XiaoMi-AI文件搜索系统
World File Search SystemVar

通过体外和体内模型对抗炎活性的评估Akshitha Kalwarala 2,Shriya Kumari.J 2,Shivanandu.K 2,Suresh.k 2,var
收到:28-01-2025 /接受了修订:02-02-2025 /发布:07-02-2025摘要:炎症是免疫系统对有害刺激的复杂生物学反应,例如病原体,受损细胞或刺激性。慢性炎症与各种疾病有关,包括自身免疫性疾病,心血管疾病和癌症。抗炎药旨在调节或抑制炎症,从而提供治疗益处。本文探讨了用于研究抗炎机制的体内和体外模型,并评估潜在抗炎药的功效。体外模型,例如细胞培养物和细胞因子测定,提供了控制特定分子和细胞途径的受控环境。相比之下,包括动物研究在内的体内模型,提供了对系统性反应和药代动力学的见解。对这些模型的全面理解对于开发有效的抗炎疗法至关重要。本评论重点介绍了体内和体外方法的优点,局限性和应用,为临床前研究中选择适当的模型提供了一个框架。关键词:炎症,细胞因子测定,体外和体内模型。

与化学施肥相比,真菌 - 细菌生物膜,堆肥和LOF的潜力在支持Pakcoi(Brassica rapa rapa var chinensis)
Abltrak。过多的化肥可以增加碳排放量并加速土地退化。要克服这一挑战,需要缓解努力,例如使用生物膜形成的微生物减少蒸发和家庭废物作为堆肥和液体有机肥料,以提高土壤降解的土壤质量。这项研究旨在确定生物膜生物肥料,堆肥和液体有机肥料(LOF)对Pakcoi植物生长的影响。This study used a three-factor (fertilizer type, inorganic fertilizer doses, and organic fertilizer doses) with a Complete Group Randomized Design with 14 treatments (N0: Control, N1: 100 % NPK + 0 Organic fertilizer, NB 2: 75% NPK + 25% BFBF, NB 3: 50% NPK + 50% BFBF, NB 4: 25 % NPK + 75% BFBF,NB 5:0%NPK + 100%BFBF,NP 2:75%NPK + 25%LOF,NP 3:50%NPK + 50%LOF,NP 4:25%NPK + 75%LOF,NP 5:0 25%NPK + 75%堆肥,NR 5:0%NPK + 100%堆肥)。这项研究中的观察参数包括植物高度,叶子数量和宽度。数据分析是使用ANOVA进行的,并继续使用DMRT进行。结果表明,与对照相比,Pakchoi植物的50%NPK + 50%生物肥料治疗可以增加植物的身高,叶片宽度和新鲜重量,而100%LOF的叶子数量比对照组高16,69%。这些发现通过减少有助于碳排放的化肥,同时采用可持续的农业实践,利用生物膜和有机材料来提高生产力,同时维持生态系统健康,从而支持气候变化策略。

新闻、不可逆性和结构 VAR - 巴黎圣母院网站
线性化 DSGE 模型的状态空间表示意味着以可观测变量表示的 VAR。如果 VAR 创新不存在可以恢复经济冲击的线性旋转,则称该模型为不可逆。当观测变量不能完美地揭示模型的状态变量时,就会出现不可逆性。对状态的不完美观测会在 VAR 创新和深度冲击之间产生隔阂,可能使从 VAR 的结构脉冲响应分析中得出的结论失效。本文的主要贡献是表明不可逆性不应被视为“非此即彼”的命题——即使模型具有不可逆性,VAR 创新和经济冲击之间的隔阂可能很小,而结构 VAR 仍可能表现可靠。一个越来越流行的例子是,所谓的“新闻冲击”会产生对未来基本面变化的预见——比如生产力、税收或政府支出——并导致无懈可击的缺失状态变量问题,从而产生不可逆的 VAR 表示。来自一个中等规模 DSGE 模型的模拟证据表明,尽管存在已知的不可逆性,但结构 VAR 方法在实践中往往表现良好。从 VAR 获得的脉冲响应与模型的理论响应紧密相关,并且估计的 VAR 响应能够成功区分底层 DSGE 模型的替代嵌套规范。由于不可逆性问题本质上是缺失信息问题,因此以更多信息为条件(例如通过因子增强 VAR)可以改善或完全消除可逆性问题。

