XiaoMi-AI文件搜索系统
World File Search Systembenchmark

为什么澳大利亚基准报告2024
注意:1。测量为GDP的百分比。各个国家的税收制度差异很大,这使得直接比较很困难。经合组织使用的一种简单措施是考虑经济的总“税收”。按市场价格以市场价格,税收(或税收负担)是总税收与GDP的比率。这个比率是对一个国家税收的广泛衡量,该税率削减了各个基础,费率和阈值。2。社会保障捐款/税款是“支付给普通政府的强制性付款,授予获得(或有)将来的社会利益的权利”。,例如,失业保险或家庭津贴。社会保障捐款通常不仅征收雇主,而不仅征收雇员。3。括号中的数字表示该国在OECD成员中的排名。
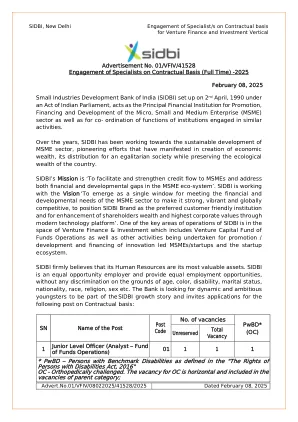
* PWBD - 定义的基准残疾人...
小型工业发展银行(SIDBI)于1990年4月2日根据印度议会的法案成立,是微型,中小型企业(MSME)部门的促进,融资和发展的主要金融机构,以及从事类似活动的机构的合作。多年来,Sidbi一直在努力实现MSME部门的可持续发展,开创性的努力在创造经济财富方面表现出来,其分配给平等社会,同时保留了该国的生态财富。Sidbi的使命是“促进和加强向MSMES的信贷流程,并解决MSME生态系统中的财务和发展差距”。sidbi正在与愿景“成为一个单一的窗口,可以满足MSME行业的财务和发展需求,以使其使其强大,充满活力且具有全球竞争力,以将Sidbi品牌定位为首选客户友好的机构,并通过现代技术平台来增强股东财富和最高公司价值观。Sidbi的主要运营领域之一是风险投资和投资领域,其中包括风险投资基金基金运营以及为促进 /开发和创新筹集的其他活动LED MSMES / Startups和创业生态系统。Sidbi坚信其人力资源是其最有价值的资产。Sidbi是一个平等的机会雇主,并提供平等的就业机会,而没有任何歧视,颜色,残疾,婚姻状况,国籍,种族,宗教,性别等。该银行正在寻找动态和雄心勃勃的年轻人成为Sidbi增长故事的一部分,并邀请以下申请以以下合同:

量子启发式求解器的基准......
最近,受量子退火的启发,许多专门用于无约束二元二次规划问题的求解器已经开发出来。为了进一步改进和应用这些求解器,明确它们对不同类型问题的性能差异非常重要。在本研究中,对四种二次无约束二元优化问题求解器的性能进行了基准测试,即 D-Wave 混合求解器服务 (HSS)、东芝模拟分叉机 (SBM)、富士通数字退火器 (DA) 和个人计算机上的模拟退火。用于基准测试的问题是 MQLib 中的真实问题实例、随机不全相等 3-SAT (NAE 3-SAT) 的 SAT-UNSAT 相变点实例以及 Ising 自旋玻璃 Sherrington-Kirkpatrick (SK) 模型。对于 MQLib 实例,HSS 性能排名第一;对于 NAE 3-SAT,DA 性能排名第一;对于 SK 模型,SBM 性能排名第一。这些结果可能有助于理解这些求解器的优点和缺点。

AMB2025-01基准测量和挑战问题
•基准挑战CHAL-ABS2025-01-SR:预测平均固体尺寸,平均最大和最小隔离的NB和MO在细胞壁和细胞内部的NB和MO的质量分数,以及在AS-Buuguign微型结构中不包括氧化物的沉淀物的体积分数。预测在870°C的应力释放热处理1小时后,在微观结构中的沉淀物的体积分数(不包括氧化物)。 •基准挑战CHAL-BAMB2025-01-H:在细胞壁和细胞内部的NB和MO分别预测NB和MO的平均固定细胞大小,平均最大和最小隔离质量分数,以及在构造的微观结构中排除氧化物的沉淀物的体积分数。预测在1150°C均质热处理1小时后,在微观结构中的沉淀物的体积分数,不包括氧化物。

