XiaoMi-AI文件搜索系统
World File Search SystemWeighting

通过机器学习的合成控制:对劳动放松管制对巴西工人生产力的影响的应用
合成控制方法是一种数据驱动的方法,用于计算控制个体的反事实,以估计许多经验重要性的治疗效果。在规范实现中,这种加权是线性的,是供体池选择和处理的实体之间的协变量比较的关键方法论步骤,其合成控制取决于一定程度的主观判断。因此,当前方法在具有大型数据集的设置中可能不会发挥最佳性能,或者是通过供体池个体的非线性组合获得最佳合成控制的。本文提出了“机器控制”,基于自动化供体池选择的合成控制,通过插入算法选择,监督控制实体的灵活非线性加权的学习以及将歧管学习以数值确认合成控制是否确实类似于目标单位。机器控制方法得到了2017年劳动放松管制对巴西工人生产力的影响。与制定改革时的决策者期望相反,对工人的生产力没有明显影响。这个结果表明,在提高生产率水平以及经济福利方面面临着深远的挑战。JEL:B41,C32,C54,E24,J50,J83,O47。关键字:因果推理,合成控制,机器学习,劳动力改革,生产力。


从 Pearson (Edexcel) 升至 OCR 的商业 A 级
有三个部分,全部通过考试进行外部评估。前两份试卷各占 35%。期末试卷占 30%。前两部分评估的内容不同。第三部分可以评估任何内容。评分资格的评分标准为:A*、A、B、C、D、E,其中 A* 为最高分。未达到 E 的最低标准的学生将不予评定。
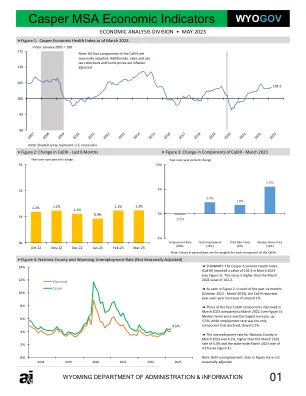
卡斯珀 MSA 经济指标
方法:从 2005 年 1 月开始,上述各组成部分的每个系列都进行了标准化,因此每个组成部分和 CaEHI 的值均为 100。随着每个组成部分每月的变化,CaEHI 值也会发生变化。接下来,计算每个组成部分标准化系列值的标准差,然后计算每个组成部分标准差的倒数。最后,对各个倒数标准差进行标准化,从而得出总和为 1 的权重。这种加权方法的原理是,随着时间的推移,更稳定的组成部分的标准差较小,因此倒数标准差和权重较大。通常稳定的数据系列的大幅变化比通常波动较大的数据系列的大幅变化更能表明经济发生了变化。因此,这种加权方法允许 CaEHI 对更稳定的组成部分赋予更大的权重,这样,如果它们确实经历了大幅变化,CaEHI 的值将受到更大的影响,以代表该县经济状况的变化。最后,使用 3 个月移动平均线来平滑指数。这有助于消除由于某个成分在特定月份记录异常高或低值而可能出现的大“峰值”。
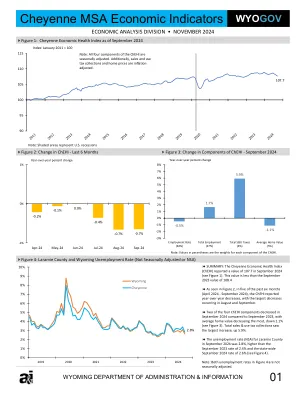
夏延 MSA 经济指标 WYOGOV
方法:从 2005 年 1 月开始,上述各组成部分的每个系列都进行了标准化,因此每个组成部分和 ChEHI 的值均为 100。随着每个组成部分每月的变化,ChEHI 值也会发生变化。接下来,计算每个组成部分标准化系列值的标准差,然后计算每个组成部分标准差的倒数。最后,对各个倒数标准差进行标准化,得出总和为 1 的权重。这种加权方法的原理是,随着时间的推移,更稳定的组成部分的标准差较小,因此倒数标准差和权重较大。通常稳定的数据系列的大幅变化比通常波动较大的数据系列的大幅变化更能表明经济发生了变化。因此,这种加权方法允许 ChEHI 赋予更稳定的组成部分更大的权重,这样,如果它们确实发生了大幅变化,ChEHI 的值将受到更大的影响,以代表该县经济状况的变化。最后,使用 3 个月移动平均线来平滑指数。这有助于消除由于某个成分在特定月份记录异常高或低值而可能出现的大“峰值”。

药品包装中的可持续性
此外,消费者对对可持续产品和材料的需求的影响越来越大。大约70%的全球消费者愿意为可持续包装支付更多费用。同样,药物领域对更环保包装的需求也在增加,在选择产品时,更多的患者和消费者正在考虑可持续性因素。例如,自2022年4月以来,国家卫生服务(NHS)的采购必须包括英国(英国)(英国)的净零10%和社会价值权重。

2021 年社会责任
凭借其在材料科学方面的专业知识,该集团正利用高性能创新材料加速应对当前和未来的挑战。它涵盖低碳移动解决方案,例如电池、氢和轻量化、3D 打印、更环保的涂料、生物源和可回收解决方案。该集团正努力将对联合国可持续发展目标做出重大贡献的销售额份额从目前的 51% 提高到 2030 年的 65%。

U-SURF:全球1公里在空间连续的城市地面财产数据集,用于公里尺度的城市分辨地球系统建模
图1。城市峡谷的概念示意图代表CLMU中的城市景观(改编自Oleson等,2008a)。特性是颜色编码的:蓝色用于辐射,橙色用于热和绿色的形态学。请注意,屋顶和壁厚(尽管与城市形态相关)被认为是热特性,因为它们主要用作加权因素,以计算CLMU中峡谷表面的传导通量(Lawrance等,2018; Oleson等人,2010年)。165

促进气候预测使用的科学指南
总而言之,CMIP6集合没有形成当前气候灵敏度知识的代表性样本,因此,集合平均值和其他统计数据是偏见的。这意味着根据气候灵敏度估计值,CMIP6集合的平均温度变化高于预期。这是所谓的热模型的问题。通过插图,图3显示了温度变化的两个直方图,一个是通过通过其气候灵敏度加权CMIP6集合(SSP5-8.5)中的模型而计算得出的,而另一个则无需加权。我们可以

设计行为感知人工智能,提高人机团队在人工智能辅助决策中的表现
随着人工智能模型驱动的决策辅助工具的快速发展,人工智能辅助决策的实践越来越普遍。为了提高人机团队的决策能力,早期的研究多集中于提高人类更好地利用给定的人工智能驱动的决策辅助工具的能力。在本文中,我们通过一种互补的方法来应对这一挑战——我们旨在通过调整决策辅助工具背后的人工智能模型来训练“行为感知人工智能”,以考虑人类在采纳人工智能建议时的行为。具体来说,由于人们观察到当人类对自己的判断信心较低时,他们会更容易接受人工智能的建议,因此我们建议使用基于人类信心的实例加权策略来训练人工智能模型,而不是解决标准的经验风险最小化问题。在一个假设的、基于阈值的模型下,该模型描述了人类何时会采纳人工智能建议,我们首先推导出用于训练人工智能模型的最佳实例加权策略。然后,我们通过在合成数据集上进行系统实验,验证了我们提出的方法在提高人机联合决策性能方面的有效性和稳健性。最后,通过对真实人类受试者的随机实验以及他们采纳人工智能建议的实际行为,我们证明了我们的方法在实践中可以显著提高人机团队的决策性能。