XiaoMi-AI文件搜索系统
World File Search SystemVocal

可弯曲光纤鼻咽喉镜检查
1. 洗手;戴上手套 2. 在内窥镜镜头上涂抹除雾液 3. 考虑在内窥镜杆上涂抹润滑膏,必要时避开远端 2 厘米 4. 建议患者用鼻子呼吸以保持鼻孔畅通。 5. 用非惯用手稳定患者的头部,将柔性内窥镜插入一个或两个鼻腔以确定鼻内解剖结构。 6. 沿着鼻底推进内窥镜,避开中隔。观察鼻甲并评估粘膜是否有异常。 7. 将内窥镜穿过鼻咽部寻找异常。 8. 在软腭处,开始将内窥镜向下引导以观察口咽、下咽和喉部。 9. 如果镜头被粘液混浊,请患者吞咽 10. 以下步骤(11-14 可根据医生和患者的偏好选择) 11. 患者伸出舌头以观察声带谷 12. 患者鼓起脸颊以观察梨状窦 13. 患者反复说“E”以观察声带运动 14. 患者深吸一口气以观察声带完全外展 15. 撤出内窥镜

针对老年情绪和认知障碍的情感计算
情感计算(也称为人工智能情感智能或情感 AI)是研究和开发能够识别、解释、处理和模拟情感或其他情感现象的系统和设备。随着全球老龄人口的快速增长,情感计算在老年情绪和认知障碍的治疗和护理方面具有巨大的潜力。对于老年抑郁症,从声音生物标记到面部表情再到社交媒体行为分析的情感计算可用于解决当前筛查和诊断方法的不足,减轻孤独和孤立感,提供更加个性化的治疗方法,并检测自杀风险。同样,对于阿尔茨海默病,眼球运动分析、声音生物标记以及驾驶和行为可以为早期识别和监测提供客观的生物标记,使人们能够更全面地了解日常生活和疾病波动,并有助于理解躁动等行为和心理症状。为了优化情感计算的效用,同时降低潜在风险并确保负责任的发展,需要对针对老年情绪和认知障碍的情感计算应用程序进行道德开发。

2021-2026 年战略计划
认识到艺术,尤其是合唱团的声乐/合唱曲目,在我们的社会中具有独特的能力来促进社区精神,后湾合唱团力求在我们所有的艺术活动中做到奉献、严谨、亲切和慷慨。在我们的表演和节目中,后湾合唱团肯定了音乐弥合社会分歧和揭示我们共同点的变革能力。

喉返神经的解剖结构多种多样...
背景:本研究旨在阐述甲状腺切除术中遇到的喉返神经与甲状腺下动脉关系的解剖变异。这是一项描述性的病例系列研究,在阿伯塔巴德联合军事医院耳鼻喉科进行。研究于 2016 年 1 月至 2017 年 9 月进行。方法:51 名患者在全身麻醉下接受了甲状腺囊外切除术。所有患者的解剖均以标准方式进行。在每位患者中都识别并暴露喉返神经,并将其解剖关系记录在数据库中。结果:在大多数左侧解剖标本中,可见喉返神经骑跨甲状腺下动脉的分支,但在右侧,发现主要神经通过甲状腺下动脉的分支上升。结论:医源性声带麻痹对接受甲状腺切除术的患者的生活质量有严重影响。喉返神经的解剖变异众所周知且常见。通过彻底了解喉返神经的解剖变异,并在术中识别和暴露主要神经,可以充分预防意外喉返神经损伤造成的灾难性后果。关键词:甲状腺切除术;喉返神经;解剖;医源性;声带麻痹
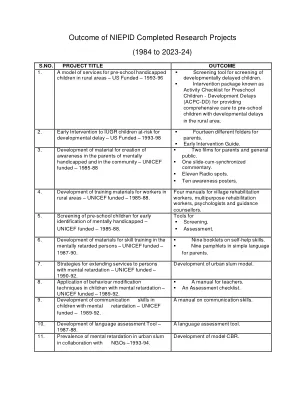
NIEPID完成的研究项目的结果(1984年至...
1。残疾原因; 2。预防残疾; 3。早期识别和干预; 4。全包教育和5。职业培训和就业能力。这些视频具有手语的解释和字幕,使它们适用于不同范围的用户。76 DISAAA:使用视觉注意,面部表达和声音情感提示(与CDAC Kolkata合作)自动评估自闭症的综合解决方案(2022-23)

验证软件胎儿脑体积。...
1. Malinger G、Paladini D、Haratz KK、Monteagudo A、Pilu GL、Timor-Tritsch IE。ISUOG 实践指南(更新版):胎儿中枢神经系统超声检查。第 1 部分:筛查检查的表现和有针对性的神经超声检查指征。妇产科超声。2020;56:476-484。2. De Oliveira Júnior RE、Teixeira SR、Santana EFM 等人。宫内生长受限胎儿颅骨和脑参数的磁共振成像。放射学杂志。2021;54:141-147。3. Jarvis DA、Finney CR、Griffiths PD。使用宫内 3D 体积 MR 成像对胎儿颅内区室进行规范体积测量。欧洲放射学杂志。 2019;29:3488-3495。4. 任建英,朱敏,王刚,桂英,姜锋,董胜哲。使用 3-D 容积 MRI 量化胎儿颅内结构体积:妊娠 19 至 37 周的正常值。神经科学前沿。2022;12(16):886083。5. Sadhwani A、Wypij D、Rofeberg V 等人。胎儿脑体积可预测先天性心脏病的神经发育。循环。2022;12(145):1108-1119。6. Sarno M、Aquino M、Pimentel K 等人。疑似先天性寨卡病毒综合征小头畸形胎儿中枢神经系统进行性病变。妇产科超声。 2017;50:717-722。7. Prayer D、Malinger G、Brugger PC 等。ISUOG 实践指南:胎儿磁共振成像的表现。妇产科超声。2017;49:671-680。8. Resta S、Scandella G、Mappa I、Pietrolucci ME、Maqina P、Rizzo G。体外受精后妊娠的胎盘体积和子宫动脉多普勒:全面的文献综述。临床医学杂志。2022;29(11):5793。9. Alves CM、Araujo Júnior E、Nardozza LM 等。多平面模式下三维超声检查胎儿脑裂发育的参考范围。超声医学杂志。2013;32:269-277。 10. Kalache KD、Espinoza J、Chaiworapongsa T 等。三维超声胎儿肺容积测量:多平面法与旋转(VOCAL™)技术系统比较研究。妇产科超声。2003;21:111-118。11. Kusanovic JP、Nien JK、Gonçalves LF 等。反转模式和 3D 手动分割在胎儿充满液体的结构体积测量中的应用:与虚拟器官计算机辅助分析(VOCAL™)进行比较。妇产科超声。2008;31:177-186。

