XiaoMi-AI文件搜索系统
World File Search Systemcovering

报道CCB执行委员会的报告24
审查董事会在缓解气候变化和适应性摘要方面的立场:介绍完成审查的行动计划。作者:安迪·帕森斯(Andy Parsons)(首席执行官)和马克·康纳利(Mark Connelly)(土地管理官)建议:董事会批准采取行动计划,以审查其与气候变化有关的战略和立场声明。背景在2019年10月,两位董事会成员写信给主席,副主席兼首席执行官,要求:根据气候紧急情况,董事会决心立即对我们的土地使用指南进行立即审查,以及我们有关可再生能源的政策,以使其更容易获得;并在2020年夏天向董事会报告。目前的立场并瞄准了政府间气候变化(IPCC)报告(IPCC)报告和英国气候预测(UKCP)的数字2007年引起了警报和紧张的紧迫性,促使董事会采取行动。这导致了2012年Cotswolds AONB采用气候变化策略,气候变化是当前和先前的AONB管理计划中的核心主题,可再生能源位置声明的修订以及对环境策略的彻底修订,并彻底修订了我们的政策和指导,以证明我们的政策和指导,同时提供了Anonb和Anonb和anonb和anonb和amonb and the annob and and and and的目的。在以下文件中找到了董事会的当前立场,并且在气候变化方面的目标是:

还原目标涵盖范围1和2排放的目标到2050
增强用于大学不同活动的总能源混合物中可再生能源的配额。目前使用了来自太阳能PV的1兆瓦可再生能源。将来所有的建筑物都将集成。此外,到2040年,包括基于生物质的发电在内的多生成发电。强制性设备有效地贡献了上述任务。

双城市地板覆盖行业养老金计划
PPA要求以濒危或严重濒危地位的退休金计划,以采用旨在恢复计划财务状况的资金改进计划。该计划的受托人于2018年6月13日通过了一项资金改进计划(FIP)。FIP的目标是将计划的资助百分比增加到截至2017年8月1日的资金百分比之间的33%,到资金改善期结束时100%(即截至2029年7月31日,86.5%),以避免在资金改善期结束之前削弱资金。该计划的精算师估计该计划的资金截至2020年8月1日为81.4%。
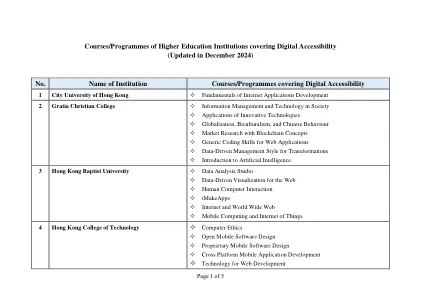
涵盖数字可访问性的高等教育机构的课程/计划
应用机器人技术以及用于特殊教育的应用程序为人工智能的实用编程移动应用程序设计和开发用于数据分析的Web数据库应用程序神经网络和深度学习编码和计算思维用来的技术学习环境设计了创新学习环境的设计技术具有Python of Things of Python fressing Internt of Things Internet/Div

涵盖所有基础:DNA测序效率中的下一局
I. i Dratsuction的数字数据快速增长,预计到2025年将达到180个Zettabytes,这会导致数据存储危机,需求超过供应[1]。现有的存储技术面临满足大数据需求的挑战。为了响应,DNA由于其密度和杜比(Durabil)而成为有前途的培养基。DNA存储过程涉及综合,创建人工DNA链,编码用户信息,并限制了导致短链和多个嘈杂副本[2],存储容器和测序的存储,一个关键组件[3],[4],[4],[5],[5],[6],将DNA转化为数字序列。与替代方案相比,当前的DNA测序仪可能存在DNA的潜力,但当前的DNA测序仪面临诸如缓慢吞吐量和高成本等挑战[7],[8],[9]。覆盖深度,测序读取与设计链的比率,影响系统潜伏期和成本,突出了优化的需求[10],[4]。我们通过将其推广到更实用的情况来扩展了解决覆盖深度问题[11]的最新研究。具体来说,我们考虑一个存储M文件的容器,每个文件由K信息链组成。使用某些编码方案将这些链编码为MN链,目的是从总m中恢复文件。我们的重点是研究所需的覆盖深度,考虑到诸如DNA存储通道和错误校正代码之类的因素。此外,我们旨在探索错误纠正代码与给定DNA存储系统的最佳配对,以最大程度地减少覆盖深度。此调查是在随机访问设置的框架内进行的,用户试图仅检索存储信息的一小部分。在这种情况下,我们同时进行了理论和实验分析,以检查完全恢复指定文件所需的样本数量的期望和概率分布。DNA覆盖深度问题类似于众所周知的问题,例如优惠券收藏家,Dixie Cup和urn问题,目的是收集所有类型的优惠券或物体[12],[13],[14],[15]。在我们的上下文中,“优惠券”代表综合链的副本,目的是阅读每个信息链的至少一个副本。例如,如果n张优惠券是随机均匀地绘制的,众所周知,所需的预期抽奖
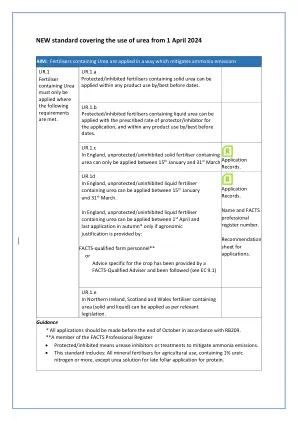
新标准涵盖了2024年4月1日使用尿素的新标准
*所有申请应根据RB209在10月底之前提出。**事实专业登记册的成员•受保护/抑制是指减轻氨排放的尿素抑制剂或治疗方法。•该标准包括:所有用于农业用途的矿物质肥料,含1%尿素氮或更多,除了用于延迟叶面蛋白质的尿素溶液。

专利涵盖授予Syncardia的创新性人工心脏设计
医疗建议免责信息,包括但不限于本网站上包含的文本,图形,图像和其他材料的信息仅用于信息目的。本网站上没有材料旨在替代专业的医疗建议,诊断或治疗。始终在医生中寻求您的医生或合格的医疗保健提供者的建议。由于您在本网站上阅读的信息,切勿忽略专业医疗建议或延迟寻求它。©Synardia Systems,LLC |版权所有。

SynCardia 获得第二项专利,涵盖完全植入式人工心脏
“我们致力于创造最先进的技术,造福全球心力衰竭患者。SynCardia 的使命是开发 Emperor,它有望成为世界上第一台完全植入式 SynCardia 全人工心脏 (STAH),可作为心脏移植的替代方案”,首席执行官 Patrick NJ Schnegelsberg 评论道。“这是我们的第二项涉及完全植入式心脏技术的专利。鉴于 SynCardia 在人工心脏领域的领导地位以及我们在 2,000 多名患者身上植入目前美国食品药品监督管理局 (FDA) 批准的 STAH 版本的丰富临床经验,我认为我们有机会快速开发和商业化完全植入式 STAH。”


密歇根州综合医疗保健计划涵盖营养服务:引入替代服务
• 可以通过健康饮食改善的疾病,如糖尿病、心脏病、中风、肺病、高血压、人类免疫缺陷病毒 (HIV)、癌症、肥胖症、口腔健康疾病、镰状细胞病、肾脏疾病、物质使用障碍或精神健康障碍。