XiaoMi-AI文件搜索系统
World File Search Systemclassification

海上船舶分类和建造规则 ...
本规范分为以下几个部分: 第 I 部分“入级”;第 I I 部分“船体”;第 1П 部分“设备、布置和舾装”;第 I V 部分“稳性”;第 V 部分“分舱”;第 V I 部分“防火”;第 V I I 部分“机械设备”;第 V H I 部分“系统和管道”;第 I X 部分“机械”;第 X 部分“锅炉、热交换器和压力容器”;第 X I 部分“电气设备”;第 ХП 部分“制冷装置”;第 ХП1 部分“材料”;第 X I V 部分“焊接”;第 X V 部分“自动化”;第 X V I 部分“玻璃钢船舶和艇的船体结构和强度”;第 X V I I 部分“船舶结构和操作特点的入级符号中的区别标记和描述性符号”;



高速铁路分类与建设规则...
本规范分为下列部分:第 I 部分“入级”;第 II 部分“船体结构和强度”;第 III 部分“设备、布置和舾装”;第 IV 部分“稳性”;第 V 部分“浮力储备和分舱”;第 VI 部分“防火”;第 VII 部分“机械设备”;第 VIII 部分“系统和管道”;第 IX 部分“机械”;第 X 部分“锅炉、热交换器和压力容器”;第 XI 部分“电气设备”;第 XII 部分“制冷装置”;第 XIII 部分“材料”;第 XIV 部分“焊接”;第 XV 部分“自动化”;第 XVI 部分“救生设备”;第 XVII 部分“无线电设备”;第 XVIII 部分“航行设备”;第 XIX 部分“信号装置”;第 XX 部分“防污染设备”;第 XXI 部分“人员运输船舶”。

使用...
1位城市工程学院CSE助理教授2,3,4,5印度班加罗尔城市工程学院的计算机科学与工程学学生。 摘要:人工智能技术的出现刺激了各个领域的创新,废物管理也不例外。 该项目提出了一个基于AI的垃圾检测系统,旨在彻底改变各种环境中废料的识别和分类。 利用先进的计算机视觉和机器学习算法,该系统自动化垃圾检测和分类过程,从而有助于更高效,更可持续的废物管理实践。 计算机愿景的最新进展已为解决围绕废物管理的全球问题开辟了新的途径。 这项研究深入研究了计算机视觉技术,以进行精确的废物分类和识别。 主要目标是开发一种能够准确识别和分类各种废物容器的强大算法。 使用深度学习算法(例如卷积神经网络(CNN),内容提取和分类)。 数据集包含图像,描绘了各种废物类型,包括塑料,纸张,玻璃,金属和有机废物。拟议的系统涉及预处理,特征提取,分类和后处理阶段。 图像增强,归一化和降噪功能在预处理过程中增强了输入图像质量。 使用预训练的CNN模型(例如Resnet,VGG或Mobilenet)提取相关特征。1位城市工程学院CSE助理教授2,3,4,5印度班加罗尔城市工程学院的计算机科学与工程学学生。摘要:人工智能技术的出现刺激了各个领域的创新,废物管理也不例外。该项目提出了一个基于AI的垃圾检测系统,旨在彻底改变各种环境中废料的识别和分类。利用先进的计算机视觉和机器学习算法,该系统自动化垃圾检测和分类过程,从而有助于更高效,更可持续的废物管理实践。计算机愿景的最新进展已为解决围绕废物管理的全球问题开辟了新的途径。这项研究深入研究了计算机视觉技术,以进行精确的废物分类和识别。主要目标是开发一种能够准确识别和分类各种废物容器的强大算法。使用深度学习算法(例如卷积神经网络(CNN),内容提取和分类)。数据集包含图像,描绘了各种废物类型,包括塑料,纸张,玻璃,金属和有机废物。拟议的系统涉及预处理,特征提取,分类和后处理阶段。图像增强,归一化和降噪功能在预处理过程中增强了输入图像质量。使用预训练的CNN模型(例如Resnet,VGG或Mobilenet)提取相关特征。转移学习技术为垃圾分类任务优化了这些模型。分类涉及使用使用优化算法(如随机梯度下降(SGD)和ADAM)进行标记的数据训练改良的CNN模型。诸如非最大抑制(NMS)之类的后处理技术解决了生产预测并消除重复的信号。实验结果证明了该算法在准确分类和识别废物类型方面的有效性,从而对废物管理工作产生了重大贡献。未来的研究指示包括实时实施,可伸缩性以及与机器人系统的集成,用于工业和城市环境中的自主废物管理。关键字:计算机视觉,CNN模型,Python,Yolo模型,优化铝制。

