XiaoMi-AI文件搜索系统
World File Search Systemangle


全方位卓越 - Marel
地缘政治紧张局势加剧,尤其是在 2022 年初的欧洲,将带来不确定性。Marel 对入侵乌克兰的立场很明确,可在此处找到。Marel 通过其全球影响力、创新的产品组合和多元化的业务组合,平衡了对全球经济和本地市场的接触。事实上,我们的商业模式在动荡时期已被证明具有弹性。我们的全球影响力以及多年来对创新和数字解决方案的投资已被证明是 Marel 的关键差异化因素。从长远来看,这些将使我们能够向前推进并帮助我们应对地缘政治紧张局势。这条道路当然在某种程度上是一条发现之路,有固有的挑战和学习,但 Marel 团队将以其特有的决心来管理这条道路。

角度/能量数量 - nyserda
太阳光线与收集表面(无论是地球表面还是太阳能电池板的表面)的垂直度越大,能量就越集中,太阳能增益就越大。这种垂直度可以收集更多的太阳能,太阳能电池板可以输出更多的电能,同时地球上接受更多阳光直射的地区温度也会更高。在地球上,加热差异造成了从赤道到两极的气候温度的基本变化。这种温度不平衡导致热能以风的形式从赤道流向两极(包括地表风和大规模行星风)。
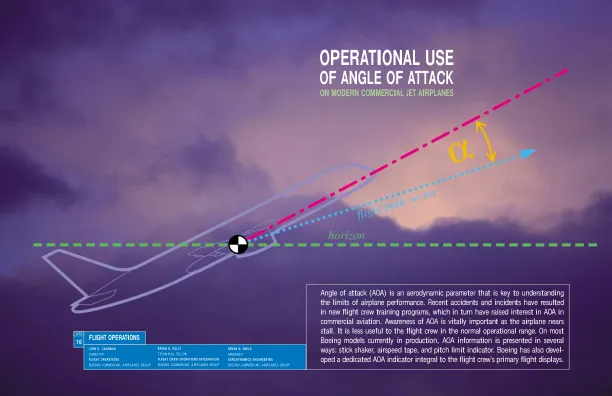
迎角作战使用 - 波音
在大多数情况下,上面讨论的影响是可以补偿的,而且根据飞机的不同,许多影响已经得到补偿。但应注意,每项修正都有其固有的不确定性,如果输入数据不正确,也会导致错误读数。在“保持简单”的理念中,对其他数据的依赖越少,AOA 系统就越强大。例如,马赫数会影响传感器校准。虽然这种关系可以得到补偿,但这会使传感器输出依赖于良好的马赫数信息。如果空速数据不准确,计算出的马赫数以及校准的 AOA 读数将不正确。这将在空速系统发生故障时影响 AOA 的实用性。请注意,由于

有限的深度增量优化模型 -
摘要工业计算机断层扫描(CT)广泛用于各种行业的非破坏性测试和质量控制。然而,工业CT中的一个共同挑战是由有限的角度层析成像引起的伪影的存在,由于几何约束或时间限制,该物体无法完全旋转。为了消除工件,我们提出了一个基于扩散模型的新框架:深度增量角度改进模型(DI-ARM)。我们的方法通过使用不同有限角度的重建数据作为训练过程中的中间步骤来利用CT投影的特性,取代了添加随机高斯噪声的传统扩散模型。这种方法确保了训练过程中的数据一致性,从而减轻了通过扩散模型的随机性引起的不稳定性。此外,与常规扩散模型相比,我们的方法需要更少的步骤,从而大大降低了计算资源消耗。

高攻角稳定弹丸 - DTIC
估计此信息收集的公共报告负担平均为每份回应 1 小时,包括审查说明、搜索现有数据源、收集和维护所需数据以及完成和审查收集信息的时间。请将有关此负担估计或此信息收集的任何其他方面的评论(包括减轻负担的建议)发送至国防部华盛顿总部服务处信息行动和报告局 (0704-0188),1215 Jefferson Davis Highway, Suite 1204, Arlington, VA 22202-4302。受访者应注意,尽管法律有任何其他规定,但如果信息收集未显示当前有效的 OMB 控制编号,则任何人均不会因未遵守信息收集而受到任何处罚。请不要将您的表格寄回上述地址。

按攻角飞行 - Alpha Systems AOA
alphasystemsaoa.com › 文章 › C... PDF 2018 年 6 月 14 日 — 2018 年 6 月 14 日 进入飞机飞行包线的下端,通常导致... 航空飞机,通常成本... 专注于人为因素驱动。

攻角仪 - 先进飞行系统
8. 本保证仅适用于原购买者,不可转让。本保证取代所有其他明示或暗示、口头或书面的保证或义务。AFS 明确否认所有适销性或特定用途适用性的暗示保证。购买者同意,在任何情况下,AFS 均不对特殊、偶发或后果性损害承担责任,包括发动机或飞机损坏、利润损失、使用损失或其他经济损失。除非本文另有明确规定,AFS 不承担对购买者或任何其他人与 AFS 产品的使用或性能有关的所有其他责任,包括但不限于严格产品侵权责任。


替莫唑胺的化学放射疗法以及Nivolumab或安慰剂的III期试验,用于新诊断的胶质母细胞瘤,甲基化的MGMT启动子
摘要:在这项研究中,处理输入参数对糖棕榈纤维增强的三种材料厚度的KERF锥度角响应的影响研究被研究为磨料水夹和激光束束切割技术的输出参数。该研究的主要目的是获取数据,其中包括使用这两种非常规技术来切割复合材料的最佳输入参数,以避免使用传统的切割方法切割复合材料时出现的某些缺陷,然后进行比较,然后进行比较以确定哪种是关于KERF Taper角度响应的最合适的技术,该技术是所需的所缺乏的。选择了可变输入参数,以优化KERF锥度角度。虽然水压,穿越速度和隔离距离是水夹切割过程的输入变量参数,但在两种切割技术中,所有其他输入参数都固定。使用Taguchi的方法确定了提供KERF锥度最佳响应的输入参数的水平,并通过计算每个参数的信号to-noise比率(S/N)的最大值差异来确定输入参数的重要性。使用变异分析(ANOVA)确定了每个输入处理参数对KERF锥度角度影响的贡献。与先前研究中推断的结果相比,在KERF锥度角的响应方面,这两个过程均获得了可接受的结果,并指出从激光切割过程中产生的平均值远低于由于水夹切割过程而产生的,这给激光切割技术提供了优势。