语音敏感听觉皮层中情绪韵律的神经解码可预测儿童的社交沟通能力
在社交互动过程中,说话者通过声音传达有关其情绪状态的信息,这被称为情绪韵律。人们对儿童情绪韵律解码背后的确切大脑系统以及这些声音线索的准确神经解码是否与社交技能有关知之甚少。在这里,我们通过研究韵律的神经表征及其与儿童行为的联系来解决发展文献中的关键空白。多元模式分析显示,语音敏感听觉皮层的双侧中颞上沟 (STS) 分区中的表征解码儿童的情绪韵律信息。至关重要的是,中颞上沟的情绪韵律解码与标准化的社交沟通能力测量相关;对颞上沟韵律刺激的更准确解码预示着儿童的社交沟通能力更强。此外,社交沟通能力与解码悲伤特别相关,强调了调整负面情绪声音线索对于增强社交反应能力和功能的重要性。研究结果表明,语音敏感皮层检测言语中情绪线索的能力可以预测儿童的社交能力,包括与他人交往和互动的能力,从而弥补了一个重要的理论空白。

CSJM大学,Kanpur NEP计划2024-25 BA-I学期 国际会议 e0025关于NEP奇数学期计划2024-25.pdf vko'; d lwpuk 校园考试时间表(奇数SEM)2024-25 医疗保健新时代的药物创新 b'' 入学手册2024-25 最终SBS chhatrapati shahu ji ji maharaj大学,坎普尔 NEP甚至学期考试方案。 2023-24 dk; kzy; kki
现代世界的历史(公元1453年 - 1815a.d。)/中世纪印度的社会和经济历史(1200a.d.-公元1700年) /历史上的道德规范28-01-2025哲学哲学哲学哲学(印度和西方)梵语A020501T vaidik vaidik vaikya vakya evam evam evam evam evam evam evam evam bhartiya darsried哲学 A020502T Vykaran Evam Bhasha Vigyan 30-01-2025 02:30 PM To 04:30 PM Thursday BA-V Drawing & Painting A140501T History of Indian Architecture 31-01-2025 02:30 PM To 04:30 PM Friday BA-V Drawing & Painting A140502T History of Indian Art - 2 01-02-2025 02:30 PM To 04:30下午星期六BA-V音乐声音A320501T西方音乐科学,印度音乐风格,03-02-2025 02:30 pm至04:30 pm星期一BA-V音乐声音A320503T应用Ragas和Taals Applied理论04-02-2025 02-2025 02:30 pm至04:30 PM星期二BA-v Mustice pla-v Music taper plapan ba-v Music plapla a310503 05-02-2025 02:30 pm至04:30 pm星期三星期三BA-V体育E020501T运动受伤和物理疗效06-02-2025 02:30 02:30 pm至04:30 pm至04:30 ba-V体育运动E020502T运动学和体育运动学

疫苗接种、启蒙价值观和创始人 | 1
讽刺的是,许多最直言不讳地为开国元勋辩护的人,对开国元勋的启蒙价值观最为敌视。开国元勋们坚信科学是改善人类状况的一种方式。疫苗接种问题表明,开国元勋们与他们的潜在崇拜者相距甚远。这些反启蒙运动(因此也是反开国元勋)的态度也是同一政治派别拒绝气候科学的关键。今天有些人可能倾向于拒绝令人不快的真相,但开国元勋们更清楚这一点。

使用深度实时语音情感识别...
在人与人之间的互动中,检测情绪通常很容易,因为它可以通过面部表情、肢体动作或言语来感知。然而,在人机交互中,检测人类情绪可能是一个挑战。为了改善这种互动,出现了“语音情绪识别”一词,其目标是仅通过语音语调来识别情绪。在这项工作中,我们提出了一种基于深度学习方法和两种高效数据增强技术(噪声添加和频谱图移位)的语音情绪识别系统。为了评估所提出的系统,我们使用了三个不同的数据集:TESS、EmoDB 和 RAVDESS。我们采用了多种算法,例如梅尔频率倒谱系数 (MFCC)、零交叉率 (ZCR)、梅尔频谱图、均方根值 (RMS) 和色度,以选择最合适的代表语音情感的声音特征。为了开发我们的语音情感识别系统,我们使用了三种不同的深度学习模型,包括多层感知器 (MLP)、卷积神经网络 (CNN) 和结合 CNN 与双向长短期记忆 (Bi-LSTM) 的混合模型。通过探索这些不同的方法,我们能够确定最有效的模型,用于在实时情况下从语音信号中准确识别情绪状态。总体而言,我们的工作证明了所提出的深度学习模型的有效性,