作为二级活动成立,由将军管辖,位于华盛顿特区
Yll •. 贾斯汀 F. 金博尔高中,得克萨斯州达拉斯。自 1958 年 9 月起,得克萨斯州达拉斯市的贾斯汀 F. 金博尔高中(达拉斯独立学区)根据美国法典第 10 章第 3540b 和 4651 条的规定,获准参与军事训练计划。该计划将被称为国家国防学员队计划。

织物结构对石墨烯涂层纺织品的电阻的影响
抽象涂层是用于不同目的的纺织行业中广泛的技术,主要是在着色和功能表面上。石墨烯通常使用涂料技术应用于织物,以提供具有导热性或电导率等特性的织物。所有编织织物的结构都有峰值和山谷,由翘曲和纬线交织在一起。在散布石墨烯涂层时,将糊剂放在织物的间隙中,并且只有在涂层的高度足以连接沉积的不同区域时才产生导电颗粒之间的连接。本文分析了三种类型的缎面编织,三个交错系数(0.4、0.25、0.17)和两组纬纱(20和71.43 Tex)。对于1.5毫米的叶片间隙,纬纱计数的样品的电阻为20 tex且交错系数为0.4为534.33Ω,而对于IC = 0.25的0.25电阻高36.8%,对于IC = 0.17,此参数增加了249.3%。对于具有71.43的纬纱计数的样品,IC = 0.40的样品的电阻为1053Ω,对于IC = 0.25,此值升至33.9%,而对于IC = 0.17,电阻值总计增加了78.9%。对于连续性至关重要的涂层,并且需要保护需要保护外部因素的物质,这一发现可能是感兴趣的,对于需要保护的物质,可以将具有深层间隙的织物设计用于容纳所述产品。

如果我只有一个大脑——为机器人建模人工智能
意义和记忆。大脑通常处于高维、无序的“基础”状态,然后,每秒四五次,大脑会立即组织起来,识别熟悉的事物或做出决定。这些是大脑从混沌状态到吸引子的相变。吸引子是一个区域,混沌系统看似随机的“轨迹”聚集在一起——例如,大脑中的海马体或皮层(见下图)。一个区域中的相变和吸引子