XiaoMi-AI文件搜索系统
World File Search Systemaugmentation
生成数据增强改善涂鸦 -
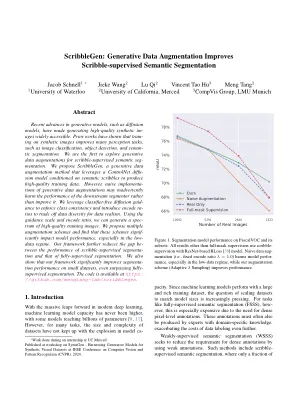
生成模型(例如扩散模型)的最新进展使生成高质量的合成IMEGES可以广泛访问。先前的作品表明,对合成图像进行培训可以改善许多感知任务,例如图像分类,对象检测和半分割。我们是第一个探索生成数据增强的人。我们提出了Scribblegen,这是一种生成数据增强方法,该方法利用ControlNET扩散模型,该模型以语义涂鸦为条件,以产生高质量的训练数据。但是,生成数据增强的幼稚实施可能会无意中损害下游分段的性能,而不是改善它。我们利用无分类器扩散指南来执行类的一致性,并引入编码ratios来将数据多样性换成数据现实主义。使用指导量表和编码比率,我们可以生成一系列高质量训练图像。我们提出了多个增强方案,发现这些方案显着影响模型性能,尤其是在低数据制度中。我们的框架进一步减少了涂鸦监督段的性能和完全监督的分割之间的差距。我们还表明,我们的框架显着改善了小数据集上的细分性能,甚至超过了完全监督的细分。该代码可在https://github.com/mengtang-lab/scribblegen上找到。

eeg- ...
摘要 - 基于脑电(EEG)的情感计算结果中的数据稀缺问题在构建具有机器学习算法(尤其是深度学习模型)的有效模型的有效模型中很困难。数据增强最近已实现了深度学习模型的大量性能改善 - 精确度,稳定性和减少过度填充。在本文中,我们提供了一个新颖的数据增强框架,即基于基于网络的对抗性网络的自我监督数据增强(Ganser)。是将对抗性训练与自我监督的学习相结合的第一个,以供基于脑电图的情绪识别,该拟议的框架可以生成高质量和高多样性模拟的脑电图样本。特别是,我们利用对抗训练来学习脑电图发生器,并迫使生成的脑电图信号近似实际样品的分布,从而确保增强样品的质量。使用转换函数来掩盖EEG信号的部分,并迫使发电机根据其余部分合成潜在的EEG信号,以生成各种样品。引入了转换过程中的掩蔽可能性作为先验知识,以指导为模拟的EEG信号提取可区分特征,并将分类器推广到增强样品空间。最后,广泛的实验证明了我们提出的方法可以帮助情绪识别绩效增长并实现状态结果。索引术语 - 基于EEG的情绪识别,数据库,生成对抗网络

一种用于改善多重对比度增强方法......
大多数数据驱动方法都很容易受到数据变化的影响。当将深度学习 (DL) 应用于脑磁共振成像 (MRI) 时,这个问题尤其明显,因为脑磁共振成像的强度和对比度会因采集协议、扫描仪和中心特定因素而变化。大多数公开的脑磁共振数据集来自同一中心,在扫描仪和使用的协议方面是同质的。因此,设计出可以推广到多扫描仪和多中心数据的稳健方法对于将这些技术转移到临床实践中至关重要。我们提出了一种基于高斯混合模型 (GMM-DA) 的新型数据增强方法,目的是增加给定数据集在强度和对比度方面的可变性。该方法允许增强训练数据集,使训练集中的可变性与现实世界临床数据中看到的可变性相媲美,同时保留解剖信息。我们比较了最先进的 U-Net 模型在添加和不添加 GMM-DA 的情况下对脑结构进行分割训练的性能。这些模型在单扫描仪和多扫描仪数据集上进行训练和评估。此外,我们验证了同一患者图像(相同和不同扫描仪)的重测结果的一致性。最后,我们研究了偏差场的存在如何影响使用 GMM-DA 训练的模型的性能。我们发现,即使训练集已经是多扫描仪,添加 GMM-DA 也可以提高 DL 模型对训练数据中不存在的其他扫描仪的泛化能力。此外,同一患者分割预测之间的一致性得到了改善,无论是同一扫描仪重复还是不同扫描仪重复。我们得出结论,GMM-DA 可以提高 DL 模型在临床场景中的可转移性。

