XiaoMi-AI文件搜索系统
World File Search SystemVision

NUGENIA 愿景 | SNETP
目前全球核电机组的设计寿命一般为 30 或 40 年。新安装的核电机组的设计寿命至少为 60 年。核电的经济特点是运行成本低且稳定,这是因为燃料成本在总成本结构中所占比例较低,这使得核电站 (NPP) 能够提供可靠、有竞争力且安全的低碳基载电力。一旦建成并投入使用,并且运行性能良好,核电站就应该能够长期发挥这一不可或缺的作用。由于核电站的固定成本高,运行成本低,因此随着发电量的增加,核电站的平均电力成本会大幅下降。因此,对于核电站运营商来说,实现高电厂容量系数对于长期运营至关重要。

我们的战略愿景
Our Strategic Vision looks far ahead, while focusing and organizing work for a 3–5-year horizon. Our Strategic Directions and Objectives will focus HathiTrust's time and its members' resources to fulfill our established Mission, Vision, Goals, and Values, and to support conscious growth and innovation in 2024 and beyond. While described separately, these Directions and Objectives are not listed in priority order, nor are they separable or sequential. They are connected and part of a symbiotic whole.

E-rong 的人工智能视觉
业务转型需要实时分析型人工智能来实现主动控制、预测性维护、预测性行为、自主流程、缺陷检测、安全、保障和质量控制。凭借我们的人工智能愿景,它可以成为改善您所有业务的创新。
NUGENIA 愿景 | SNETP
目前全球核电机组的设计寿命通常为 30 或 40 年。新安装的核电机组至少使用寿命为 60 年。核电的经济特点是运行成本低且稳定,这是因为燃料成本在总成本结构中所占比例较低,这使得核电站 (NPP) 能够提供可靠、有竞争力且安全的低碳基载电力。一旦建成并投入使用,并且运行性能良好,核电站就应该能够长期发挥这一不可或缺的作用。由于固定成本高且运行成本低,核电站的平均电力成本随着产量的增加而大幅下降。因此,对于核运营商来说,实现高电厂容量系数对于长期运营至关重要。


我们的愿景 - Indra
本演示文稿由 Indra 制作,仅用于其中所述的目的。因此,本演示文稿及其所含信息均不构成证券的要约出售或交换、购买或出售公司股份的邀请或有关此类证券的任何建议或推荐。其内容仅供参考,其所含声明可能反映公司在制定时某些前瞻性声明、期望和预测。这些期望和预测本身并不能保证未来的业绩,因为它们受风险、不确定性和其他公司无法控制的重要因素的影响,这些因素可能导致最终结果与这些声明中的结果大不相同。公司不承担与上述估计的准确性有关的任何义务或责任,也没有义务更新或修改它们。本文件包含未经审计的信息。从这个意义上讲,这些信息受所有其他公开信息的影响,并且必须与所有其他公开信息一起阅读。本文件针对的所有个人或实体以及那些认为他们必须就 Indra 发行的证券做出决定或发表意见的人都应考虑此免责声明。
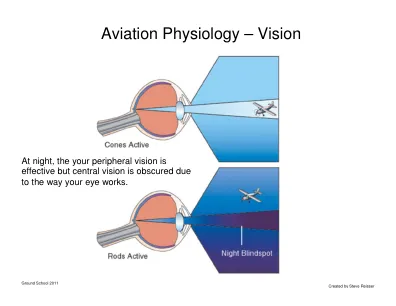
航空生理学 – 视觉
• 如果您或乘客潜水,请务必小心。潜水员的身体必须有足够的时间在飞行前排出潜水中积累的氮气。等待时间 飞行高度低于 8,000 英尺:潜水后无需控制上升至少等待 12 小时。潜水后需要控制上升至少等待 24 小时。飞行高度高于 8,000 英尺。任何水肺潜水后至少等待 24 小时。

乌干达 2040 愿景
BOP 国际收支 BPO 业务流程外包 BTVET 商业、技术和职业教育与培训 CAD/CAM 计算机辅助设计和制造 CIID 刑事情报和调查目录 CNDPF 综合国家发展规划框架 COMESA 东部和南部非洲共同市场 DPP 检察长 EAC 东非共同体 EACCM 东非共同体共同市场 ENR 环境与自然资源 EPRC 经济政策研究中心 ERP 经济复苏计划 FAO 粮食及农业组织 FDI 外国直接投资 FGM 女性生殖器切割 GDI 性别相关发展指数 GDP 国内生产总值 GKMA 大坎帕拉都会区 GMO 转基因生物 HDI 人类发展指数 HPP 水力发电厂 HRD 人力资源开发 ICT 信息通信技术 IDPs 国内流离失所者 IRWR 内部可再生水资源 ISO 国际标准化组织 IT 信息技术 ITES 信息技术支持服务 kWh 千瓦时 LDCs 低度发达国家

发展招股说明书和愿景
我很高兴我们的故事有很多层次,正是这些非凡的国际工业成就向您提供了我们的联系。我们雄心勃勃的陶器意义的增长是庆祝更新生产的愿景的核心,这在很大程度上依赖于特伦特河畔斯托克的独特制造遗产,并与二十一世纪的观众分享了我们的陶艺工业和当地故事。我们对PMAG的合适煤炭的更新博物馆和美术馆的可用性,将使我们能够讲述我们过去的全部故事,并在心脏开火的窑炉上兴奋不已(PMAG)。开拓者网络,人们关于我们未来的人。博物馆将成为特伦特河畔斯托克的枢纽。不仅使白色粘土成为国际陶瓷中心,跨越了从遥远的地方进口的非凡陶瓷中心,而且还促进了整个陶器及其他地区的收藏,以我们的城市为基础,始终与成品的丰富交付,连接Stoke-evernal-explote-Connection-connection-explote-explorce-教育,研究和策展人专业知识。和定义陶瓷遗产,可以是世界范围的。和叙述延伸到中世纪。整个20世纪的集体就无法独自实现这一转变。请加入我们作为英国陶艺行业的中心和流程的中心。“在特伦特的斯托克制造”是一个奇妙的旅程。十八世纪中叶。在全球每个部分都发现的后脚架。议员阿比·布朗(Abi Brown),领导人 - 特伦特市议会的斯托克它将需要形成现代城市的支持城镇,充满了精彩的手工艺陶瓷师,以及所有与陶器有亲密关系的人的承诺,被称为“陶器” 250多年来,高级制造业的出现以借鉴了我们的专业知识,我们的资源和我们的资源,以反映北夫人ceramic的重要性,这是在许多工业中的重要性。

Box Hill 的愿景
在此次广泛的参与中,Box Hill 社区和各利益相关方就该区域的优先成果、机会领域和初步想法提供了宝贵的反馈意见。提出和讨论的想法、问题和机会已被考虑在内,以形成该区域的长期愿景,该愿景反映了社区的需求和期望,并满足了不断增长的人口的需求。反馈意见形成了 Box Hill 愿景和概念区域规划。这些现在为未来规划设定了战略方向,并将为 Box Hill 的结构规划提供信息。这将指导该区域的规划、投资和开发计划。