XiaoMi-AI文件搜索系统
World File Search Systemembeddings

LLMS中的图像理解
项目描述。大型语言模型(LLMS)的令人印象深刻的成功引发了管理多种方式以外的多种方式的需求。结果,已经出现了大型多模型(LMM),例如GPT-4V,GEMINI,DEEPSEEK-VL和QWEN2-VL。这些模型可以理解涉及视觉和语言的说明并采取行动,即,它们使用户能够上传图像并与LLM讨论。原则上,多模式变压器(例如剪辑和碎片)旨在处理文本和图像输入。这些模型在关节空间中处理视觉和文本数据。这使他们可以理解文本并将其连接到视觉表示。一般框架如下:i)图像特征首先是通过视觉变压器(例如VIT)提取的,该vit将视觉数据转换为嵌入,ii)文本输入由语言模型处理,该模型将文本模型转换为自己的嵌入,然后iiii iii)通过共享的变压器结构或通过交叉说明机构将两个嵌入式处理在一起。但是,有一些架构细节将这些模型彼此区分。

哈里斯公共政策学院Andre Uhl,芝加哥大学博士UHL@uchicago.edu 2025年春季:Arti的道德与治理Anjali Adukia-哈里斯公共政策学院
- 出版社:《华盛顿邮报》,《教育周》,《粉笔》,WGN电视,WGN(文章),WBEZ芝加哥,WBEZ RESET,POLITICO PLAYBOOK,THE PIE PODCAST,BET,BET,Loop Radio,芝加哥俱乐部,芝加哥Sun Times,WTTW,WTTW,Restorative Works,Restorative Works!Podcast , Hechinger Report , USA Today , Gothamist “ Residential Segregation and Unequal Access to Local Public Services: Evidence from 1.5m Neighborhoods in India ” (with S. Asher ⓡ K. Jha ⓡ P. Novosad ⓡ B. Tan) (February 2024, Revision invited from the American Economic Review ) (* ⓡ signifies randomized author order) “Category Embeddings Measure Intersectional Portrayals of Race and性别”(与A. Eble&E。Harrison一起)(邀请自然界的修订)“教会和国家课程的分离?审查公立和宗教私立学校教科书”(与E. Harrison一起)(2024年12月,工作文件)发表了研究社会科学期刊:“我们对种族和性别的教学:在儿童书籍的图像和文本中的代表性”(与A. Eble,E。Harrison,H.B.Runesha,T。Szasz)(2023年11月,《经济学季刊》)

llm用例:神经主题模型
Bianchis,F。,Land,S。,&Hovy,D。(2021)。预训练是在热门主题中:上下文嵌入的嵌入式培训。ACL。https://aclanthology.org/2021.clato-short.96/Banchie,F。,Terragate,S.,Hovy,D.,Navest,D.,D.,D.,D.,D.,D。(2021)。上下文化主题模型零击学习。EACL。https://www.acltweb.orgweb/anthology/2021.eacla-main.143/

用于首字母缩略词识别和消歧的 Primer AI 系统
歧义缩略词的盛行使得科学文献对于人类和机器来说都更难理解,因此需要能够自动识别文本中的缩略词并消除其含义歧义的模型。我们引入了用于首字母缩略词识别和消歧的新方法:我们的首字母缩略词识别模型将学习到的标记嵌入投射到标签预测上,我们的首字母缩略词消歧模型找到具有类似句子嵌入的训练示例作为测试示例。与之前提出的方法相比,我们的两个系统都实现了显着的性能提升,并且在 SDU@AAAI-21 共享任务排行榜上表现出色。我们的模型部分在针对这些任务的新远程监督数据集上进行了训练,我们将其称为 AuxAI 和 AuxAD。我们还发现了 SciAD 数据集中的重复冲突问题,并形成了 SciAD 的去重版本,我们称之为 SciAD-dedupe。我们公开发布了这三个数据集,并希望它们能够帮助社区在科学文献理解方面取得进一步进展。

Primer AI 的首字母缩略词识别和消歧系统
歧义缩略词的盛行使得科学文献对于人类和机器来说都更难理解,因此需要能够自动识别文本中的缩略词并消除其含义歧义的模型。我们引入了用于首字母缩略词识别和消歧的新方法:我们的首字母缩略词识别模型将学习到的标记嵌入投射到标签预测上,我们的首字母缩略词消歧模型找到具有类似句子嵌入的训练示例作为测试示例。与之前提出的方法相比,我们的两个系统都实现了显着的性能提升,并且在 SDU@AAAI-21 共享任务排行榜上表现出色。我们的模型部分在针对这些任务的新远程监督数据集上进行了训练,我们将其称为 AuxAI 和 AuxAD。我们还发现了 SciAD 数据集中的重复冲突问题,并形成了 SciAD 的去重版本,我们称之为 SciAD-dedupe。我们公开发布了这三个数据集,并希望它们能够帮助社区在科学文献理解方面取得进一步进展。