增强垃圾分类的Resnet-50
随着人们的物质生活水平继续提高,房屋的类型和数量 - 持有垃圾的类型和数量迅速增加。因此,迫切需要开发一种合理有效的垃圾分类方法。这对于资源回收和环境改进非常重要,并有助于生产和经济的可持续发展。但是,由于大量模型参数,现有的基于深度学习的垃圾图像分类模型通常会遭受低分类精度,鲁棒性不足和慢速检测速度的影响。为此,提出了一个新的垃圾图像分类模型,并以Resnet-50网络为核心架构。特别是,首先提出了一个冗余特征融合模块,使该模型能够充分利用有价值的功能信息,从而提高其性能。同时,该模块从多尺度功能中滤除了冗余信息,从而减少了模型参数的数量。第二,Resnet-50中的标准3×3卷积被替换为深度分离的卷积,从而显着提高了模式的计算效率,同时保留了原始卷积结构的特征提取能力。最后,为了解决阶级不平衡问题,加权因素被添加到焦点损失中,旨在减轻类不平衡对模型性能的负面影响并增强模型的鲁棒性。trashnet数据集的实验结果表明,所提出的模型有效地减少了大小的数量,提高检测速度并达到94.13%的准确性,超过了现有的基于深度学习的废物图像分类模型的绝大多数,表明其固定实用值。

开发新的TBI分类...
40年来,我在我们的领域看到了许多“海洋变化”。在2007年之前,我们从未想象过,大型公共会对TBI有意识,但是与运动有关的脑震荡和战斗是TBI改变了这一问题。我已经看到,兴趣从仅仅是脑部受伤的脑损伤扩大到其他获得的脑损伤,包括来自药物过量或家庭暴力中的缺氧/缺氧的脑损伤,以及最近的脑损伤,最近,Covid的持续性认知障碍。,但我看到的最重要的转变是认识到,某些脑部损伤需要被视为慢性健康状况,并且像我们对糖尿病,心脏病或COPD一样主动管理。我相信,这种认识是,TBI的长期影响是动态的,而不是稳定的,有可能改善许多生命。Q.Q.

