XiaoMi-AI文件搜索系统
World File Search Systemcovariates


正则化函数回归模型可实现转录组范围内癌症药物反应剂量依赖性关联研究
图 1. 用于识别基因与药物之间剂量依赖性关联的两阶段算法。来自药物筛选研究(例如 GDSC)的基因表达和药物反应数据用于拟合我们的剂量变化系数模型,以估计协变量与药物反应之间的剂量变化效应。应用两阶段变量筛选和选择算法对基因-药物关联进行排序。然后可以使用所选基因来预测目标药物的剂量依赖性反应。

Thomas Opitz引用此版本
作者巧妙地开发了一个非平稳生成统计模型,以在气候变化下为空间温度极端变化,从而允许对空间风险度量的蒙特卡洛估计。基于对空间风险功能的阈值超出阈值的基础,该模型将来自不规则间隔的气象站的数据与定期空间网格上的物理气候模型的模拟结合在一起。他们的工作解决了对极端天气的频率,幅度和程度的全面统计评估的普遍需求。此任务是复杂的,因为温度是全球变暖的关键变量,在三维时空和时间上表现出强烈的异质趋势。物理模型的数值模拟提供了大量的“大”数据,但具有强大的局限性:模拟是确定性的,不是概率的,并且是在相对粗糙的空间网格上进行的,即,不是在天气站级别基于点;关于真实气候的模拟很大的偏见是可能的。计算成本很高,并防止模拟大量的全时代编年史和极端事件目录。相反,所提出的方法转移了有关从物理模拟到统计模型的稀疏观察到的空间温度生物性的信息,以获得基于点的随机天气发生器(SWG),而没有受到这种限制。它展示了SWG是增强物理模拟提供的数据的关键工具。,2024)。作者通过为批量模型进行多个分位回归来解决问题。,2023)。可以以低的计算成本来校准各种目的:仿真物理模型,从网格的大规模输入数据到基于点的分布的缩小,以及对罕见事件的大型样本的随机模拟。该纸张利用极值理论(EVT)的灵活最新方法用于基于年度位置的最大值的依赖峰值阈值,而不是传统方法,因此,来自数据的信息得到了更好的保存和解释(Horser等人的解释)(Horser等人。不过,这是有代价的:总空间风险的阈值超出了所有位置的总阈值超出阈值的阈值,因此必须适合将协变量的模型适合边缘分布的整体和尾部。另一种选择位于亚震荡模型中,也称为扩展的广义帕累托分布,它们可以灵活地捕获全部数据范围,同时在两个尾巴中都与渐近模型保持一致性(Papastathopoulos和Tawn,2013; Naveau等,2013; Naveau等人。,2016年; Yadav等。这有助于避免由于在明确的固定阈值下方和更高上方的拆分建模而增加的不确定性和建模开销。所提出的模型使用大规模的物理协变量(例如,温度均值)将大规模信号传播到局部(基于点)温度。规定可以确定协变量对温度响应的因果影响,这些模型将允许模拟未来的极端温度,并从气候变化的场景和物理模拟中获得未来的协变量。时间序列极端的因果推断工具(Bodik等人,2024)可以承诺确认大规模变量的因果影响。

在英国参加三个区域糖尿病眼镜筛查计划的一群种族多元化孕妇的糖尿病性视网膜病变的风险
背景/目标:目前,即使在怀孕早期未发现视网膜病变,所有糖尿病孕妇都至少两次参加筛查。我们假设对于怀孕早期没有糖尿病性视网膜病的女性,可以安全地降低视网膜筛查的频率。受试者/方法:在这项回顾性队列研究中,提取了2011年7月至2019年10月在2011年7月至2019年10月之间参加三个英国糖尿病眼镜筛查(DES)计划之一的4718名孕妇的数据。记录了13周妊娠(怀孕早期)和妊娠28周(妊娠晚期)的女性英国的成绩。描述性统计数据用于报告基线数据。有序的逻辑回归用于控制协变量,例如年龄,种族,糖尿病持续时间和糖尿病类型。结果:在早期和晚期记录的年龄段的女性中,总共3085(65.39%)妇女在怀孕早期没有视网膜病变,其中2306名妇女(74.7%)在28周内没有发育任何视网膜病。在怀孕初期,患有视网膜病变的女性人数为14(0.45%),没有人需要治疗。怀孕早期的糖尿病性视网膜病仍然是妊娠晚期的DES等级的显着预测指标,当时年龄,种族和糖尿病类型的协变量被控制(p <0.001)。结论:总而言之,这项研究表明,通过限制怀孕早期没有视网膜变化的妇女的糖尿病眼睛筛查预约糖尿病筛查预约的数量,可以安全地减少治疗怀孕母亲的糖尿病的负担。在怀孕早期对视网膜病变的妇女进行筛查应符合当前的英国指导。

