XiaoMi-AI文件搜索系统
World File Search SystemVide

vide
它处于分子的形状,也不是碱的类型,它在这些碱基的顺序中遵循。我们已经看到DNA加倍,因此遗传信息分布到分裂细胞中,我们将看到DNA在转录过程中产生核糖核酸(RNA),最后,RNA在翻译过程中的蛋白质合成中,RNA控制在细胞质中。理解重复,转录和翻译是应在体内非常准确,有效地发生的机制,避免错误。与正常代谢途径的任何错误或偏差都可能导致细胞内部的灾难,从而导致体内。例如,DNA重复的误解会导致除原始物以外的其他基因的产生,这些基因被传播到儿童细胞,并且通常不足以生存,这些是突变。在单个生物体中,有数万个不同的基因。如果它们全部由DNA组成,您是否想知道是什么使它们与众不同?什么将基因从一个物种到另一种区别区别开来?DNA始终具有双手的形式,并且总是由四种类型的核苷酸(a,t,c,g)组成。实际上,一个DNA分子可能与另一个分子不同,最初是由核苷酸的总数和碱基对的序列(“步骤”)。可能的几乎无限序列的数量允许存在多种极宽的基因。前三个氮基(A,G,C)也出现在DNA中。uracila是RNA独有的,就像胸腺胺(t)RNA分子是一条长长的独特胶带,简单,由核糖糖(R)和核苷酸(a),鸟嘌呤(G),胞质(C)和Uracilla(U)相互连接。

ia 450/2023:发音,录制的订单分开...
u/s。7,2016年:M/s。Sunedison Energy India Private Limited…金融债权人vs M/s。KSK Energy Company Private Limited…公司债务人C O R A M: - DR。 Venkata Ramakrishna Badarinath Nandula,Hon'ble成员(司法)sh。Charan Singh,Hon'ble成员(技术)

FAR 类别偏差 20-05 Rev_1 52.204_25 禁止签订某些电信和视频合同
目的:发布《联邦采购条例》(FAR)类别偏差 20-05 的第一次修订版,以包含 FAR 临时规则(联邦采购通告 2020-08)52.204-25 条款中的附加文本,自 2020 年 8 月 13 日起生效。临时规则将与《约翰·麦凯恩国防授权法案》(NDAA)2019 财政年度(Pub. L. 115-232)第 889(a)(l)(B) 节相关的附加定义和禁令纳入条款中,但不会更改 FAR 类别偏差 20-05 中 (d) 小段报告要求的文本。本次第一次修订版提供了 2020 年 8 月版的条款,其中包含我们之前发布的偏差中临时规则中的附加文本。 20-05 偏差修订了子段 (d) 中的报告要求,要求承包商报告同时发送给合同官员、合同官员代表 (COR) 和企业安全运营中心 (SOC)。这种方法确保及时向企业 SOC 报告,并更好地使部门能够快速评估和缓解情况,将其视为安全事件。

博士课程录取通知(2024 年秋季学期于 2024 年 8 月开始)马辛德拉大学,由特伦甘纳邦政府通知
• 电气与计算机工程:VLSI 设计、可再生能源系统和智能电网、电力电子和电力驱动、无传感器电力驱动、电动汽车、电动汽车充电、网络物理系统、电力电子系统的网络安全、燃料电池、混合储能系统、生物医学信号处理、生物识别和计算机视觉、超越 CMOS 的 VLSI 设计、无线通信、5G 和海量物联网、VLSI 中的机器学习、物理设计自动化算法、半导体器件、用于高频应用的高电子迁移率晶体管建模、用于低功耗逻辑实现的忆阻器逻辑、用于内存计算(IMC)的低功耗可靠存储器、用于空间应用的 SRAM、高性能感测放大器设计、用于无线通信的深度学习、无线电资源管理、MIMO 通信、非正交多址技术、PHY 和 MAC 层的优化、动态频谱接入、用于半导体应用的高 k 纳米材料的合成 • 化学:混合聚合物和纳米材料、响应性聚合物;用于储能应用的过渡金属氧化物和氮化物纳米结构的设计和合成;设计用于氢能的生物催化剂,用于柔性电子的二维材料•数学:数值分析;微分方程;偏微分方程分析;图像处理;随机控制;概率和统计;流体动力学;运筹学;工业和教育中的调度和时间表制定;有限群论;数值线性代数;和机器学习、金融数学•机械与航空航天工程:计算力学、理论固体力学、太阳能热能、制冷与空调、电池热管理、传热、微流体、生物流体动力学、生物力学建模与仿真、纳米材料、网络物理系统、先进制造系统、机器人、缆绳驱动机器人、外骨骼、外骨骼、无人机、钛合金 Ti6AI4V 板料成型、航空航天材料成型、轧制、航空航天材料制造过程模拟、增材制造、激光制造方法、增材制造的数值建模与仿真、先进精加工工艺等、智能制造、i4.0、工业工程、计算机辅助设计、湍流建模、燃烧建模、大涡模拟、直接数值模拟、湍流-化学相互作用、摩擦学、高超音速层流到湍流转变、采用氢和氢燃料的超燃冲压发动机推进、高速流动中的再生冷却、计算涡轮机械、高速反应和非反应流动中的 CFD 代码开发。

