XiaoMi-AI文件搜索系统
World File Search Systemcovariates

神经表征的广义形状度量
理解生物和人工网络的运作仍然是一项艰巨而重要的挑战。为了确定一般原则,研究人员越来越有兴趣调查大量经过类似任务训练或生物学上适应类似任务的网络。现在需要一套标准化的分析工具来确定网络级协变量(例如架构、解剖大脑区域和模型生物)如何影响神经表征(隐藏层激活)。在这里,我们通过定义量化表征差异的广泛度量空间系列为这些分析提供了严格的基础。使用此框架,我们修改了基于典型相关分析和中心核对齐的现有表征相似性度量以满足三角不等式,制定了一个尊重卷积层中归纳偏差的新度量,并确定了近似欧几里得嵌入,使网络表征能够纳入几乎任何现成的机器学习方法中。我们在生物学(艾伦研究所脑观测站)和深度学习(NAS-Bench-101)的大规模数据集上展示了这些方法。在此过程中,我们确定了可根据解剖特征和模型性能进行解释的神经表征之间的关系。

年度教育与淀粉样蛋白 -
方法的淀粉样蛋白-PET信息([18 f] flutemetamol或[18 f] florbetaben)的SCD+,轻度认知障碍(MCI)和AD从AMYPAD-DPMS队列中获取,这是一项多中心随机对照研究。组分类基于SCD-I和NIA-AA工作组的建议。淀粉样蛋白宠物图像是在初次筛选后的8个月内获取的,并用不型进行处理。淀粉样蛋白负载基于全局丝氨酸(CL)值。教育水平由多年来的正规教育和随后的高等教育索引。使用线性回归分析,在整个队列中测试了教育对CL值的主要影响,然后评估通过诊断群体的教育互动(协变量:年龄,性别,性别和招募记忆诊所)。为了说明非AD病理学和合并症的影响,我们比较了白质高强度(WMH)严重程度(WMH)严重程度,心血管事件,抑郁症,抑郁症,焦虑症以及使用Fisher精确测试的每个诊断类别中受过较低教育和受过良好受教育程度的群体之间的较低教育和受过良好受教育程度的组之间的焦虑病史。教育

通过可解释的高级心电图估计的心脏年龄差距与心血管危险因素和生存有关
A-ECG和DNN-AI心脏年龄均适用于接受临床心血管磁性复合成像的患者。使用逻辑回归评估了A-ECG或DNN-AI心脏年龄差距与心血管危险因素之间的关联。使用针对临床协变量/合并症调整的COX回归评估了心脏年龄差距与死亡或心力衰竭(HF)住院治疗之间的关联。在患者中[n = 731,103(14.1%)死亡,52(7.1%)HF住院治疗,中值(四分位间范围)随访5.7(4.7-6.7)年],A-ECG心脏年龄差距与风险因素和外观有关[未经调整的危险率(95%)(95%的置信度)(95%置信区)(95%置信区)(5年) (1.13–1.34)和调整后的HR 1.11(1.01–1.22)]。dnn-ai心脏年龄间隙与调整后的危险因素和结果相关[HR(5年增量):1.11(1.01-1.21)],但在未经调整的分析[HR 1.00(0.93-1.08)]中无关,使其不易适用于临床实践。

损失、悲伤和耻辱的影响 - NTU > IRep
本研究使用验证性因子分析 (CFA) 和一系列每次一个协变量的方法,检验了匈牙利版药物依从性评定量表 (MARS) 的因子结构,并分析了其与社会人口统计学、自知力、内化耻辱以及因被诊断为精神疾病而产生的失落和悲伤体验之间的关联。精神病患者 (N=200) 完成了自我报告问卷。尽管其中一项从其原始因子移到了另一个因子,但 CFA 支持原来的三因子结构。自知力较低、内化耻辱、失落和悲伤较高是治疗依从性较低的重要预测因素。研究发现,依从性较低与生活质量较低显著相关。不同诊断组之间的依从性没有差异,这强调需要在更广泛的精神诊断范围内检验不依从性。这项研究还强调了患者的主观体验在促进更好的依从性方面的重要性,并提出了解决耻辱感以及较少研究的体验(如患者的失落感和悲伤感)的必要性。将这些体验整合到干预计划中可能对改善治疗依从性和患者的生活质量具有重要意义。

健康的社会决定因素和 2 型糖尿病
项目方法与结果 使用数据分析平台 KNIME 将 2010 年至 2019 年期间超过 15 亿份肯塔基州医疗补助索赔加载到纵向数据仓库中。关注的主要结果包括患 2 型糖尿病本身的风险,以及该疾病的五种常见并发症:肾病(终末期肾病 (ESRD));糖尿病心脏病(心肌梗死 (MI));外周动脉疾病 (PAD);糖尿病神经病变;和糖尿病视网膜病变。对于每种情况,索赔数据和一组医疗/ SDOH 协变量用于进行回归分析。然后使用这些模型来确定哪些因素对每种疾病的发病风险较高或较低。研究作者使用来自区域贫困指数 (ADI) 的地理链接数据来探索健康的社会决定因素与糖尿病并发症之间的关联。 2 型糖尿病 (T2DM) 就 T2DM 本身而言,研究发现导致该疾病发展的因素包括贫困、教育程度低和肥胖,这与文献一致。图 1 显示了 T2DM 的县分布。图 1 . 肯塔基州糖尿病的地理分布

