XiaoMi-AI文件搜索系统
World File Search Systembenchmark

验证、确认和基准报告 - CORE
执行摘要 NASA 应用科学计划旨在通过与合作机构和相关决策支持工具 (DST) 建立联系,将 NASA 数据、模型和知识转移到最终用户手中。通过 NASA REASoN(研究、教育和应用解决方案网络)合作协议,海军研究实验室海洋学部 (NRLSSC) 正在通过将 NASA 地球-太阳系统资产的数据与沿海海洋预报模型和其他可用数据相结合来开发新产品,以加强墨西哥湾的沿海管理。这项研究工作的受助联邦机构是美国国家海洋和大气管理局 (NOAA)。本报告的内容详细介绍了通过展示如何使用 NASA 卫星产品与数据同化海洋模型相结合,为墨西哥湾的海上用户和沿海管理者提供近乎实时的信息,进一步实现 NASA 应用科学计划的目标。这项工作为监测、评估和预测沿海环境提供了新的和改进的能力。沿海管理人员可以通过联邦、州和地方机构增强的 DST 来利用这些能力。该项目解决了沿海管理人员面临的三大问题:1) 有害藻华 (HAB);2) 缺氧;3) 淡水流入沿海海洋。一套能够描述“海洋天气”的海洋产品每天都会组装起来,作为这项半运营多年工作的基础。这种连续的实时能力为决策者带来了一种新能力,使他们能够通过稳定的卫星和海洋模型条件流来监测正常和异常的沿海海洋条件。此外,随着基线数据集的使用越来越广泛,客户名单也越来越多,客户反馈也越来越多,决策者可以开发和提供额外的定制产品。研究人员和客户之间需要不断提供客户反馈,并针对新的改进产品做出响应。本文档详细介绍了这些沿海海洋产品的生产方法,包括数据流、分发和验证。产品应用以及这些产品在 NOAA 内成功使用的程度以及与密西西比州海洋资源部 (MDMR) 的协调程度均已达到基准。

用于GPU加速基因组分析的基准套件
摘要 - 基因组分析是对基因的研究,其中包括对基因组特征的识别,测量或比较。基因组学研究对我们的社会至关重要,因为它可以用于检测疾病,创建疫苗和开发药物和治疗方法。作为具有大量并行处理能力的一种通用加速器,GPU最近用于基因组学分析。开发基于GPU的硬件和软件框架用于基因组分析正在成为一个有希望的研究领域。为了支持这种类型的研究,需要基准,以具有代表性,并发和多种应用程序的应用程序。在这项工作中,我们创建了一个名为Genomics-GPU的基准套件,其中包含10种广泛使用的基因组分析应用。它涵盖了DNA和RNA的基因组比较,匹配和聚类。我们还调整了这些应用程序来利用CUDA动态并行性(CDP),这是一个支持动态GPU编程的最新高级功能,以进一步提高性能。我们的基准套件可以作为算法优化的基础,也可以促进GPU架构开发进行基因组学分析。索引术语 - 基因组学,生物信息学,基准测试,GPU,加速计算,基因组分析,计算机体系结构。I。研究基因组序列分析是指组织ISM的DNA序列的研究。该程序具有许多重要的应用,例如大流行爆发追踪,早期癌症检测[79],药物发育[43]和遗传疾病鉴定[87]。要通过通过四个字母(A,C,T和G)(也称为碱基或核苷酸)的字符串的形式将DNA分子通过分析生物体的基因组构成分析。确定碱基序列的过程称为基因组测序[30]。比较和发现生物学序列之间差异的过程称为序列比对[67]。过去十年中,基因组数据库的指数增长,需要在计算工具的帮助下进行大量数据。结果,已经开发了几种用于基因组分析的工具,例如BLAST [57]和GATK [58]。为了提高性能,某些基因组测序框架(例如Parasail [31]和KSW2 [53])采用了具有SIMD能力的CPU。他们利用SIMD指令提供的并行性来执行矩阵计算,通过在多个操作数中运行同一矢量命令。FPGASW [39]使用FPGA中的大量执行单元创建线性收缩期

