XiaoMi-AI文件搜索系统
World File Search Systemaware

技术与维和
2021 年 8 月,在印度担任主席国期间,联合国安理会 (UNSC) 通过了一项声明,承认技术在维和中的重要性。在关于“技术与维和”的高级别安理会公开辩论中,印度外交部长 S. Jaishankar 博士表示,“21 世纪的维和必须以强大的技术和创新生态系统为基础”。1 在会议上,联合国秘书长安东尼奥·古特雷斯概述了维和数字化转型战略的要素。当天的另一项重大进展是启动了 UNITE AWARE,这是印度与联合国合作开发的一个技术平台,旨在向联合国维和人员提供地形相关信息,以确保他们的安全。这些发展表明,未来的维和行动将由技术支持。印度对联合国维和行动的这一设想转型表现出真正的热情和兴趣。印度是联合国维和特派团最大的部队派遣国 (TCC),联合国认为印度是最忠诚的维和人员之一。然而,在要求在维和行动中增加使用技术的呼声日益高涨的背景下,问题在于印度能否成为技术贡献国(TecCC)。本文认为,印度应该认真对待技术方面的问题,同时继续其

使用Vader和Bert
摘要:在围绕Omicron疫苗接种的迅速发展的讨论中,该研究利用Twitter的数据,重点关注美国,从2022年3月至2023年3月。利用SNScrape Python库的功能,整理了一条全面的推文数据集,并随后受到严格的情感分析技术。采用了两种主要方法论:Valence Aware Away词典和情感推理器(Vader)和来自变形金刚(BERT)模型的双向编码器表示。数据进行了预处理,其中包括删除URL,HTML标签,提及和停止单词。使用Vader最初标记了这些推文,形成了用于训练BERT模型的基础层。遵循令牌化,数据批处理和模型构建后,对BERT模型进行了训练并随后评估。结果在研究期间与Omicron疫苗相关的讨论中照亮了情绪的多方面景观。此外,确定了可辨别的关系,突出了整个Omicron时期与疫苗相关的Twitter对话中的情感通量。这项研究在大流行的关键时期提供了对公共情绪的宝贵见解,并强调了当代自然语言处理工具在衡量公众舆论中的潜力。

疫苗给药和共同疫苗:审查
•坐着而不是躺下•要注意晕厥(昏厥)•在疫苗接种期间坐下或躺下•注意晕厥之前的症状•如果患者昏昏欲睡,请提供支持性护理并保护患者免受伤害•观察患者(坐下或躺着)至少在疫苗接种后至少15分钟,

西米德兰兹癌联盟更新
The need to be aware of risk of checkpoint inhibitor related type 1 diabetes and myocarditis whilst patients are on these very effective anticancer therapies: Checkpoint blockade immunotherapies are so named because they remove the blockade imposed by molecules such as programmed cell death protein 1 (PD-1) or programmed death ligand 1 (PDL-1) on checkpoints required for T-cell activity: • binding of programmed death-1 (PD-1)及其配体(PD-L1/2)在激活的T细胞中传递一个抑制性信号,从而促进T细胞耗尽,从而导致肿瘤免疫逃避。•转化的细胞可以通过降低抗原表现分子和共刺激分子的表达,或者增加共同抑制性分子的表达(例如编程细胞死亡蛋白1(PD-1))来逃避免疫系统消除,但是,这些抗药性也可能造成抗药性效果。检查点阻滞剂上约有1%的个体由于T细胞活性破坏了胰腺β细胞,因此会产生1型糖尿病,因此会产生胰岛素生产能力。因此,检查点阻滞剂患者的多次多次症和多尿的新发作症状应立即检查血糖和血酮。此外,最近的证据还指出了与检查点阻滞剂相关的心脏毒性,•大约1%的患有免疫检查点抑制剂引起的心脏毒性的患者,心肌炎的死亡率为38%。

策略摘要
» 前进与保护 » AP20 战略 » 聚焦能源 » 全球视野 » 另类使命 » 核心债券使命 » 新兴市场使命 » 国际使命 » 中型股成长使命 » 中型股价值使命 » 实物资产使命 » 小型股成长使命 » 小型股价值使命 » 美国成长使命 » 美国价值使命 » MRI 使命 » 市场领导者 » 成长领导者 » 股息领导者 » 长期增长 » PIMCO 资本保全 » PIMCO 税收意识资本保全 » PIMCO 税收意识增强核心 » PIMCO 收入聚焦 » 精选多/短期 » 短期债券 » 战略收入策略 » 写入收入 » WisdomTree 收入 » WisdomTree 税收意识收入