糖尿病患者的社会排斥:德国老龄化调查(DEAS)的横断面和纵向结果
由于社会排斥可以与健康状况更糟和整体生活质量相关,因此我们描述了糖尿病患者的社会排斥,并评估糖尿病是否可以被视为社会排斥的危险因素。我们使用线性回归,群体比较和广义估计方程来分析了对年龄> 40岁的社区居民的调查,分析了两个波浪(2014、2017,n = 6604),以探索糖尿病,社会排斥,社会经济,身体,身体和心理社会质量变量之间的关联。在整个队列中,调整协变量后,糖尿病与社会排斥相关(p = 0.001)。在糖尿病患者中,社会排斥进一步与自尊(p <0.001),孤独感(p = <0.001),收入(p = 0.017),抑郁症(p = 0.001),身体疾病(p = 0.04)和网络大小(p = 0.043)有关。纵向数据表明,在诊断糖尿病之前已经存在更高的社会排斥,并且通过自尊,孤独,抑郁和收入预测未来的社会排斥,但糖尿病不可能(p = .221)。我们得出结论,糖尿病不是社会排斥的驱动力。相反,由于健康相关和社会心理变量,两者似乎都同时发生。

回归系数测试的剩余置换测试
当协变量p的尺寸可以达到样本量n的恒定分数时,我们考虑测试单个系数是否等于线性模型中的问题。在这个制度中,一个重要的主题是提出具有有限型构图的有效尺寸控制的测试,而无需噪声遵循强烈的分布假设。在本文中,我们提出了一种称为剩余置换测试(RPT)的新方法,该方法是通过将回归残差投射到原始设计矩阵和置换设计矩阵的柱子空间的空间正交中来构建的。rpt可以在固定设计下以可交换的噪声在固定设计下实现有限的人口尺寸有效性,每当P 此外,对于重型尾部噪声, rpt均具有渐近强大的功能,该噪声(1 + t)的订单矩至少在t∈[0,1]中至少属于n -t/(1 + t)阶时。 我们进一步证明了这种信号大小的要求在最小值意义上本质上是最佳的速率。 数字研究结合了RPT在具有正常和重尾噪声分布的各种模拟设置中表现良好。rpt均具有渐近强大的功能,该噪声(1 + t)的订单矩至少在t∈[0,1]中至少属于n -t/(1 + t)阶时。我们进一步证明了这种信号大小的要求在最小值意义上本质上是最佳的速率。数字研究结合了RPT在具有正常和重尾噪声分布的各种模拟设置中表现良好。数字研究结合了RPT在具有正常和重尾噪声分布的各种模拟设置中表现良好。

