XiaoMi-AI文件搜索系统
World File Search Systemcode

选举代码
管理员; (e)选举法官; (f)替代选举法官; (g)早期投票的文员; (h)副副投票职员; (i)选举文员; (j)提前投票委员会的主席法官; (k)提前投票委员会的替代主席法官; (l)早期投票委员会的成员; (m)签名验证委员会主席; (n)签名验证委员会的副主席; (o)签名验证委员会成员; (p)中央计数站的主席法官; (q)中央计数站的替代主席法官; (r)中央计数站经理; (s)中央计数站书记员; (t)制表主管; (u)制表主管的助手; (v)举行初选或初选径流的县政党的主席。(4-B)“联邦法官”的意思是:(a)法官,前法官或美国上诉法院的退休法官; (b)美国地方法院的法官,前法官或退休法官; (c)美国破产法院的法官,前法官或退休法官; (d)一名治安法官,前地方法官或美国地方法院的退休治安法官。(5)“最终画布”是指确定选举正式结果的帆布。(6)“大选”是指除初次选举以外的选举,该选举在固定日期定期出现。(7)“州和县官员的大选”是指联邦,州和县政府的官员当选的大选。(7)“州和县官员的大选”是指联邦,州和县政府的官员当选的大选。


行为准则
Digital Trust Storebrand为我们的客户管理大量信息。同时,由于我们的市场地位,客户,供应商,合作伙伴和员工,我们是几个威胁行为者的有吸引力的目标。该小组有目的地努力创建安全性,保护客户的隐私,并保持其信任,团体的声誉和我们的竞争力。所有技术的使用都应支持这一点。我们将在内部和外部法规的框架内积极使用技术。我们与隐私和信息安全持续合作,以管理风险并增强我们的弹性。我们通过人员,过程和技术来做到这一点。为了保护数字信任,安全和稳定的IT解决方案是先决条件。我们还努力从一开始就将隐私和安全性建立到解决方案中。我们的内部控制可确保我们遵守法律要求,并为我们如何处理信息提供常规和指南。同时,我们设定了严格的要求,并控制我们的合作伙伴和供应商还处理和保护信息
附录 - HMRF在2022年资助的Polyu研究项目
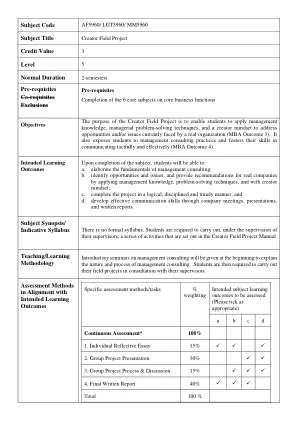
学生将在整个小组项目的进步和讨论中发展创作者的心态(成果3),了解管理层面临的问题并生成声音替代方案以解决有关问题(项目3),并通过书面报告和项目演讲(项目2和4)提供建议。学生还将在准备最终项目报告(项目4)和小组项目演示文稿(项目2)时发展有效的沟通技巧(结果4)。学生可以通过个人反思论文(项目1)来证明个人在学习成果上的成就(成果3和4)。个人表现可以影响或确定个体成绩。


行为准则
§ 1 – Compliance with legal statutes and human rights 6 § 2 – Employee rights 6 2.1 Treating employees with respect and dignity 6 2.2 Working time 6 2.3 Remuneration 8 2.4 Prohibition of child labor 8 2.5 Prohibition of slavery and forced labor 9 2.6 Prohibition of discrimination 9 2.7 Freedom of association 9 § 3 – Work safety 10 § 4 – Conflict minerals 10 § 5 – Environmental protection 11 § 6 – Free competition 12 §7 - 禁止腐败12§8 - 礼物,邀请和娱乐12§9 - 选择供应商13§10 - 洗钱;外贸;付款交易和现金付款交易13§11 - 保护数据和商业机密14§12 - 符合本针对供应商的本行为守则14§13 - 沿整个价值链15


电网代码
图 1 – 乌波卢岛和马诺诺岛的 EPC 电网 ...................................................................................................... 13 图 2 – 萨瓦伊岛的 EPC 电网 ................................................................................................................ 14 图 3 – 逆变器连接电厂的典型发电能力图 ...................................................................................... 19 图 4 – 水力发电机的典型发电机能力图 ...................................................................................... 20 图 5 – 电压支持模式 ...................................................................................................................... 21 图 6 – 电压穿越无跳闸区 ............................................................................................................. 22 图 7 – 发电厂连接配置选项 ...................................................................................................... 24 图 8 – 不带太阳能光伏的典型消费者安装 ............................................................................................. 37 图 9 – 典型的屋顶太阳能光伏电气连接 ............................................................................................. 38 图 10 – 带可选电池的屋顶太阳能光伏 ............................................................................................. 39 图 11 – 逆变器功率输出对频率变化的响应 ................................................................................. 44 图 12 – 逆变器伏特-瓦特模式默认设置 ............................................................................................. 47图 13 – 逆变器电压-无功模式默认设置 ...................................................................................... 49