识别符合 HLA-A*02 条件的患者中适合 TCR T 细胞疗法的 MAGE-A4 阳性肿瘤
T 细胞受体 (TCR) T 细胞疗法以人类白细胞抗原 (HLA) 限制的方式靶向肿瘤抗原。生物标志物定义的疗法需要验证适合确定患者资格的检测方法。对于评估针对黑色素瘤相关抗原 A4 (MAGE-A4) 的 TCR T 细胞疗法的临床试验,研究 NCT02636855 和 NCT04044768 中的筛选根据以下标准评估患者资格:(1) 高分辨率 HLA 分型和 (2) 通过免疫组织化学检测对符合 HLA 资格的患者进行肿瘤 MAGE-A4 检测。本文报告了 HLA/MAGE-A4 检测验证、生物标志物数据及其与协变量(人口统计学、癌症类型、组织病理学、组织位置)的关系。在来自北美和欧洲 43 个地点的患者中,HLA-A*02 的合格率为 44.8% (2,959/6,606)。虽然 HLA-A*02:01 是最常见的 HLA-A*02 等位基因,但其他基因(A*02:02、A*02:03、A*02:06)在西班牙裔、黑人和亚裔人群中显著增加了 HLA 的合格率。总体而言,基于临床试验入组人数的 MAGE-A4 患病率为 26% (447/1,750),涵盖 10 种实体肿瘤类型,滑膜肉瘤患病率最高 (70%),胃癌患病率最低 (9%)。除卵巢癌患者年龄和非小细胞肺癌组织学外,协变量通常与 MAGE-A4 表达无关。本报告展示了TCR T 细胞疗法生物标志物筛选的合格率,并为未来 MAGE-A4 靶向疗法的临床开发提供了流行病学数据。

