XiaoMi-AI文件搜索系统
World File Search SystemXT
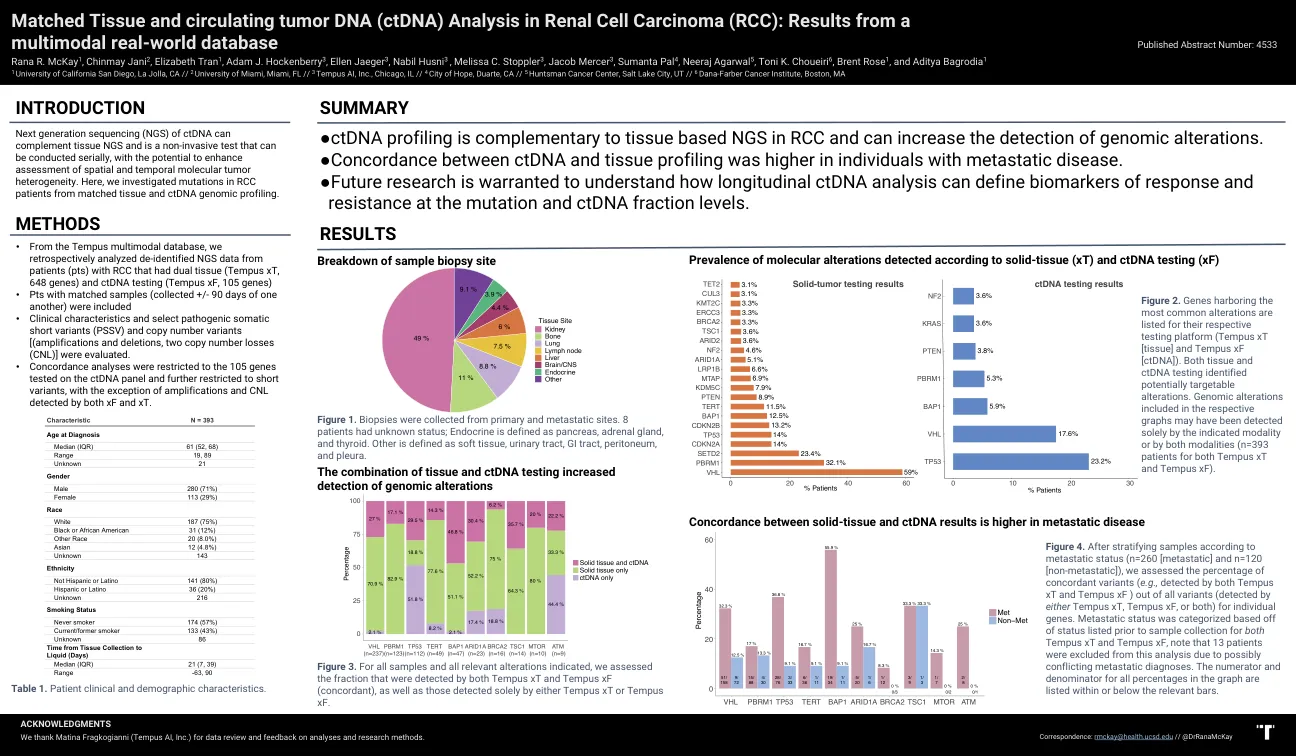
肾细胞癌(RCC)中匹配的组织和循环肿瘤DNA(CTDNA)分析:来自多模式现实世界数据库
结果•从tempus多模式数据库中,我们回顾了带有双组织(tempus XT,648个基因)和ctDNA测试的RCC的患者(PTS)的去识别的NGS数据(PTS)(tempus XF,105个基因)•cluntericatiental xf seletister•clunical clinistic and clunical Spactical contricatient contricatient•colletical contricatiencatient•colletical contericatience +colleticatience +contericatience +conted +colletical +seles +90天。评估了简短变体(PSSV)和拷贝数变体[(放大和删除,两个拷贝数损失(CNL)]。•一致性分析仅限于在ctDNA面板上测试的105个基因,并进一步限于短变体,除了放大和XF和XT检测到的CNL外。

深度循环编码器:一种用于大规模脑磁图建模的端到端网络
图 E 1 用于预测 MEG 活动的深度循环编码器 (DRE) 模型的表示。被掩蔽的 MEG pt ⊙ xt 从底部进入网络,连同控制表示 ut 和主题嵌入 s 。编码器使用卷积和 ReLU 非线性转换输入。然后,LSTM 对隐藏状态序列 ht 进行建模,并将其转换回 MEG 活动估计 ˆ xt 。Conv 1 d ( C in , C out , K, S ) 表示随时间进行的卷积,其中输入通道为 C in,输出通道为 C out,内核大小为 K,步幅为 S。类似地,ConvTransposed 1 d ( C in , C out , K, S ) 表示随时间进行的转置卷积。

