XiaoMi-AI文件搜索系统
World File Search Systembenchmark

彭博主题基准索引方法
彭博主题基准指标的焦点系列(如附录A中的串联列中所述),通过其黄金或银层(黄金更好),然后通过收入评估(按上升顺序)对符合条件的证券进行分类,然后由发行人的自由浮子市值(以降级为单位)。彭博指数服务有限公司(BISL)根据彭博主题协议将证券置于黄金或银层。请参阅彭博主题协议,以获取有关黄金或银层确定以及收入评估的更多信息。选择属于黄金层的所有证券都被选为包容。如果所选证券的数量少于20,则选择排序列表中的下一个证券以纳入为止,直到指数具有20个证券为止。

迈向计算室内声学的基准
过渡到操作系统,举办了两次混响建模研讨会 - RMW - 最后一次是在 2008 年 5 月。RMW 的基本目标是提供明确定义的问题和一致的解决方案,以支持新模型的验证和确认、海军标准模型的升级以及基于混响数据的地声反演技术。设计研讨会的基本问题是,即使是海军感兴趣的最简单的混响问题也没有闭式解,而且仍然 - 本质上 - 超出了我们使用标准“精确”数值技术解决的计算能力。所有当前实用的水下混响模型都通过使用散射和损失函数或表格来取代物理问题。我们讨论了一系列定义明确的问题(基于物理),具有等效的损失/散射输入,复杂性有所增加。我们还讨论了在此过程中获得的经验教训,并指出了研讨会的一些意外结果,并为未来的基准研讨会提出了建议。� 海军研究办公室支持的工作。�

mlbench:机器学习基准问题
as.data.frame.mlbench。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。2贝斯班。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 3 Bostonhouse。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。2贝斯班。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。3 Bostonhouse。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。3 Bostonhouse。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。3个破解。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>5 DNA。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 6杯。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div>5 DNA。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>6杯。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div>6杯。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。。。。。。。。。。8 housevotes84。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。9电离层。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 10个字母认可。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。9电离层。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10个字母认可。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。12 mlbench.2dnormals。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 mlbench.cassini。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。14
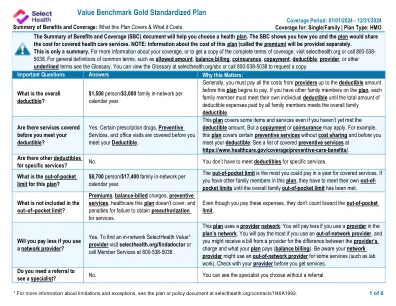
价值基准黄金标准化计划
您的申诉和上诉权利:如果您对拒绝索赔的计划提出投诉,则有一些机构可以提供帮助。此投诉称为申诉或上诉。有关您的权利的更多信息,请查看您将获得该医疗要求的福利的解释。您的计划文件还提供完整的信息,以提交索赔,上诉或申诉。有关您的权利,本通知或协助的更多信息,请联系:劳工部的员工福利安全管理局,电话866-444-EBSA(3272)或dol.gov/ebsa/healthreform;或者,如果您的承保范围得到了全部保险,您也可以联系犹他州保险部,消费者援助办公室,套房3110,州办公室大楼,盐湖城,犹他州84114。
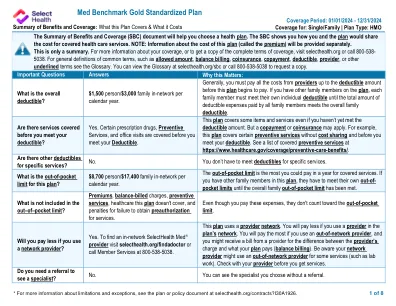
MED基准黄金标准化计划
您的申诉和上诉权利:如果您对拒绝索赔的计划提出投诉,则有一些机构可以提供帮助。此投诉称为申诉或上诉。有关您的权利的更多信息,请查看您将获得该医疗要求的福利的解释。您的计划文件还提供完整的信息,以提交索赔,上诉或申诉。有关您的权利,本通知或协助的更多信息,请联系:劳工部的员工福利安全管理局,电话866-444-EBSA(3272)或dol.gov/ebsa/healthreform;或者,如果您的承保范围得到了全部保险,您也可以联系犹他州保险部,消费者援助办公室,套房3110,州办公室大楼,盐湖城,犹他州84114。

结构计划0334 Golden Bay
一些利益相关者认为应在定义事件后进行审查。Synergy认为,当可用性持续时间差距或排放阈值发生变化时,应审查基准能力提供商。AEMO认为,当ESR持续时间需求发生变化时,以及在此期间更有效的存储或发电技术类型时,更频繁的评论可以捕获。CEC认为,应根据协调员和MAC建立的标准提早触发评论。

2024 年现场服务基准报告
• 全球范围内,77% 的雇主表示难以找到组织所需的熟练人才。1 • 到 2031 年,超过四分之一的劳动力将年满 55 岁。² ○ 现场服务行业面临更大的挑战:在北美,46% 的现场技术人员年龄超过 50 岁。³ ○ 为了提高绩效,公司必须了解组织的方方面面。如果仔细观察,就会发现这些信息是存在的 — 它隐藏在数据中。但很难在分散在不同来源的信息中找到意义。• 超过 25% 的服务领导者表示,“提取和分析数据以了解组织绩效”是他们在 2023 年面临的最困难的挑战。⁴ • 只有 7% 提供多种服务渠道的联络中心可以通过向下一个代理或系统提供数据、历史记录和上下文,在渠道之间无缝转换客户。⁵

利特尔顿市经济基准报告
这份由 Jon Stover & Associates 和 Future iQ 合作开发的情境分析报告,概述了利特尔顿市当前的经济状况。重要的是,这份快照是创建 CEDS 时可以利用的工具,反映了未来几个月将参考和提炼的见解。该分析利用了领先的经济数据来源,包括美国人口普查、美国劳工统计局、Infogroup、先前的研究和区域经济发展合作伙伴。

警报疲劳预防基准项目
这个MSN Capstone项目是由UT Tyler的Scholar Works的护理带给您的。已被Ut Tyler的学者工程授权管理员所接受,将其纳入MSN Capstone项目。有关更多信息,请联系tgullings@uttyler.edu。

基准5版,2024年9月
2024年8月,澳大利亚国家临床质量注册框架2024由澳大利亚卫生保健安全与质量委员会(委员会)发布,标志着2014年原始版本的重大更新。该框架支持CQR在收集,分析和报告临床数据方面,以最大程度地提高澳大利亚临床数据的价值。它与澳大利亚政府针对2020 - 2030年临床质量注册机构和虚拟注册机构的国家战略保持一致,最终导致澳大利亚的患者结果更好。