CRISPR 干扰克隆变异的富含 GC 的非编码 RNA 家族,导致恶性疟原虫中 var 基因普遍受到抑制
摘要 人类疟原虫恶性疟原虫利用 PfEMP1 编码 var 基因家族的互斥表达来逃避宿主免疫系统。尽管在分子层面上对默认沉默机制的理解取得了进展,但独特表达的 var 成员的激活机制仍然难以捉摸。富含 GC 的非编码 RNA (ncRNA) 基因家族与表达 var 基因的疟原虫物种共同进化。在这里,我们表明这个 ncRNA 家族以克隆变异的方式转录,当 ncRNA 位于活性 var 基因相邻和上游时,单个成员的主要转录发生。我们开发了一种特定的 CRISPR 干扰 (CRISPRi) 策略,可以抑制所有富含 GC 的成员的转录。缺乏富含 GC 的 ncRNA 转录导致环状期寄生虫中整个 var 基因家族的下调。令人惊讶的是,在成熟的血液阶段寄生虫中,富含 GC 的 ncRNA CRISPRi 影响了其他克隆变异基因家族的转录模式,包括所有 Pfmc-2TM 成员的下调。我们为富含 GC 的 ncRNA 转录在 var 基因激活中的关键作用提供了证据,并发现了与寄生虫毒力有关的各种克隆变异多基因家族的转录控制之间的分子联系。这项工作为阐明控制恶性疟原虫免疫逃避和发病机制的分子过程开辟了新途径。

使用培养 - 哥伦比亚贾丁(Jardín
背景:温和的哥伦比亚咖啡因其高质量的咖啡杯而在全球范围内被认可。但是,收获后的做法(例如咖啡谷物发酵)出现了一些失败。这些失败有时可能导致优质产品的缺陷和不一致的咖啡农。在哥伦比亚,咖啡种植者最常使用的发酵方法之一是湿发酵,通过浸入de粉的咖啡豆在水箱中足够的时间进行进行湿法发酵,以去除粘液。目标:我们评估了水(G)/de粉咖啡(G)比率(I:0/25,II:10/25,III:20/25)和最终发酵时间(24、48和72小时)对微生物组总数。我们还确定了感兴趣的微生物是起始培养物。方法:我们使用了一个完全随机的实验设计,其中有两个因素。水(g)/de粉咖啡(g)比(i:0/25,ii:10/25,iii:20/25)和最终发酵时间(24、48和72小时)的影响,用于两种重复。在咖啡发酵(1,950 g)期间,监测pH和°brix。进行了不同微生物基(中粒,大肠菌群,乳酸细菌,乙酸酸性细菌和酵母)的总数。使用分子测序技术鉴定出各种感兴趣的微生物作为起始培养物(乳酸细菌和酵母)。结果:从不同的微型批次发酵系统中获得了21种乳酸细菌(实验室)分离株和22种酵母菌。pichia kluivery(39%)和Torulaspora delbrueckii(22%)是最丰富的酵母菌。发现的最丰富的乳酸细菌是lactiplantibacillus plantarum(46%)和Brevis左旋乳杆菌(31%)。结论所研究的因素对微生物的发展没有影响。所鉴定的细菌和酵母菌物种具有促进培养物的潜力,可用于提高质量咖啡和发酵相关的应用。