大宗商品价格不确定性联动:对全球经济增长有影响吗?
其中 pt :全球大宗商品价格对数差异,un t :先前估计的大宗商品不确定性因素,π t :季度通胀率,xt :给定的宏观经济变量,it :名义政策利率

Controllogix 5580和Guardlogix 5580控制器
第1章Controllogix和Guardlogix系统最小要求。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11个控制器控制器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。12 Controllogix无存储能量(NSE)控制器。。。。。。。。。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>12摄影XT和Guardlogix XT造影剂。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>12个过程控制。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>12个确认涂层产品。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 Controllogix冗余控制器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 Controllogix系统。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。14独立控制器和I/O。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。一个底盘中的14个多个控制器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。通过多个网络连接的14个多个设备。。。。。。。。。。。。。。。。。。。。。。。。。。15 Guardlogix系统。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。16具有安全I/O和集成安全驱动器的Guardlogix。。。。。。。。。。。。。。。。。。。。17设计系统。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。19 CIP安全性。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。19个安全控制器系统。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>19 pontrogix 5580控制器功能。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>20 GuardLogix 5580控制器功能。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>21个由Guardlogix 5580控制器支持的功能通过安全任务。 div>。 div>。 div>。 div>。 div>。 div>。 div>22 div>

业务增强计划(BEP) - 农业
涉及该计划是专门为增值AGR I文化和供应链食品活动(加工,制造,分销,聚合等)的企业设计的。它可以帮助支持对以下资源的访问,以将您的业务扩展或将您的业务扩展到NE XT级别,以至于几乎没有到成功。

接下来会发生什么?
11 这种方法在结构性变化建模中的应用包括 Kulish 和 Rees (2000) 在商品价格永久性变化背景下的应用、Gomez-Gonzalez 和 Rees (2018) 在加入货币联盟背景下的应用以及 Jones (2020) 在人口变化背景下的应用。12 这并不意味着经济将在 2020 年第二季度完全复苏,因为 2020 年第一季度的产出下降需要时间来消除。相反,它假设变量之间的关系与新冠危机之前的关系相似。13 例如,3 月份的 Consensus Economics 调查对 2020 年 GDP 同比增长的平均预测为美国 1.4%、欧元区 0.9% 和日本 1.0%。 14 具体来说,简化形式的解为:xt = ¯ J + ¯ Q xt − 1 + ¯ G ε t,其中 ¯ J = ( ¯ A − ¯ BQ ) − 1 ( ¯ C + ¯ DJ ),¯ Q = ( ¯ A − ¯ BQ ) − 1 ¯ B 和 ¯ G = ( ¯ A − ¯ BQ ) − 1 ¯ F。
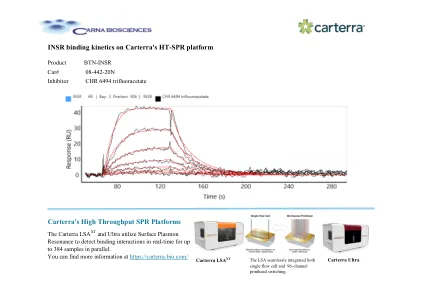
Carterra HT-SPR 平台上的 INSR 结合动力学
Carterra LSA XT 和 Ultra 利用表面等离子体共振实时检测多达 384 个样本的结合相互作用。您可以在 https://carterra-bio.com/ Carterra Ultra 上找到更多信息 LSA 无缝集成了单流动池和 96 通道打印头切换。
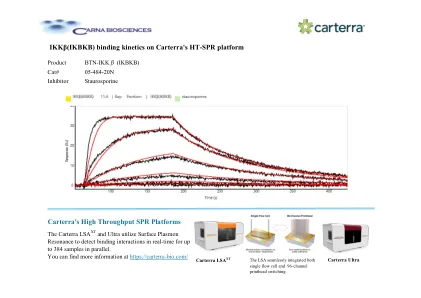
Carterra HT-SPR 平台上的 IKKβ(IKBKB) 结合动力学
Carterra LSA XT 和 Ultra 利用表面等离子体共振实时检测多达 384 个样本的结合相互作用。您可以在 https://carterra-bio.com/ Carterra Ultra 上找到更多信息 LSA 无缝集成了单流动池和 96 通道打印头切换。

致一年级老师们 致一年级学生家长
Tecchia Rosaria - D'Arienzo Irene - Furno Elena - Coppola Francesca xt=%7b%22Tid%22%3a%223c969357-47bc-4e93-8296-84d72122385b%22%2c%22Oid%22%3a%224aa0b629-d5d6-45d0-b4f5-8d124079c58e%22%7d Narducci Nicola- D'Angelo Raffaele- Cappabianca Pasquale- Apisa Luigi- Zacchia Rosaria

CS480/680:机器学习简介
•输入序列x =(x 1,。。。,x m)⊤,xt∈Rp单速•输出序列y =(y 1,。。。,y l)⊤,yt∈Rp单速•嵌入:xw e和y w e,其中we∈Rp×d,d = 512•(添加)位置编码:wp∈Rlen×d