Cy-Bench:一个用于子...
1 Wageningen University and Research,人工智能,邮政信箱16,Wageningen,6700 AA,荷兰。皮埃尔·维亚拉(Pierre Viala),蒙彼利埃(Montpellier),34000,法国17莱布尼兹农业景观研究中心,模拟和数据科学,埃伯斯瓦尔德·斯特劳斯(EberswalderStra笔环境研究,计算水系统系,珀索斯特拉赛15号,莱比锡,04318,德国20欧盟委员会联合研究中心,粮食安全部门,E.Fermi 2749,ISPRA,VA I-21027,意大利2 Technical University of Munich, Chair of Data Science in Earth Observation, Arcisstraße 21, Munich, 80333, Germany 3 Purdue University, Department of Agronomy, 915 Mitch Daniels Blvd, West Lafayette, IN 47907, United States 4 Ankara University, Faculty Of Agriculture Engineering, Dögol Caddesi 06100 Tando˘gan, Ankara, 6110,土耳其5马里兰大学,地理科学系,7251 Preinkert Drive,Collega Park,MD 20742,美国6 NASA戈达德太空研究所,GISS气候影响小组,邮件代码611,纽约,纽约10025,纽约,10025 Vrije Universiteit Amsterdam,环境研究研究所,DE BOELELAAN 1105,阿姆斯特丹,1081 HV,荷兰9 Potsdam气候影响研究所,气候弹性研究部,PO Box 60 12 03,Potsdam,Potsdam,4412,德国10,Manitoba University of Manitoba University of Manitoba,Winn winn winn winn 5V6, Canada 11 Universitat de València, Image Processing Laboratory, C/ Catedràtic Agustín Escardino Benlloch, 9, València, 46980, Spain 12 Seidor Consulting, C/Provençals 44, Barcelona, 08019, Spain 13 International Crops Research Institute for the Semi-Arid Tropics, West and Central Africa Region Hub, PO Box 320,巴马科,马里14国际热带农业研究所,自然资源管理,邮政信箱30677,内罗毕,00100,00100,肯尼亚15联邦科学与工业研究组织(CSIRO),农业和食品,147 Underwood Wood Wood,珀斯,澳大利亚6014,澳大利亚16号,澳大利亚16号国家研究所,国家研究所,国家研究所农业研究所,农业和环境。
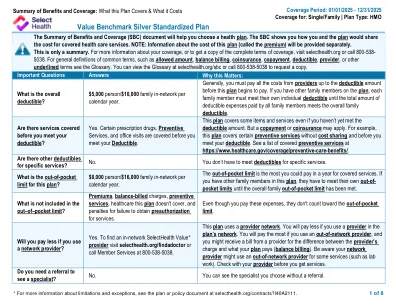
价值基准银标准化计划
您的申诉和上诉权利:如果您对拒绝索赔的计划提出投诉,则有一些机构可以提供帮助。此投诉称为申诉或上诉。有关您的权利的更多信息,请查看您将获得该医疗要求的福利的解释。您的计划文件还提供完整的信息,以提交索赔,上诉或申诉。有关您的权利,本通知或协助的更多信息,请联系:劳工部的员工福利安全管理局,电话866-444-EBSA(3272)或dol.gov/ebsa/healthreform;或者,如果您的承保范围得到了全部保险,您也可以联系犹他州保险部,消费者援助办公室,套房3110,州办公室大楼,盐湖城,犹他州84114。

人工智能辅助视频编辑的数据集和基准套件
摘要。机器学习正在改变视频编辑行业。计算机视觉领域的最新进展提升了视频编辑任务的水平,例如智能重构、转描、调色或应用数字化妆。然而,大多数解决方案都集中在视频处理和视觉特效上。这项工作引入了视频编辑的解剖结构、数据集和基准,以促进人工智能辅助视频编辑的研究。我们的基准套件专注于视频编辑任务,而不仅仅是视觉效果,例如自动素材组织和辅助视频组装。为了在这些方面开展研究,我们从电影场景中采样的 196176 个镜头中注释了超过 150 万个标签,其中包含与电影摄影相关的概念。我们为每个任务建立了有竞争力的基线方法和详细的分析。我们希望我们的工作能够激发对人工智能辅助视频编辑的未开发领域的创新研究。代码可在以下位置获得:https://github.com/dawitmureja/AVE.git。

遥感图像场景分类:基准与...
摘要 — 遥感图像场景分类在广泛的应用中发挥着重要作用,因此受到了广泛关注。在过去的几年中,人们做出了巨大的努力来开发各种数据集或提出各种用于遥感图像场景分类的方法。然而,仍然缺乏有关场景分类数据集和方法的文献的系统综述。此外,几乎所有现有数据集都存在许多局限性,包括场景类别和图像数量规模小、图像变化和多样性不足以及准确性饱和。这些限制严重限制了新方法的发展,尤其是基于深度学习的方法。本文首先对最近的进展进行了全面的回顾。然后,我们提出了一个大规模数据集,称为“NWPU-RESISC45”,这是西北工业大学 (NWPU) 创建的遥感图像场景分类 (RESISC) 的公开基准。该数据集包含 31,500 张图像,涵盖 45 个场景类,每个类有 700 张图像。提出的 NWPU-RESISC45 (i) 在场景类和总图像数量上是大规模的,(ii) 在平移、空间分辨率、视点、物体姿势、照明、背景和遮挡方面具有很大的变化,并且 (iii) 具有很高的类内多样性和类间相似性。该数据集的创建将使社区能够开发和评估各种数据驱动算法。最后,使用提出的数据集评估了几种代表性方法,并将结果报告为未来研究的有用基线。索引术语 — 基准数据集、深度学习、手工制作的特征、遥感图像、场景分类、无监督特征学习。

供应链基准领先工具比较
doyensec进行了三个流行的软件组成分析(SCA)工具(Semgrep,Snyk和Displyabot)的并排比较,以评估其能力,以正确地确定应用程序的第三方库,具有已知漏洞是否在该应用程序中确实引入了可利用的条件。这包括确认不仅包括脆弱的库版本,而且还包括公开披露中所述实际使用的脆弱功能或配置。需要高度准确性,以减少误报的总数,从而减少专业人员所需的整体分式分三名努力。通过手动分析,我们测量了真实和误报,并确定了安全团队来调查工具发现所需的努力水平。

基本健康益处基准计划更新
最近,作为2025 NBPP的一部分,CMS提出了EHB基准计划更新过程的几个更改。拟议的更改将简化申请过程,并可能增加可以添加到华盛顿当前EHB基准计划中的福利的数量和/或丰富性。如果按建议完成,则可以将常规的成人牙科福利视为EHB,并使国家更加灵活地将哪些计划包括在典型性测试中。13这些是拟议的规则,预计将于2024年4月或5月。对将包括在SSB 5388中立法机关的最终规则和明确指示中的政策的不确定性,OIC计划在2024年5月1日或之前提交EHB基准计划更新授予CMS。