植物提取物对Gerbera var中花瓶寿命的影响。 pre intenzz
与Ocimum Sanctum @ 5.0%记录了最长的花瓶寿命(11.00天),CUV为30.82 g天-1,CTL为39.66 G天-1,最小微生物载荷3.15 CFU×10 -5。在植物提取物的不同组合中,在花瓶溶液中含有t 3(Mentha viridis @ 5.0% +Ocimum Sanctum @ 5.0%)的花瓶寿命为9.35天,CUV为28.96 g天-1,CTL -1,CTL的29.19 g天-1,新鲜21.58 g -1 -1 c.58 crimiem -1 c.58 c.58 c.58 c.58 c.58 c.58 c.58 c.58 c.58 c。 。在植物提取物对Gerbera Flowers T 2花瓶寿命的影响(5.0%)最适合维持花瓶寿命及其参数,并且与T 16(8 hqs @ 0.8%)相当。t 3(Mentha Viridis @ 5.0% +5.0% @ 5.0%)有效。
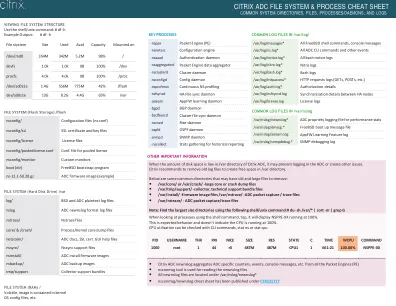
CITRIX ADC 文件系统和流程备忘单
以下是一些可能需要删除的旧文件和大文件常用目录: • /var/core/ 或 /var/crash/ - 大核心或崩溃转储文件 • /var/tmp/support/ - 收集器,技术支持包文件 • /var/install/ - 固件映像文件 /var/nstrace/ - ADC 数据包捕获/跟踪文件 • /var/nstrace/ - ADC 数据包捕获/跟踪文件

抗氧化剂谱和Oryza sativa var的抗糖尿病作用。 Pulu Mandoti“当地金米”
糖尿病在全球影响5.37亿成年人,印度尼西亚有1,947万例病例。它是由胰岛素产生不足或无效的产生,导致肾病等并发症。由于常规药物的不利影响,对更安全的替代品的需求日益增加。功能性食品和生物活性化合物在管理糖尿病方面表现出希望。这样的选择是大米。印度尼西亚拥有一种独特的大米品种,称为普鲁·曼多(Pulu Mandoti),专门在印度尼西亚玛卡萨尔(Makassar)的恩雷卡(Enrekang)区种植。这种令人愉悦的红色大米变体提供了许多营养益处。与白米不同,红米在钙,锌,镁,蛋白质和纤维等必需营养素中含量丰富。这项研究的重点是Pulu Mandoti,使用LC-MS分析探索了其抗糖尿病和抗氧化活性的潜力。十二(12)种化合物,其中11种(2,2'-甲基苯甲比(二甲基苯甲比[B,d]噻吩))表现出最强的抗氧化剂。与Molecular Docking相比,与分子粘结相比,具有最强的抗氧化剂。 α-葡萄糖苷酶(分别为–10.5和–8.7 kcal/mol),而Acarbose的结合亲和力最高。用于抗氧化剂分析,化合物11和5分别证明了NADPH氧化酶和黄嘌呤氧化还原酶的结合亲和力最低,而维生素C的结合亲和力分别显示出最高的结合亲和力。抗糖尿病药物的药物性能相似性的系数相似性的系数相似性范围为0.40-0.76,抗氧化剂的化合物5显示最高系数值(0.76),抗氧化剂的系数最高(0.76),抗氧化剂的抗氧化剂值最高,抗氧化剂A乙酸抗氧化剂A乙酸抗氧化剂A乙酸抗氧化剂。

引用方式:Parra-Amaya,Marcela;罗哈斯-冈萨雷斯(Rojas-Gonzalez),赛达(Saida);伊利安·金特罗-珀西 (Ilian Quintero-Percy)冈萨雷斯-本迪克森·德·扎尔迪瓦,克劳迪娅;阿古德洛 - 克里斯坦乔,尼尔森(
在当前高度数字化的商业环境中,高效的文档管理对于提高生产力和优化组织流程至关重要。本文已确定了这一需求,并且改进了名为 Infopoint 的增强型产品,这是一款企业内容管理软件,通过实施先进的自动化和人工智能技术提供智能文档管理。在文档管理中,许多流程仍由人工执行,由于重复任务的负担而导致错误和延迟。手动管理还会导致内部延迟并影响与客户、供应商和监管实体的互动。手动文档搜索会浪费宝贵的时间,并可能给公司带来不必要的成本。Infopoint 通过整合自动化功能(尤其是利用卷积神经网络)来解决这些挑战。这种方法优化了传入通信的功能,平均将处理时间缩短了 29%。它还方便了 PDF 文档中的文本和内容搜索,将平均搜索时间缩短了 41%。本文重点介绍了这种改进如何显著减少通信管理和信息检索所花费的时间。