膀胱癌分子分类
摘要背景:为了提高在临床环境中最新发现的使用,建立有关膀胱癌分子分类(BC)的共识至关重要。BC仍然是一个重大的全球公共卫生问题。 它是第十个最常见的癌症和全球癌症相关死亡的第13个主要原因。 正在进行开发非肌肉入侵膀胱癌(NMIBC)和肌肉入侵膀胱癌(MIBC)的分类系统,这是由于治疗方法的显着差异。 结论:我们通过各种科学网站(包括原始论文和临床试验)进行了搜索,以探索膀胱癌的分类旅程和每个亚型的基本原理。 在以下手稿中强调了大多数分子分类,目的是在不久的将来具有改善结果的较不久的未来价值。 迫切需要进一步关注分子分类影响的临床试验,以提高对BC的理解和治疗。 关键词:膀胱癌;分子分类; NMIBC,MIBCBC仍然是一个重大的全球公共卫生问题。它是第十个最常见的癌症和全球癌症相关死亡的第13个主要原因。正在进行开发非肌肉入侵膀胱癌(NMIBC)和肌肉入侵膀胱癌(MIBC)的分类系统,这是由于治疗方法的显着差异。结论:我们通过各种科学网站(包括原始论文和临床试验)进行了搜索,以探索膀胱癌的分类旅程和每个亚型的基本原理。在以下手稿中强调了大多数分子分类,目的是在不久的将来具有改善结果的较不久的未来价值。迫切需要进一步关注分子分类影响的临床试验,以提高对BC的理解和治疗。关键词:膀胱癌;分子分类; NMIBC,MIBC
CS-OHS-73 - 伤害和疾病分类
1 工人必须提前向 CS Energy 充分通知此次受伤或患病情况,以便 CS Energy 在重返工作岗位之前进行风险评估,以确定病情是否进一步恶化。2 出行是指往返 CS Energy 发电站的实际出行。出行不包括 WorkCover QLD 定义的上下班行程。3 员工包括有偿和志愿员工;以及与业务相关的其他人员。4 如果员工因食用被工作场所污染物(如铅)污染的食物而生病,或因雇主提供的食物而食物中毒,则该情况将被视为与工作有关。5 如果员工在工作中感染传染病,则由澳大利亚传染病网络确定的传染病(也称为传染病)应被视为与工作有关
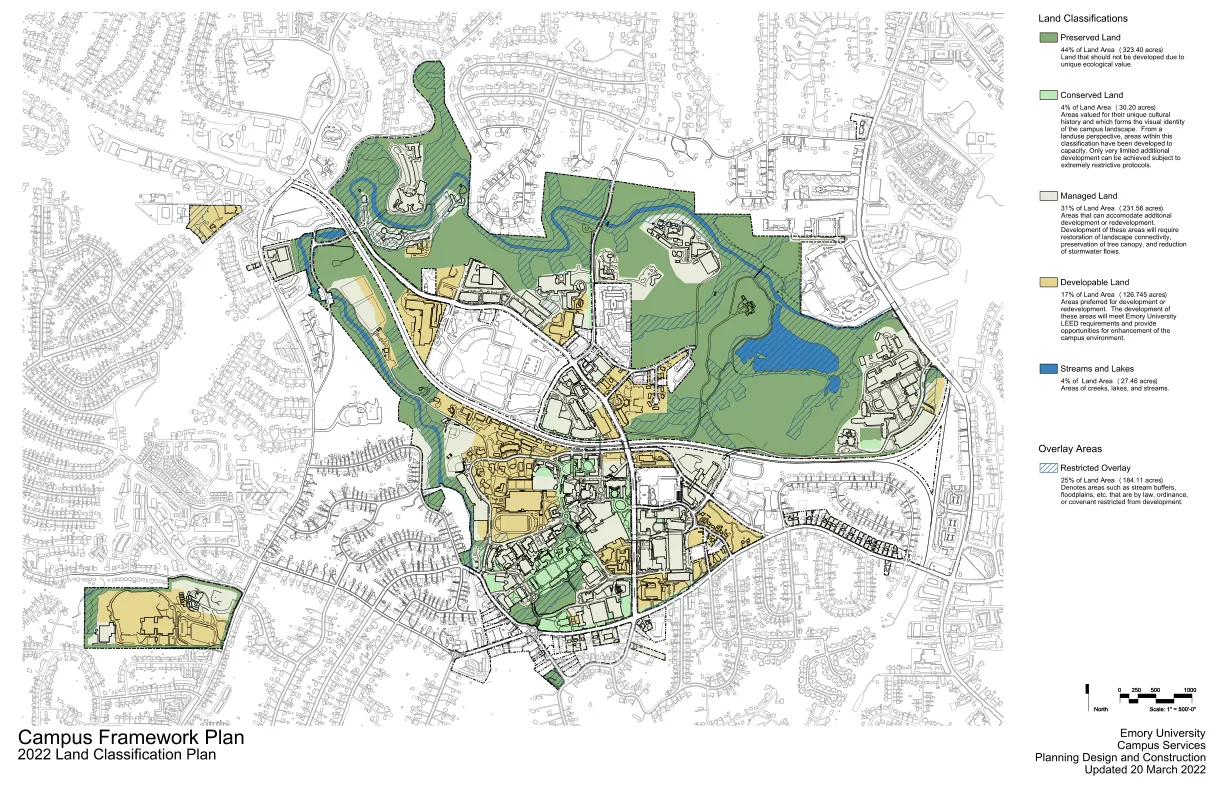
2022 年土地分类规划
极其严格的协议。开发取决于容量。仅对校园景观内的区域进行了非常有限的额外分类。从历史和视觉特征来看,这些区域因其独特的文化价值而受到重视。占土地面积的 4%(30.20 英亩)