临床,超声心动图和纵向特征与心力衰竭相关的射血分数
结果:该研究包括1307例HFREF患者中位随访16.3个月(IQR 8.0-30.6)。中位年龄为65岁;男性为68%,而57%是白人。在随访中,有39%(n = 506)开发了HFIMPEF,而61%(n = 801)具有持久的HFREF。多元COX回归模型确定性别,种族合并症,超声心动图和亚位术肽是HFIMPEF的重要协变量(p <0.05)。与持续的HFREF组相比,HFIMPEF组的生存率更好(p <0.001)。超声心动图和实验室轨迹之间的轨迹不同。
●我们的结果表明IPS是可推广的多...
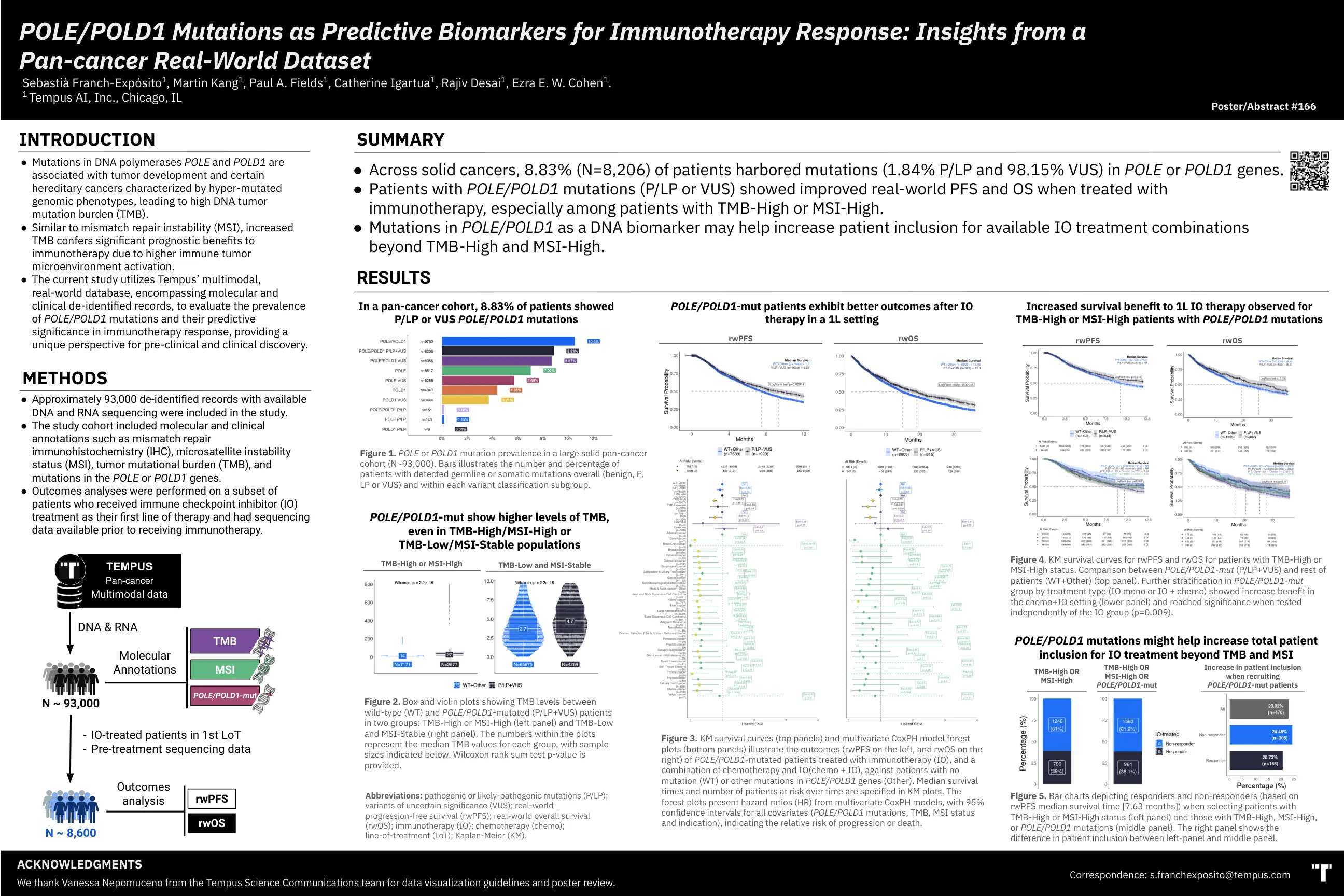
图3。km存活曲线(顶部面板)和多元Coxph森林图(底部面板)说明了POL/POLD 1的左侧的RWPF(左侧RWPF,右侧RWOS)的结果(RWOS),用免疫疗法(IO)治疗的患者(IO)以及与化学疗法和IO + IO + IO + IO + IO + IO + IO(IO)组合的结局(左侧),并与IO + IO + IO(IO)组合进行了突变(基因(其他)。在KM图中指定了随着时间的流逝的中位生存时间和处于危险中的患者人数。森林图具有多元COXPH模型的危险比(HR),所有协变量(POL/POLD1突变,TMB,MSI状态和指示)的置信间隔为95%,表明相对的进展或死亡风险。