UNICORN:通过可解释的多任务学习框架实现通用细胞表达预测
序列到功能分析是人类遗传学中的一项具有挑战性的任务,特别是在从生物序列(例如个体化基因表达)预测细胞类型特异性多组学表型时。在这里,我们提出了一种新方法 UNICORN,其预测性能比现有方法有所提高。UNICORN 将来自生物序列的嵌入以及来自预先训练的基础模型的外部知识作为输入,并使用精心设计的损失函数优化预测器。我们证明 UNICORN 在细胞水平和细胞类型水平的基因表达预测和多组学表型预测方面均优于现有方法,并且它还可以生成预测的不确定性分数。此外,UNICORN 能够将个性化的基因表达谱与相应的基因组信息联系起来。最后,我们表明 UNICORN 能够表征不同疾病状态或扰动的复杂生物系统。总体而言,基础模型的嵌入可以促进理解生物序列在预测任务中的作用,并且结合多组学信息可以提高预测性能。

强化学习解码器容忍故障量子计算
张量网络方法已从基于基于基质产物状态的变异技术进行了发展,能够计算一维冷凝的晶格模型的特性到源自更精致状态的方法,例如旨在模拟二维模型物理学的预测纠缠对状态。在这项工作中,我们提倡范式,即对于二维费米子模型,矩阵 - 产品态仍然适用于比直接嵌入一维系统允许的明显更高的精度水平。为此,我们利用了费米子模式转换的方案,并克服了一维嵌入需要是局部的偏见。这种方法认真对待洞察力,即对矩阵态的多种形式和模式转换的单一多种流形,可以更准确地捕获自然相关结构。通过证明新兴模式中残留的低水平纠缠水平,我们表明矩阵态可以很好地描述基态。通过研究晶格尺寸的无旋转费用的相变高达10×10,该方法的功率被例证了。

SleepFM:在大脑活动,ECG和呼吸信号
睡眠是通过记录各种方式来评估一种复杂的生理过程。我们从14,000多个参与者中策划了一个大型的多模式睡眠记录的大型多摄影数据集。掌握了这个广泛的数据集,我们开发了SleepFM,这是第一个用于睡眠分析的多模式基础模型。我们表明,与标准的成对构造学习的表示相比,一种新颖的对比学习方法可以显着证明下游任务绩效。A logistic regression model trained on SleepFM 's learned embeddings out- performs an end-to-end trained convolutional neu- ral network (CNN) on sleep stage classification (macro AUROC 0.88 vs 0.72 and macro AUPRC 0.72 vs 0.48) and sleep disordered breathing de- tection (AUROC 0.85 vs 0.69 and AUPRC 0.77 vs 0.61)。值得注意的是,从90,000名候选人中获取其他响应的记录剪辑,学到的嵌入在检索其他方式的记录剪辑方面达到了48%的平均准确性。这项工作展示了整体多模式睡眠模型的价值,以完全捕获睡眠记录的丰富性。SleepFM是开源的,可在https://github.com/rthapa84/sleepfm-codebase上找到。

使用 D-Wave 量子退火器对质因数分解问题进行实验
本文以我们最近发表的一篇论文为基础,在这篇论文中,我们提出了一种通过量子退火进行素数分解 (PF) 的新方法,其中 8,219,999 = 32,749 × 251 是我们能够分解的最高素数乘积——据我们所知,这是有史以来通过量子设备分解的最大数字。然而,导致我们得到这些结果的一系列退火实验并没有遵循直线路径;相反,它们涉及一个复杂的反复试验过程,充满了失败或部分失败的尝试和回溯,最终只能促使我们找到成功的退火策略。在本文中,我们深入探讨了实验决策背后的原因,并介绍了在构思最终策略之前我们进行的一些尝试,这些策略使我们能够实现结果。这还涉及我们研究的一系列想法、技术和策略,尽管结果证明它们不如前者。我们最终采用的方法,可能会为更专业的 D-Wave 用户和从业者提供见解。具体来说,我们展示了以下见解:(i)不同的初始化技术会影响性能,其中通量偏差在针对局部结构化嵌入时是有效的;(ii)与依赖全局嵌入的问题相比,链强度在局部结构化嵌入中的影响较小;(iii)断链和激发的 CFA 之间存在权衡,这表明基于模块而不是单个量子位的增量退火偏移补救方法。因此,通过分享我们经验的细节,我们旨在提供对量子退火不断发展的前景的见解,并帮助人们访问和有效使用 D-Wave 量子退火器。
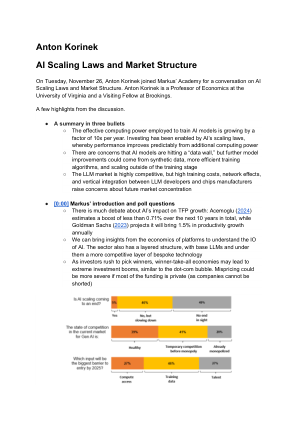
Anton Korinek 人工智能缩放定律和市场结构
正如 Eric Schmidt 所说,人工智能是否能够超越人类的理解?通过嵌入,我们已经处于黑匣子阶段。随着人工智能与经济的日益融合,它将变得无法拔掉电源,就像不可能在没有重大社会和经济动荡的情况下停止供电一样 时间戳:[9:47] 人工智能扩展定律 [27:48] 人工智能市场快照