XiaoMi-AI文件搜索系统
World File Search Systembab

稳定海洋:索马里水域 - 同一个地球的未来
在世界上一个战略位置不那么重要的地区,糟糕的海洋管理所造成的问题可能只局限于当地,只影响沿海居民和附近过境的少数国际船只,但非洲之角却绝非偏远。附近的曼德海峡是世界第四大航运咽喉要道,汇聚了印度洋和红海之间的海上交通。非洲和中东冲突地区之间的地缘战略位置为走私者、贩运者和跨国犯罪组织提供了有利可图的机会。广阔的索马里海域拥有丰富的渔业资源,外国渔船队可从中渔获。当地普遍的贫困,加上持续不断的沿海冲突和严重的饥荒,为犯罪组织提供了源源不断的招募者。

全球航运威胁 (WTS) 报告
2024 年 8 月 21 日 (U) 目录:1.(U) 范围说明 2.(U) 警告和建议 3.(U) 摘要 4.(U) 详细信息:按地区划分的每月事件 5.(U) 附录 A:海盗和海上武装抢劫统计和趋势 6.(U) 附录 B:定义和来源 7.(U) 附录 C:有效的美国海事警告 1.(U) 范围说明 (U) 全球航运威胁 (WTS) 报告提供了过去 30 天内全球商船、航运业和其他海事利益相关者面临的威胁信息。本报告主要为商船海员和海军提供信息。2.(U) 警告、咨询和警报:有关有效咨询,请参阅附录 C。(U) 2024 年 8 月 16 日发布了三份美国海事咨询 (2024-008、2024-009 和 2024-010)。这些咨询取代了美国海事咨询 2024-006,并明确了红海、亚丁湾、阿曼湾、阿拉伯海和印度洋面临的具体威胁。有关这些咨询的海事行业问题,请联系全球海事行动威胁响应协调中心 GMCC@uscg.mil。有关美国海事警报和咨询的补充信息(包括订阅详情)可在以下网址找到:https://www.maritime.dot.gov/msci。这些咨询将于 2025 年 2 月 12 日自动到期。A.敌对行动包括单向无人机攻击;无人水面舰艇 (USV) 攻击;弹道导弹和巡航导弹袭击;小船上的小型武器射击;爆炸性船只袭击;以及非法登船、拘留和/或扣押。(U) 美国海事咨询 2024-008:红海南部、曼德海峡和亚丁湾——胡塞武装袭击商船 商船在穿越红海南部、曼德海峡和亚丁湾时,最容易受到胡塞武装的恐怖主义和其他敌对行动的威胁。自 2023 年 11 月 1 日起,
稳定的海洋:索马里水域 - 同一个地球的未来
在世界上一个战略位置不那么重要的地区,糟糕的海洋治理所导致的问题可能只局限于当地,只影响沿海居民和附近过境的少数国际船只,但非洲之角绝非偏远地区。附近的曼德海峡是世界第四大航运咽喉要道,将印度洋和红海之间的海上交通汇集在一起。非洲和中东冲突地区之间的地缘战略位置为走私者、贩运者和跨国犯罪组织提供了有利可图的机会。广阔的索马里海洋环境拥有丰富的渔业资源,可供外国捕鱼船队利用。当地普遍的贫困,现在因持续的沿海冲突和严重的饥荒而加剧,为犯罪组织提供了源源不断的招募者。

http://ejournal.iaingorontalo.ac.id/index.php/jetli issn 2963-9565儿童的第一语言发展:文献评论分析Sitti
摘要本文旨在观察儿童如何获得和发展他们的母语。大多数理论都同意孩子们通过几个步骤获取语言。他们是语言前,bab脚,一句话,两个字,电报和多字阶段。这项研究使用文献综述分析来探讨儿童第一语言发展的详细解释。它基于行为主义者,本土主义者和互动主义者的理论。行为主义者解释说,语言是通过环境调节和模仿成人模型来学习的。本土主义者说,语言是本地的,自然的和天生的,对人类是天生的。每个孩子天生都有一个用于获取语言的“内置”设备。同时,互动主义者说语言是遗传和环境因素的产物。这项研究有助于理解儿童的第一语言和第二语言发展。它可用于概述第二语言学习。关键字:语言发展,儿童语言,文学评论