在大流行期间加速治疗学的发展
摘要AZD7442是严重的急性呼吸综合征Coronavi rus 2(SARS-COV-2)中和抗体中和抗体,Tixagevimab和Cilgavimab,用于暴露前预防(预科)和治疗Coronavirus疾病2019(Covid-19)。使用来自八项临床试验的数据,我们描述了AZD7442的种群药代动力学(POPPK)模型,并显示了“临时”数据的建模如何加速了COVID-19-COVID-19-19大流行期间的决策。最终模型是具有一阶吸收和消除的两室分布模型,包括标准的异量指数,用于体重对清除和体积的影响。包括以下其他协变量如下:性别,年龄> 65岁,体重指数≥30kg/m 2,以及吸收率的糖尿病;清除糖尿病;中央音量的黑色种族;和肌内(IM)注射部位的生物利用度。模拟表明,IM注射部位和体重对AZD7442暴露的影响> 20%,但没有协变量被认为具有需要剂量调整的临床相关影响。AZD7442,Cilgavimab和Tixagevimab的药代动力学是可比的,遵循的线性动力学具有长期半衰期(AZD7442的中位数为78.6天),可长期保护易受敏感的SARS-COV-2变体。基于80%病毒抑制的目标浓度,基于“临时数据”的POPPK模拟的比较,并假设将1.81%的鼻腔分配分配为鼻衬液,这支持了决定将预备剂量从300 mg增加到600 mg的决定,以延长对Omicron变体的保护。在这些情况下,POPPK建模实现了加速临床决策。血清AZD7442在重40-95公斤的青少年中的浓度预计与成年人观察到的血清浓度仅略有不同,在获得临床数据之前,支持在青少年使用的授权。

森林生态与管理-NSF -PAR
生物多样性在全球范围内正在下降,如果要逆转当前趋势,预测物种多样性至关重要。树种丰富度(TSR)长期以来一直是生物多样性的关键衡量标准,但在当前模型中存在很大的确定性,尤其是考虑到经典的统计假设和机器学习成果的生态解释性差。在这里,我们测试了几种可解释的机器学习方法,以预测TSR并解释美国大陆的驾驶环境因素。我们开发了两个人工神经网络(ANN)和一个随机森林(RF)模型,以使用森林库存和分析数据和20个环境协变量来预测TSR,并将它们与经典的广义线性模型(GLM)进行比较。模型。采用了一种可解释的机器学习方法,Shapley添加性解释(SHAP),以解释驱动TSR的主要环境因素。与基线GLM相比(R 2 = 0.7; MAE = 4.7),ANN和RF模型的R 2大于0.9,MAE <3.1。此外,与GLM相比,ANN和RF模型产生的空间群集TSR残差较少。塑形分析表明,TSR最好通过干旱指数,森林面积,高度,最干燥季度的平均降水量和平均年温度预测。塑造进一步揭示了环境协变量与TSR和GLM未揭示的复杂相互作用的非线性关系。该研究强调了森林地区保护工作的必要性,并减少了低森林但干旱地区的树种与降水有关的生理压力。此处使用的机器学习方法可用于研究其他生物的生物多样性或在未来气候场景下对TSR的预测。

基于学习的主要心律失常事件的深度预测:概念研究证明
预测扩张的心肌病中重大心律失常事件(MAE)代表了一个未满足的临床目标。计算模型和人工智能(AI)是新的技术工具,可以在我们预测MAE的能力方面具有重大提高。在这项概念验证研究中,我们提出了一个基于深度学习(DL)的模型,我们称其为扩张心肌病(DARP-D)中的深度心律失常(DARP-D),该模型使用多种心脏磁共振数据(CINE和HYPERVIDEOS和HYPERVIDEOS和HYPERIMIMIAS和LGE图像和临床上的MA)(包括一个促进的MA),促进了促进的Maiatiations和临时性的MARIADES和临时性的促进,该模型(DARP-D)构建了。随着时间的流逝,心脏骤停,由于心室原纤维造成的,持续30 s的心室心动过速,或在<30 s的<30 s(适当的可植入的心脏除颤器干预)中导致血流动力学塌陷。该模型在154例扩张心肌病患者的样本中有70%的培训和验证,并在其余30%中进行了测试。DARP-D在Harrell的C一致性指数中达到95%CI,在测试集中达到0.12–0.68。我们证明了我们的DL方法是可行的,并且代表了扩张心肌病的心律失常预测领域的新颖性,能够分析心脏运动,组织特征和基线协变量,以预测一个个体的患者患者的大型心律失常事件的风险曲线。但是,患者,MAE和训练时期数量少,使该模型成为有希望的原型,但尚未准备好临床使用。需要进一步的研究来改进,稳定和验证DARP-D的性能,以将其从AI实验转换为每日使用的工具。