人类增强 - 新范式的曙光
该项目是德国政府国防计划办公室与英国的发展,概念和教义中心之间的双边合作。战略意义项目的产出将与全国防和安全部门的广泛受众相关。尽管这不是科学出版物,但它广泛借鉴了研究,以概述关键机会和威胁所在的位置。许多具有将战略优势带到2050年已经存在的技术,无疑将发生进一步的进步。我们对这些技术的技术,道德,法律和社会含义的理解将是决定性的,因此它们证明其具有变革性。我们的潜在对手不会受到我们所拥有的道德和法律考虑的影响,并且他们已经在发展人类的增强能力。我们的主要挑战将是在该领域建立优势,而不会损害我们生活方式的价值观和自由。

平等获得精神增强的神经权利
从这颗种子开始,哥伦比亚大学、美国国家科学基金会和拉斐尔·尤斯特与来自科学和伦理各个领域的一群领导人进行了为期三天的研讨会。在这些会议之后,神经权利倡议成立了。然后,在 2019 年,他们制定了五项具体的神经权利:个人身份权、自由意志权、精神隐私权、平等获得精神增强的权利和免受算法偏见的权利(神经权利倡议,2021 年)。如今,该倡议由哥伦比亚大学神经技术中心管理,尤斯特担任主任。具体来说,平等获得精神增强的权利定义为:“应该在国际和国家层面制定指导方针,规范精神增强神经技术的开发和应用。这些指导方针应基于正义原则,并保证所有公民平等获得这些技术”(神经权利倡议,2021 年)。

将增强和缺失的像素归合组合
遥感图像分类在各种领域至关重要,包括农业,城市规划和环境监测。但是,有限的标记数据和缺失的像素对实现准确的分类构成了挑战。在这项研究中,我们提出了一个综合框架,该框架使用潜在扩散模型和基于强化学习的基于基于学习的缺失像素插补来整合数据,以增强深度学习模型的分类性能。该框架由三层组成:数据增强,缺少像素的插补以及使用修改后的VGG16体系结构进行分类。基准数据集上的广泛实验证明了我们的框架的重大影响,通过显着提高分类准确性和鲁棒性,超过了最新技术。结果突出了我们的增强和归纳技术的有效性,分别达到97.56%,97.34%和97.34%的骰子得分,准确性和召回指标。我们提出的框架为准确的遥感图像分类提供了一个宝贵的解决方案,解决了有限数据和缺失像素的挑战,并且在各个域中具有广泛的应用程序。关键字:VGG 16,卷积神经网络,扩散模型,遥感,卫星图像。

由约瑟夫·加布里埃尔·曼尼(Joseph Gabriel Manion)提交的论文...
为了证明我们方法的效果,我们就各种优化问题进行了多个NU Merical实验。对于每个问题,提供了一组来自未知可行集合的可行决策,我们生成了一个不可行的决定的人工数据集,这些决策在于使用我们的MCMC算法的已知多面体放松的组成。然后,我们训练分类器以学习可行数据集和不可行的数据集之间的分离边界。我们将我们的方法与几个未加剧的密度估计基线进行了比较,这些密度估计基线不会与补体中采样的数据相比。使用模拟的分数背包问题,我们表明我们的方法对于创建分类器至关重要,即(i)在需要可行和不可行区域之间的紧密分离边界时表现良好; (ii)当可行决策的数据集很小时。此外,我们考虑了所有Miplib [14]实例的线性性放松,少于80个变量,并证明我们基于抽样的分类器显着胜过所有基线模型。我们的实验代码可在https://github.com/rafidrm/mcmc-compomplement上找到。