科学仪器的审查95,013001(2024)。
我们使用紫外线探针激光源介绍了时间和角度分辨光发射光谱的设计详细说明,该光发射光谱结合了β-BAB 2 O 4和KBE 2 BO 3 F 2光学晶体的非线性效应。可以在6.0和7.2 eV之间切换探针激光器的光子能,并具有在两种不同的分辨率配置下操作每个光子能量设置的灵活性。在完全优化的能源分辨率配置下,我们达到了6.0 eV时的8.5 MeV,在7.2 eV时达到10 meV。另外,切换到其他配置可以增强时间分辨率,从而产生6.0 eV的72 fs的时间分辨率,而为7.2 eV的时间分辨率为185 fs。我们通过将系统应用于测量两种典型材料来验证系统的性能和可靠性:拓扑绝缘子MNBI 2 TE 4和激子绝缘子候选者TA 2 NISE 5。

齐玛姆奖学金
Qimam 第六次迭代于 2023 年 1 月正式启动,得到了 +40 家国内外领先组织的大力支持——麦肯锡公司、Aberkyn、Abuhimed Alsheikh Alhagbani 律师事务所 (AS&H) 与 Clifford Chance、Al Arabiya 新闻频道、Al-Khaleejiah 广告与公共关系公司、Arabnet、Bab Rizq Jameel、Banque Arabian、宝马、Bupa Arabia、Careem、思科、Elm、通用电气、Khoshaim & Associates、Khwarizmi Ventures、费萨尔国王专科医院和研究中心 (KFSH&RC)、光辉国际、沙特阿拉伯矿业公司“Ma'aden”、Majid Al Futtaim、微软、Noon、Noon Academy、奥拉扬集团、Oqal、培生、Qiddiya、Raed Ventures、Rawabi Holding、Rocket Internet、SAP、Sary、Seera Group Holding、沙特制药工业与医疗器械公司(SPIMACO)、沙特电信公司(STC)、沙特证券交易所(Tadawul)、STV、Udacity、Unifonic、谷歌、飞利浦和宝洁——以及来自公共和私营部门的无数高级领导人。

一种用于机器人臂和刚体的基于量子计算的新算法
1机械工程系,魁北克大学氢和研究所的机械工程系,3351 BOULEVARD DES FORGES,TROIS-RIVIères,QC G8Z 4M3,加拿大,电子邮件,电子邮件:nadjet.zioui@uqqtr.ca 2 Ezzouar,16111年,阿尔及利亚,阿尔及利亚,电子邮件:yousra.mahmoudi@uqtr.ca 3城市液压部,国立液压学院Arbaoui Abdallah,29号,布里达路线29,阿尔及利亚4Véo4Véo项目,Sherbrooke,Sherbrooke,2500 de l'电子邮件:aicha.mahmoudi@usherbrooke.ca 5流程控制实验室,国家理工学院,阿尔及利亚,阿尔及利亚,电子邮件:mohamed.tadjine@g.enp.enp.edu.dz 6工程与科学学院,挪威西部挪威大学应用科学大学,北挪威大学,北北,5063,5063,Email,电子邮件: say.bentouba@hvl.no

下载-PPID Kemenkes-卫生部
Strategic Targets 11: Strengthening National Health Financing Effectively, efficiently and fairly to achieve Universal Health Coverage (UHC) …………………………………………………………………………………………………………………………………………… Health ……………………………………………………………………………………… 217 Strategic Targets 14: Increasing the Functional Position and Career System Health HR …………………………………………………………………………………………… 220 Strategic Targets 15: Increasing Health Service System in Integrated and Transparent Health Technology Ecosystems in Supporting Health Policy ...战略17:增加治理善治…………。235 B.预算实现……………………………………………………………………………………………………241 C.绩效效率……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………… 283第四章关闭…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………241 C.绩效效率………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………283第四章关闭…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………