纳米孔测序的多任务基准数据集
纳米孔测序是第三代测序技术,具有生成长阅读序列并直接测量DNA/RNA分子的修改,这使其非常适合生物学应用,例如人类端粒对象至tomemere(T2T)基因组组装,Ebola Virus Surveillance和Covid-19 Mrna vaccine vaccine vacine vaccine vacine vaccine vaccine vaccine vacine。但是,纳米孔测序数据分析的各种任务中计算方法的准确性远非令人满意。例如,纳米孔RNA测序的碱基调用精度约为90%,而目标的基础精度约为99.9%。这凸显了机器学习社区的迫切需要。一种阻止机器学习研究人员进入该领域的瓶颈缺乏大型集成基准数据集。为此,我们提出了纳米巴塞利布(Nanobaselib),这是一个综合的多任务台上数据集。它将16个公共数据集与纳米孔数据分析中的四个关键任务进行了超过3000万个读取。为了促进方法开发,我们已经使用统一的工作流进行了预处理所有原始数据,并以统一的格式存储了所有中级结果,分析了针对四个基准测试任务的各种基线方法分析的测试数据集,并开发了一个软件包来轻松访问这些结果。纳米巴斯利布可在https://nanobaselib.github.io上找到。

6D SLAM
科学研究有益于结果可重复且易于与替代溶液相媲美。例如,在计算机科学和机器人技术中,ImageNet [1]或MS-Coco [2]等计算机视觉基准取得了巨大进展。一个关键特征是,它们将视觉感知分解为从单一的,裁剪的框架标记到检测多个对象的困难的任务。这些基准肯定与(深)学习的复兴相吻合,并且可能在第一个位置启用了它[2]。机器人技术中存在多个基准的区域正在抓住和/或bin拾取[3] - [5]; [6,选项卡中讨论了更多内容。1]。尤其是DEX-NET [5]共同开发了用于掌握计划的新颖解决方案,并通过发布培训和评估数据集来改进它们。在运动计划社区中,仅建立了一些基准,例如,开放运动计划库(OMPL)[7],[8] 1或Parasol 2的创建者。这些要么仅限于简单的点对点计划,要么仅包含没有特定应用程序的抽象计划问题。相比之下,专门用于特定用例的基准套件是自主驾驶[9]或MotionBenchmaker进行操作运动计划[6]的公共路。但是,对于给定任务评估最佳机器人或模块化机器人组件的基准套件不存在。我们提供第一个基准套件来比较不同现实世界环境中的机器人和模块化机器人组件的各种成本功能。示例解决方案