数据增强管道生成合成...
由于隐私问题和医学成像领域中公开可用的标记数据集的摘要,我们提出了图像生成管道,以合成具有相应地面真实标签的3D超声心动图图像,以减轻数据收集的需求,并需要对艰苦的和错误的人类标记,以实现深入学习(DL)的图像的艰苦和错误的人类标记。所提出的方法利用心脏的详细解剖分段作为地面真实标签来源。此初始数据集与由真实3D超声心动图图像组成的第二个数据集结合使用,以训练生成的对抗网络(GAN),以合成现实的3D心血管超声图像与地面真相标签配对。为了生成合成3D数据集,训练有素的GAN使用计算机断层扫描(CT)的高分辨率解剖模型作为输入。对合成图像的定性分析表明,心脏的主要结构被很好地描述,并紧随从解剖模型中获得的标记。为了评估这些合成图像在DL任务中的可用性,对分割算法进行了培训,可以描绘左心室,左心房和心肌。对由合成图像训练的模型给出的3D分割的定量分析
生成数据增强改善涂鸦 -
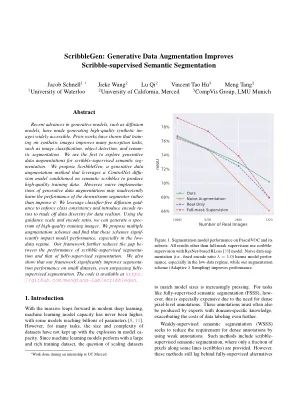
生成模型(例如扩散模型)的最新进展使生成高质量的合成IMEGES可以广泛访问。先前的工作表明,对合成图像进行培训可以改善许多感知任务,例如图像分类,对象检测和半分割。我们是第一个探索涂鸦审议语义序列的生成数据增强。我们提出了Scribblegen,这是一种生成数据增强方法,该方法利用ControlNET扩散模型,该模型以语义涂鸦为条件,以产生高质量的训练数据。但是,生成数据增强的幼稚实施可能会无意中损害下游分段的性能,而不是改善它。我们利用无分类的扩散指南来执行类的一致性,并引入编码ratios来将数据多样性换成数据现实主义。使用指导量表和编码比率,我们可以生成一系列高质量训练图像。我们提出了多个增强方案,并发现这些方案显着影响模型性能,尤其是在低数据状态下。我们的框架进一步减少了涂鸦监督段的性能和完全监督的分割之间的差距。我们还表明,我们的框架显着提高了小数据集上的细分性能,甚至超过了完全监督的细分。该代码可在https://github.com/mengtang-lab/scribblegen上找到。

通过数据增强和
摘要:本研究论文全面介绍了使用先进图像处理和深度学习技术开发和评估脑肿瘤分类模型的研究。本研究的主要目标是利用原始数据集和增强数据集创建一个准确而强大的系统,用于区分脑肿瘤和正常脑图像。该研究以改善医学诊断为重点,旨在利用最先进的机器学习方法来提高脑肿瘤检测的性能。模型流程包括各种图像预处理步骤,包括裁剪、调整大小、去噪和规范化,然后使用 DenseNet121 架构进行特征提取,并使用 S 形激活进行分类。数据集被精心划分为训练、验证和测试集,重点是实现高召回率、精确度、F1 分数和准确度作为主要研究目标。结果表明,该模型取得了令人印象深刻的表现,训练召回率为 92.87%,精确率为 93.82%,F1 得分为 93.15%,准确率为 94.83%。这些发现凸显了深度学习和数据增强在增强脑肿瘤检测系统方面的潜力,支持了该研究的核心目标,即推动医学图像分析在临床应用中的发展。