XiaoMi-AI文件搜索系统
World File Search Systemepoch

太空系统司令部媒体发布
SSC 的弹性导弹预警和跟踪计划专注于快速将强大的高空持续红外传感技术应用于 MEO 中的全新卫星星座。Epoch 方法是每隔几年发射一次卫星,随着时间的推移逐步建立作战能力。这些卫星旨在探测和跟踪一系列威胁,从大型明亮的洲际弹道导弹发射到昏暗的机动高超音速导弹,并与更广泛的国家导弹防御架构无缝集成。该计划的结构是使用连续的 Epoch 来首先刺激竞争、创新和快速交付最关键的作战需求。

国防部制导、导航和控制标准参考...
历元 1991.25。位置是在历元 2000 和 2016 创建的。Hipparcos 在历元 1991.25 与 Gaia_PM 匹配,并在历元 2016 与 Gaia_noPM 独立匹配。两次交叉匹配均使用 4 弧秒半径。结果发现 Hipparcos 恒星与几颗 Gaia 恒星匹配,反之亦然。在这些情况下,只保留最接近的匹配,其他匹配被视为独立恒星。一些 Hipparcos 恒星与 Gaia_PM 和 Gaia_noPM 恒星都匹配。同样,通过比较各自时期的匹配距离,优先选择最接近的匹配。在未来版本的星表里,可能会考虑利用交叉匹配中的恒星星等信息。100 颗 Hipparcos 恒星无法与 Gaia 匹配。它们中的大多数对于 Gaia 来说太亮了(72 颗的 Hp < 5 星等)。剩余的 28 颗恒星(其中 5 颗 < Hp < 13.8)尚未得到彻底研究,但以下是它们在盖亚中缺失的一些可能性:

附录
对于所有实验,源解析器都是一个神经 PCFG [64],具有 20 个非终结符和 20 个前终结符。所有实验共享的其他模型设置包括:(1)Adam 优化器,学习率 = 0.0005、β1 = 0.75、β2 = 0.999,(2)梯度范数剪裁为 3,(3)L2 惩罚(即权重衰减)为 10-5,(4)Xavier Glorot 均匀初始化,以及(5)训练 15 个 epoch,并在验证集上提前停止(大多数模型在 15 个 epoch 之前就收敛得很好)。SCAN 和风格迁移数据集的批次大小为 4,机器翻译数据集的批次大小为 32。由于内存限制,在实践中我们使用批次大小 1,并通过梯度累积模拟更大的批次大小。我们观察到训练有些不稳定,一些数据集(例如 SCAN 和机器翻译)需要使用 4 到 6 个随机种子进行训练才能表现良好。一般来说,我们发现过度参数化语法和使用比必要更多的非终结符是可以的 [13]。

益生菌研究更新2024年7月
Srinivasjois R,Gebremedhin A,Silva D等。新生儿年龄组中补充益生菌和最初两年的住院风险:西澳大利亚州的数据联系研究。营养。2024 Jun 30; 16(13):2094这是一项回顾性研究,其中包括在2个不同时期的早产<32+6周,在第二个时期引入了单个菌株益生菌补充剂。包括Epoch 1和1 1422中的总共1238名婴儿。在2时期,任何原因的住院量较小,允许混杂因素(RR 0.92(0.87-0.98))。对呼吸道问题的住院影响也有类似的作用,但肠感染住院的差异没有显着差异。此外,在两个时期出生的婴儿<28周没有差异。



幂律缩放以协助解决人工智能中的关键挑战
幂律缩放是临界现象中的一个核心概念,在深度学习中很有用,其中手写数字示例的优化测试误差随着数据库大小的增加以幂律形式收敛到零。对于一个训练周期的快速决策,每个示例只向训练好的网络呈现一次,幂律指数随着隐藏层的数量而增加。对于最大的数据集,获得的测试误差估计接近大周期数的最新算法。幂律缩放有助于解决当前人工智能应用中的关键挑战,并有助于先验数据集大小估计以实现所需的测试精度。它为衡量训练复杂性和机器学习任务和算法的定量层次建立了基准。

本科论文招股说明书正在导航肺部手术...
检查累犯量表的有效性和预测准确性刑事司法研究报告。纽约州刑事司法服务部。https://www.criminaljustice.ny.gov/crimnet/ojsa/opca/compas_probation_report_2012.pd f lobacheva,A。和Kashtanova,E。(2022)。人造时代的社会歧视
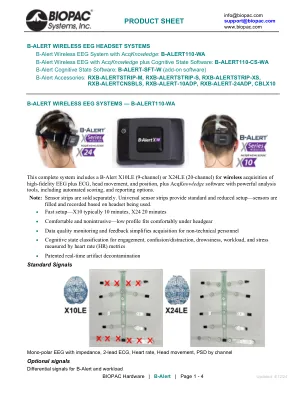
B-警报系统
B-Alert 无线 EEG 生物特征使用来自三个不同任务的 5 分钟基线数据标准化为个体受试者,睡眠开始类别根据基线 PSD 值预测。然后为每个时期的四个类别中的每一个生成拟合概率,四个类别的概率总和等于 1.0(例如,0.45 高参与度、0.30 低参与度、0.20 分心和 0.05 睡眠开始)。给定秒的认知状态代表概率最大的类别。B-Alert 认知状态指标是使用四类二次判别函数分析 (DFA) 中差异位点 FzPO 和 CzPO 的 1 Hz 功率谱密度 (PSD) 箱为每个一秒时期得出的,该分析适合个人独特的 EEG 模式。该表简要描述了每个基线任务和 B-Alert 分类。

输入形状对用于脑机接口的卷积神经网络的原始 EEG 运动想象信号分类性能的影响
摘要:许多研究人员对脑电信号进行解释、分析和分类,以用于脑机接口。尽管脑电信号采集方法有很多种,但最有趣的方法之一是运动想象信号。已经开发了许多不同的信号处理方法、机器学习和深度学习模型来对运动想象信号进行分类。其中,卷积神经网络模型通常比其他模型取得更好的效果。由于数据的大小和形状对于训练卷积神经网络模型和发现正确的关系非常重要,研究人员设计并试验了许多不同的输入形状结构。然而,在文献中还没有发现评估不同输入形状对模型性能和准确性影响的研究。在本研究中,研究了不同输入形状对脑电运动想象信号分类模型性能和准确性的影响,这在以前没有专门研究过。此外,没有使用信号预处理方法,因为在分类之前需要很长时间;而是开发了两个 CNN 模型,使用原始数据进行训练和分类。分类过程中使用了两个不同的数据集,BCI 竞赛 IV 2A 和 2B。对于不同的输入形状,2A 数据集获得了 53.03–89.29% 的分类准确率和 2–23 秒的 epoch 时间,2B 数据集获得了 64.84–84.94% 的分类准确率和 4–10 秒的 epoch 时间。这项研究表明,输入形状对分类性能有显著影响,当选择正确的输入形状并开发正确的 CNN 架构时,CNN 架构可以很好地完成特征提取和分类,而无需任何信号预处理。