尊敬的 NGT 就上述事项于 2022 年 1 月 12 日下达命令,成立了一个由 MoEF&CC、地区办事处
就上述事项,NGT 先生于 2022 年 1 月 12 日通过命令成立了一个由八名成员组成的联合委员会,成员包括环境部和气候变化部、那格浦尔地区办事处、CPCB、浦那地区办事处、MCGM 专员、孟买东郊地区收税员、该地区的 DCP(由孟买警察局长指定)、马哈拉施特拉邦首席野生动物看守人、马哈拉施特拉邦环境主任和州 PCB。负责协调和合规的联络机构是州 PCB 和州湿地管理局。申请中的不满针对的是孟买东郊 Powai 湖的污染以及当局未能采取补救措施。申请人提到污染源是废水和污水的排放、非法填海建设和倾倒垃圾。NGT 先生于 2022 年 1 月 12 日通过的上述命令的副本见附件 I。此后,法庭根据各被告机构的诉状审议了此事,法庭于 2022 年 1 月 12 日下达命令,指出尽管已采取某些举措来恢复/复兴湖泊并防止破坏环境,但迄今为止采取的措施还不够,预期结果尚未实现。还提到,国家当局和民间社会需要继续持续努力,并保持警惕。此外,在必要时,通过所有法定监管机构的协调努力,采取强制措施来执行环境规范。尊敬的 NGT 对上述联合委员会的操作指示简要如下:

根据 2023 年 3 月 10 日 MNRE 的命令,太阳能光伏组件的核准型号和制造商(强制性要求
b) ALMM 将根据法律仅适用于由政府赞助/补贴的项目。ALMM 将适用于政府或其机构采购电力供自己消费或通过配电公司分配给人民。ALMM 将适用于受补贴的太阳能光伏屋顶和 PM KUSUM。ALMM 不适用于在开放获取下设立或由私人团体控制的项目。换句话说,ALMM 不适用于自行设立发电设施的人。
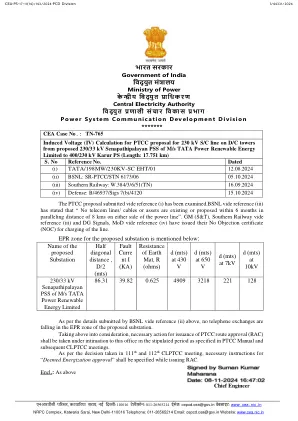
epr区域用于提议的变电站
PTCC建议提交的Vide参考(i)已进行了检查。BSNLVIDE参考(III)指出:“在电源线两侧的8 kms的平行距离内,没有电信线/电缆或资产在6个月内存在或提议。”GM(S&T),Southern Railway Vide Reference(III)和DG信号,Mod Vide参考(IV)已发布其无异议证书(NOC)以进行收费。

卡纳塔克邦电动汽车和能源存储政策2017
此命令与财务部的并发录音说明号FD 342 EXP-1/17,日期为2017年7月7日,运输部门VIDE文件号CI 117 SPI 2017(P-4),日期为2017年12月12日,收入部门录音号pàae60ªàäääääääääää2017,日期为2017年12月12日,技能开发,企业家和生计部门pëgfãe7pëuàä¥à2017年,日期为2017年12月12日CI 117 SPI 2017(P-5),日期为2017年8月8日,能源部门VIDE文件号CI 117 SPI 2017(P-3),日期为2017年8月18日,城市发展部VIDE文件号 CI 117 SPI 2017(P-2),日期为2017年11月8日,规划部门VIDE文件号 CI 117 SPI 2017(P-8),日期为2017年8月18日,IT/BT部门的信函号 ITD 07 PRM 2017,日期为2017年8月21日,内阁批准日期为13.09.2017。CI 117 SPI 2017(P-3),日期为2017年8月18日,城市发展部VIDE文件号CI 117 SPI 2017(P-2),日期为2017年11月8日,规划部门VIDE文件号 CI 117 SPI 2017(P-8),日期为2017年8月18日,IT/BT部门的信函号 ITD 07 PRM 2017,日期为2017年8月21日,内阁批准日期为13.09.2017。CI 117 SPI 2017(P-2),日期为2017年11月8日,规划部门VIDE文件号CI 117 SPI 2017(P-8),日期为2017年8月18日,IT/BT部门的信函号 ITD 07 PRM 2017,日期为2017年8月21日,内阁批准日期为13.09.2017。CI 117 SPI 2017(P-8),日期为2017年8月18日,IT/BT部门的信函号ITD 07 PRM 2017,日期为2017年8月21日,内阁批准日期为13.09.2017。

Inox可再生解决方案有限公司
我在此证明,RESCO全球WLND Services Private Limited,该有限公司最初于1月二十二天成立了1956年的2000年《二十二十条公司法》,为RESCO Global WLND Services Private Limited,并根据《公司法》第18条的第18条,201 3; ROC,CPC VIDE SRN AB1350850 1911012024的CPC VIDE SRN AB1350850已将上述公司的名称变成RESCO Global Wlnd Services Limited