营养 1 队列中母亲鱼类消费与儿童神经发育:塞舌尔儿童发展研究
摘要 母亲食用鱼类会使胎儿接触到有益的营养物质和潜在的有害神经毒素。本研究调查了母亲食用鱼类与儿童神经发育结果之间的关联。塞舌尔儿童发展研究营养队列 1(n 229)使用 4 天的食物日记评估了母亲的鱼类消费量。在 9 个月和 30 个月以及 5 岁和 9 岁时评估神经发育,测试电池评估了二十六个终点并涵盖了多个神经发育领域。分析使用了多元线性回归,并调整了已知会影响儿童神经发育的协变量。这个队列平均每周吃 8 顿鱼,怀孕期间总鱼摄入量为 106·8(SD 61·9)克/天。在主要分析中评估的二十六个终点中,有一个有益的关联。母亲食用较多鱼类的儿童在 5 岁时考夫曼简明智力测试(一种非语言智力测试)中的表现略好(β 0·003,95% CI(0,0·005))。将鱼类消费量分为三分位数的二次分析发现,在比较最高和最低消费组时没有发现显著关联。在这个群体中,鱼类消费量大大高于目前的全球建议量,母亲怀孕期间的鱼类消费量与儿童的神经发育结果没有有利或不利的关联。
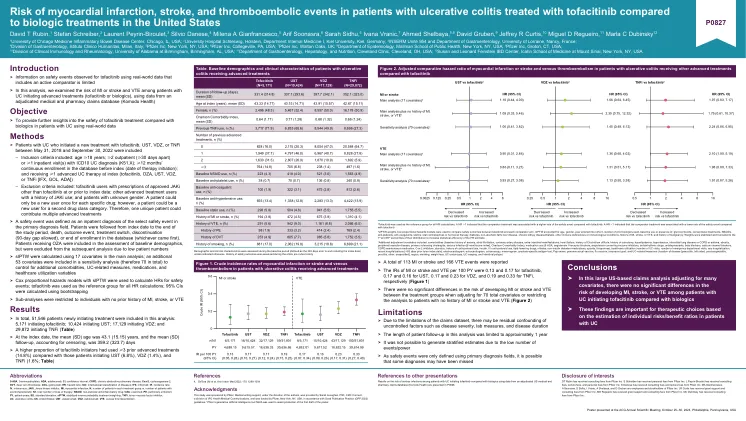
心肌梗塞、中风和血栓栓塞的风险......
c 其他调整协变量包括:合并症(基线时贫血史、心房颤动、冠状动脉疾病、肠外表现、心力衰竭、艰难梭菌病史、结肠切除术史、高脂血症、高血压、间质性肺病或 COPD 或哮喘、肥胖、外周血管疾病、原发性硬化性胆管炎、严重感染 [指数前 6 个月]、Charlson 合并症指数);药物使用情况(5-ASA、血管紧张素 II 受体阻滞剂、血管紧张素转换酶抑制剂、抗心律失常药物、抗抑郁药、β 受体阻滞剂、钙通道阻滞剂、COPD 维持药物、Cox-2 抑制剂、利尿剂、皮质类固醇使用史、胰岛素、静脉注射皮质类固醇使用、降脂药、硝酸盐、非胰岛素糖尿病药物、阿片类药物、硫嘌呤);医疗保健利用情况(UC 就诊次数、急诊就诊次数、住院情况、近期住院情况 [ ⩽ 指数日期前 60 天/当天 60 天]、心电图、超声心动图、结肠镜检查、乳房 X 线检查、前列腺特异性抗原检测、巴氏涂片、肺炎球菌疫苗、流感疫苗、保险类型);以及 UC 相关指标(疾病部位 [全结肠炎、左侧、直肠乙状结肠炎、直肠炎、其他、未指定]、区域、吸烟、体重减轻、UC 内窥镜检查、UC 成像和肠息肉)

针对性的最大似然估计,以估算先前结核病治疗在苏丹耐药性结核病中的因果关系
多药耐药性结核病(MDR-TB)被定义为异念珠菌和利福平的感染。在全球范围内,有132222个报告了2020年的MDR-TB病例。研究表明,先前的结核病治疗和治疗中断被认为是MDR-TB的主要原因[1,2]。流行病学家将病例对照研究定义为偏见的采样设计。病例对照研究的设计着重于参数逻辑回归,以计算一组协变量的调整后的奇数比(或)。但是,为了建立因果估计人群,或应估算。流行病学家将案例控制定义为与目标人群相比患有疾病的人比例的偏见。病例对照研究的设计着重于参数逻辑回归,以计算一组协变量上的或条件。要构建因果估计,我们必须估计边缘人口或[3]。目标最大似然估计(TMLE)是一种双重鲁棒方法,使用机器学习算法来最大程度地减少偏见的风险[4]。逆概率处理权重(IPTW)是一种因果方法,用于通过创建检查治疗对暴露的影响的模拟组来调整时变的混杂因素。IPTW方法基于侵害的概率,因为混杂因素被称为倾向评分(SP)[5]。 iptw在病例对照研究中有许多缺点,因此估计器无法在有限样本中对无症状效率和效率问题提出任何主张。IPTW方法基于侵害的概率,因为混杂因素被称为倾向评分(SP)[5]。iptw在病例对照研究中有许多缺点,因此估计器无法在有限样本中对无症状效率和效率问题提出任何主张。此外,IPTW在某些阶层中通过一组协变量定义的治疗或暴露组非常罕见时发生的所谓阳性违规行为不利[6]。因此,病例对照加权TMLE(CCW-TMLE)方法提供了双重鲁棒方法来估计无偏见的参数估计。如果给定暴露和协变量的结果模型的任何预期参数或给定协变量的暴露模型是正确的[7],则此方法是一致的。ccw-tmle需要了解结果的患病率概率,以减少偏见的设计[8]。此外,CCW-TMLE估计了各种参数,例如风险比和风险差异,这些参数在病例控制研究的传统分析中不可用。此外,TMLE可以估计边际因果效应,正确的规范和倾向评分。TMLE估计所有参数,假设每个人的暴露状态不会影响任何其他人的潜在结果。主要因果假设是没有未衡量的混杂因素。因此,已经测量了暴露和外来的常见原因[9]。在分析过程中有两种广泛的方法可以控制混杂。第一种方法是使用标准回归模型,第二种方法是遵循因果方法。标准回归模型无法在存在可能的混杂或相互作用和协变量之间的混杂或相互作用的情况下估算暴露的平均因果效应。原因是,此方法假设暴露者和混杂因素之间没有相互作用来估计池效应。更重要的是,标准回归模型无法调整时间变化