基准储备容量价格成本
3. 制定资本成本估算 9 3.1 估算限定条件和排除条件: 9 3.2 供应和交付成本 10 3.2.1 电池模块/外壳 10 3.2.2 电力转换系统 (PCS) 10 3.2.3 设备平衡(材料和设备) 10 3.2.4 材料供应成本汇总 10 3.3 建设成本 10 3.3.1 场地准备施工合同 10 3.3.2 主体工程施工合同 11 3.3.3 建设成本汇总 11 3.4 输电连接 11 3.5 土地成本 11 3.6 连接协议和市场注册成本 12 3.6.1 网络连接协议 12 3.6.2 市场注册和储备容量认证 13 3.6.3 ERA 许可 13 3.6.4 连接协议、市场注册成本汇总 14 3.7 环境和开发审批14 3.7.1 环境保护法审批 15 3.7.2 开发审批 15 3.7.3 开发审批条件 16 3.7.4 建筑审批 16 3.7.5 危险品许可证 17 3.7.6 审批成本汇总 17 3.8 业主方工程和施工管理和支持 18 3.9 业主间接成本 18 3.10 应急费用 19 3.11 总成本汇总 19
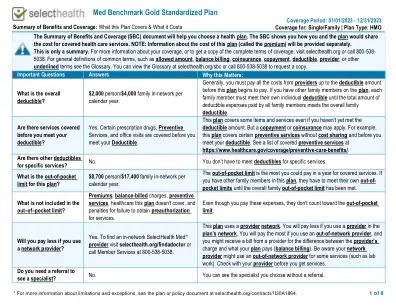
Med Benchmark 黄金标准化计划
您的申诉和上诉权利:如果您对您的计划因索赔被拒而提出投诉,有些机构可以为您提供帮助。这种投诉称为申诉或上诉。有关您的权利的更多信息,请查看您将获得的医疗索赔福利说明。您的计划文件还提供了完整的信息,以便您以任何理由向您的计划提交索赔、上诉或申诉。有关您的权利、本通知或援助的更多信息,请联系:劳工部雇员福利保障管理局,电话 866-444-EBSA (3272) 或 dol.gov/ebsa/healthreform;或者如果您的保险是全额保险,您也可以联系犹他州保险部、消费者援助办公室,地址:犹他州盐湖城州办公大楼 3110 室,邮编:84114。
举报和事件管理基准报告
Northstar 系列是 NAVEX 精心策划的专有数据和无与伦比的分析见解合集。在这个系列中,我们探索与定制数据相结合的突破性分析,以塑造风险和合规领域的战略决策。
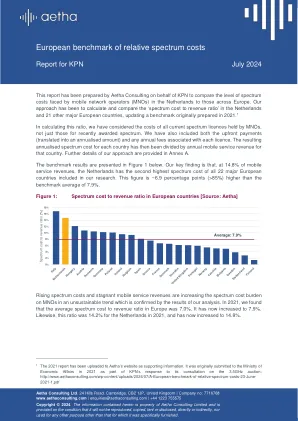
相对频谱成本的欧洲基准
在计算此比率时,我们考虑了MNO持有的所有当前频谱许可的成本,而不仅仅是最近授予的频谱的成本。我们还包括了前期付款(转化为年度数量)和与每个许可证相关的年度费用。随后,每个国家 /地区的年度频谱成本已由该国的年度移动服务收入分开。附件A中提供了我们方法的更多详细信息。

使用图的大脑网络分析的基准
人的大脑是复杂的神经生物学系统的核心,其中神经元,电路和子系统在策划行为和认知方面进行了研究。神经科学的最新研究表明,大脑区域之间的相互作用是神经发育和疾病分析的关键驱动因素[1,2]。使用结构或功能连通性映射人脑的连接组已成为神经成像分析最普遍的范式之一。重新说,从地理深度学习中动机的图形神经网络(GNN)由于其建模复杂的网络数据建模而引起了广泛的兴趣。在文献中,功能和结构联系被广泛认为是用于大脑调查的有价值的信息资源[3]。但是,他们主要在特定的私人数据集上对其建议的模型进行实验。由于道德问题,通常无法公开使用的数据集,并且未披露成像预处理的详细信息,从而使其他研究人员无法重新调查实验。目前尚未进行有关如何设计有效GNN用于脑网络分析的系统研究。为了弥合这一差距,我们提出了BraingB,这是一种用于GNNS的大脑网络分析的基准,并于2023年在IEEE-TMI上发表[4]。1。我们在同类和模式的四个数据集上进行实验,并建议一组在大脑网络上进行有效GNN设计的食谱。基于这四个维度的不同组合作为基准,我们的贡献是四个方面:•建立了一个统一,模块化,可扩展和可重复的框架,用于使用GNN进行大脑网络分析,以实现可重复性。它旨在通过可访问的数据集,标准设置和基线来启用公平评估,以促进计算神经科学和其他相关社区中的协作环境。•我们总结了功能和结构性大脑网络的预处理和施工管道,以弥合神经影像学和ML社区之间的差距。•我们将基于GNN的大脑网络分析的感兴趣的设计空间分解为四个模块:(1)节点feapers,(b)消息通讯机制,(c)注意机制和(d)汇总策略。

neo4j安全基准版本4.4.36 3 ...
1。https:/thlo4j.com/docs/-opertational/4/4/25010013/in-https://support.neo4j.com/hc/hc/en-us/articles/203306363636-dehind