德国联邦议院文件 20/10347 联邦政府要求德国武装部队参加由欧盟领导的 EUNAVFOR ASPIDES 行动
1.德国联邦议院16日批准联邦政府提出的建议。2024年2月,德国武装部队决定参加由欧盟主导的在曼德海峡和霍尔木兹海峡以及红海、亚丁湾、阿拉伯海、阿曼湾和波斯湾的国际水域进行的“欧洲海军阿斯匹德”行动。2.国际法和宪法基础 德国武装部队的参与基于 a) 欧盟理事会第 8 号决议 2024/583/CFSP 号。2024 年 2 月及其后续决议实质上延续了该决议; (b) 联合国安全理事会第 2216(2015)号、第 2624(2022)号、第 2707(2023)号和第 2722(2024)号决议; (c)1982年《联合国海洋法公约》; (d) 《制止危及海上航行安全非法行为公约》2005年议定书; (五)一般国际法规则,特别是习惯国际法承认的自卫权,以抵御针对本国或外国船舶和船员的直接非法攻击; (f) 各沿岸国政府同意在其领海内执行该任务。在参加欧盟海军演习时,德国武装部队在基本法第 24 条第 2 款规定的相互集体安全体系框架内和按照该体系规则行事。在欧盟海军ASPIDES框架内部署的所有海上部队均须遵守国际法规定的义务,向海上遇险人员提供援助。3.使命和任务 根据欧盟理事会的决定,欧盟海军ASPIDES的任务是保护作战区域的航行自由和海上交通安全。这包括航运业的安全运输,特别是在红海南部和曼德海峡。
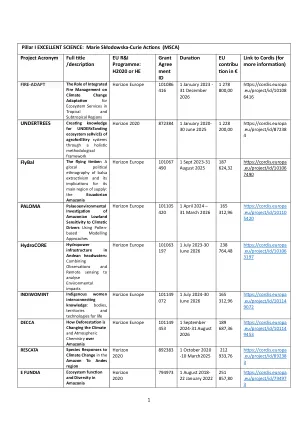
MarieSkłodowska-curie Action(MSCA)项目首字母缩写完整...
Several other projects under Pillar II of the EU Research and Innovation Programme, for example in the field of Nature-Based Solutions, biodiversity, or the bioeconomy are not specifically devoted to Amazon but present some links, such as RUSTICA ( https://cordis.europa.eu/project/id/101000527 ), CLEVER CITIES ( https://cordis.europa.eu/project/776604),ConnectingNature(https://cordis.europa.eu/project/project/project/project/project/730222),conexus(https://cordis.europa https://cordis.europa.eu/project/ID/101003777),BiodivScen(https://cordis.europa.eu/project/project/project/proptiment/7766617),biomonitor4cap(https://cordis.europa.eueropa.euupro/propa.euuu ny76.euupa infropa ny6.euiupa ny76 in https://cordis.europa.eu/project/yid/869226),在LAC(https://cordis.europa.eu/project/project/project/project/101004572)中富集,eupolis(eupolis) (https://cordis.europa.eu/project/id/775983),Interlacetc4be(https://cordis.europa.eu/project/project/project/project/869324),Microbiobiomesuppor(MicrobioMesuomesuppor) (https://cordis.europa.eu/project/ID/101003765),MultiSource(https://cordis.europa.eu/project/project/project/project/project/project/101003527)transpath(https:// https:/cordis.europa.europa.eu/proprab/proproprab/proprab/proprab/proprab/bab and unbab (https://cordis.europa.eu/project/id/730052)等。