COVID疫苗同意书
我知道我需要穿着大衣下面穿着宽松的短袖上衣参加。我知道,收到它后需要观察15分钟。我确认我已经阅读了COVID-19辉瑞/Biontech疫苗(包括疫苗的副作用)上的HSE小册子,该疫苗可通过以下任何一个链接获得:


对机器人技术的认识、态度和知识......
The aim of this study was to assess the awareness, attitude, and knowledge of Robotic technologies used in neurorehabilitation among Physiotherapy interns and Professionals across Maharashtra. A cross-sectional study was conducted in tertiary care hospitals and colleges in Maharashtra, India, using a self-made questionnaire. The results showed that 63% of the individuals are moderately aware, 67% have a positive outlook on the implementation of such advances but only 7.5% have accurate knowledge of the technology and its uses. Most of the participants also believe that Robotic Rehabilitation can be very time effective and reduce the load of the therapist as well as play a very important role in aiding neuroplasticity after rehabilitation. The study demonstrated that a higher degree of understanding and a more positive attitude regarding the application of Robotic Rehabilitation follow from heightened awareness of this field. Enhanced training programs, better integration of technology into rehabilitation practices, addressing time constraints and workload prioritization, and most importantly, overcoming economic barriers will ensure the effective implementation of Robotic therapies for the benefit of the patient and society as a whole. This will revolutionize the field of Physiotherapy and rehabilitation, offering new avenues for improving treatment outcomes and advances in clinical practice. The study concluded that, it is important to generate or enhance awareness towards the most-advancing fields and the uses of Robotic technology in neurological conditions in clinical practice which empowers Physiotherapy to adapt to the changing landscape of healthcare and deliver high-quality, patient-centered care. Keywords: Advanced Technology, Artificial Intelligence, Neurorehabilitation, Robotic Physiotherapy, Robotic Rehabilitation, Robotic Technology (RT) ________________________________________________________________________________________________________

在莱索托的两个农村地区患有动脉高血压或糖尿病的成年人的意识,治疗和控制
在莱索托(Lesotho),高血压和糖尿病护理级联反应尚不清楚。我们根据18年的成年人中的高血压和糖尿病的意识,治疗和控制,并确定了与级联的每个步骤相关的因素,这是基于基于人口的,横断面调查的数据,在120个随机抽样的群集中,在Butha-Buthe和Mokhotlong的区域中,从2021年11月1日至31日至31日。我们使用多变量逻辑回归来评估关联。Among participants with hypertension, 69.7% (95%CI, 67.2–72.2%, 909/1305) were aware of their condition, 67.3% (95%CI 64.8– 69.9%, 878/1305) took treatment, and 49.0% (95%CI 46.3–51.7%, 640/1305) were con- trolled.在糖尿病的参与者中,48.4%(95%CI 42.0-55.0%,111/229)意识到其状况,55.8%(95%CI 49.5-62.3%,128/229)接受了治疗,而接受治疗,41.5%(95%CI 35.1-1-1-47.9.9%,95%,95%,95/95/95/95/229)。对于高血压,女性接受治疗的几率(调整后比值比(AOR)2.54,95%CI 1.78–3.61)和受控(AOR 2.44,95%CI 1.76–3.37)比男性。来自城市地区的参与者的治疗几率较低(AOR 0.63,95%CI 0.44-0.90)或受到控制(AOR 0.63,95%CI 0.46-0.85)。沿着高血压和糖尿病护理级联的大量差距表明,对于这些疾病的访问和护理质量不足以确保足够的长期健康结果。
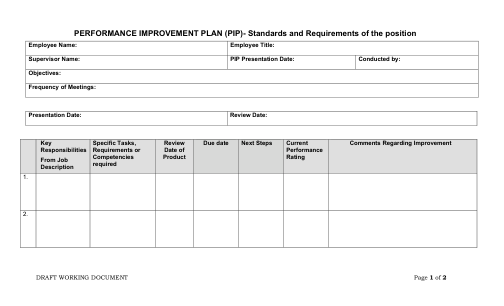
模板 - 绩效改进计划
_____ 我同意评估、评论、行动并已阅读上述绩效改进计划。 _____ 我已获悉评估、评论、行动并已阅读上述绩效改进计划。 _____ 我知道下次审核日期 _______________。 _______________________________________ _______________________________ _____________________ 员工姓名(参与绩效改进计划) 员工签名 日期 _________________________ __________________________________ ________________________________ _____________________ 主管姓名 部门 主管签名 日期