XiaoMi-AI文件搜索系统
World File Search Systemf1

用于重建NGS的聚类模型之间的性能比较来自技术重复
为了提高单个DNA测序结果的性能,研究人员经常使用同一个人和各种统计聚类模型的重复来重建高性能呼叫仪。在这里,考虑了基因组Na12878的三个技术重复,并比较了五个模型类型(共识,潜在类,高斯混合物,kamila - 适应性的K-均值和随机森林),涉及四个性能指标:敏感性,精度,精度,准确性和F1评分。与不使用组合模型相比,i)共识模型提高了精度0.1%; ii)潜在类模型带来了1%的精度改善(97% - 98%),而不会损害灵敏度(= 98.9%); iii)高斯混合模型和随机森林提供了更高精确度(> 99%)但敏感性较低的呼叫; iv)卡米拉提高了精度(> 99%),并保持高灵敏度(98.8%);它显示出最好的总体表现。根据精确和F1得分指标,比较了组合多个呼叫的非监督聚类模型能够改善测序性能与先前使用的监督模型。在比较模型中,高斯混合模型和卡米拉提供了不可忽略的精度和F1得分的改进。因此,可能建议将这些模型用于呼叫集重建(来自生物或技术重复),以进行诊断或精确医学目的。

RGB视频和基于红外线的秋季检测的计算视觉模型分析
瀑布是一个严重的公共卫生问题,65岁以上的人是跌倒最严重的病变之一。也有一个事实,即瀑布会对老人的心态产生负面影响,从而导致自尊心低下,因为它变得依赖一个不断监视他的人,除了不断去医院旅行之外。一种自然而实用的方法,用于脆弱的E-SASO运动人员,并需要立即跌倒。因此,这项工作提出并评估计算视觉模型,以改善有跌倒风险的个人的监测和安全性,例如老年人或流动性降低的人。该模型包括一个生成神经网络,时空卷积块,光流计算,跟踪感兴趣区域的技术以及用于计算异常分数的饲料强制神经网络。分析模型与红外记录一起工作也很重要,因为在弱光环境中也可能发生跌倒。分析包括以不同组合应用各种图像处理过滤器和技术,以寻求找到满足高灵敏度和高F1分数的模型。使用RGB摄像机的最终神经网络模型达到99.21%的延迟性和0.98 F1得分,而使用红外摄像机的模型达到100%灵敏度和0.98的F1得分,超过了其他文献建议。异源评分技术已被证明具有一种很好的适应能力,即使在新视频场景中曝光,也能够识别跌倒,也是在实际情况下使用系统的理想选择。
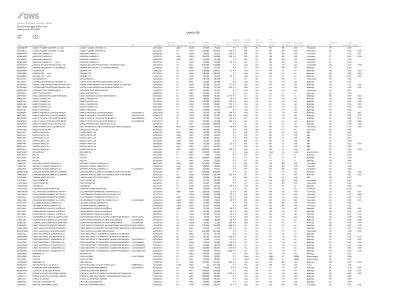
DGLS Holdings 2 28 25.xlsx
lq。 div>sr。 Cl。 div>z deutch全球连接系列Z IE00BYQNEZ75.75 DSB BRANS IN-NEW YOB BANKS)US23344/2334/2334 06/06/2025 CD Float 50.019 6 P-1 A-15000分支A-1 AA-1 A-1 A-1 A-F1 + AA-银行3.05 4.32 23344JCO0 DZ BANK在Deutchely轻轻地获得了中部中部中部中部中部中部中部英国中部中部享受银行FRAN1/07/205.000 9,581L DZ银行AE(新的AA2 AA2 A-1 A-1 A-1 A-F1 + AE-银行为0.60 31849HTD4 AAW的第一届阿布扎比银行Phu Dabi.30 a-no-第一个Ababi Biabi Biabi Blo 05/09/2025 CD Float 100,000 $ 100.139 25 A-1 + AA-NR NR NR Financals AE 0.61 4.56

rF1V 鼠疫疫苗与长效疫苗的共同配方...
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.

非住宅混合中乘员行为的建模...
在LaRéunion的热带岛屿上的非住宅混合模式建筑物的情况下,本文着重于乘员行为的建模。对于这样的领域和类型的建设,乘员可以操作被动解决方案以实现舒适度,而消耗能量的解决方案可以在最热的月份提供替代方案。,与其他气候区相比,有关居住者舒适和行为的具体知识是有限的,这使得在设计阶段的工程工作变得困难。在这项工作中,首先测量和分析了居民对湿润舒适控制的操作,例如窗口和风扇。其次,这些行为是使用基于机器学习技术和概率图形模型的两种确定性方法对这些行为进行建模的。也实施了使用电源渠道的电源需求来估算人数的模型。评估了行为模型的估计能力,并导致F1得分大于0.7。提出了一个两类模型,以估计风扇使用的水平。此组合模型略微提高了F1分数的2%,这证明了考虑到不同控件之间的链接的必要性。

使用基于堆栈的CNN-LSTM模型的先天性心脏病检测深度学习技术:一项试验研究
产前干预可以降低产后认真的冠心病患者的风险,但目前的诊断是基于定性标准,这可能导致临床医生之间的诊断差异。目的:使用深度学习模型检测患有低塑性左心脏综合征(HLHS)胎儿的心脏超声(US)视频的形态和时间变化。招募了一小部分健康和13名HLHS患者,并收集了三个妊娠时间点的超声视频。对视频进行了预处理并分段到心脏周期视频,并培训了五个不同的深度学习CNN-LSTM模型(Mobilenetv2,Resnet18,Resnet15,Resnet50,Densenet121和Googlelenet)。最佳表现的三个模型用于开发一种新型的堆叠CNN-LSTM模型,该模型是使用五倍的交叉验证对HLHS和健康患者进行分类的训练。堆叠CNN-LSTM模型的准确性,精度,敏感性,F1得分和90.5%,92.5%,92.5%,92.5%,92.5%和85%的精度,精度,敏感性,F1得分和特异性的准确性,精度,敏感性,F1得分和特异性分别优于其他预先训练的CNN-LSTM模型,分别是视频范围的分类以及90级分类和92。使用超声视频的主题分类分别为92.5%,92.5%和85%。这项研究表明,使用深度学习模型使用超声视频对CHD产前患者进行分类的潜力,该视频可以在临床环境中对疾病的客观评估进行分类。

用于重建NGS的聚类模型之间的性能比较来自技术重复
为了提高单个DNA测序结果的性能,研究人员经常使用同一个人和各种统计聚类模型的重复来重建高性能呼叫仪。在这里,考虑了基因组Na12878的三个技术重复,并比较了五个模型类型(共识,潜在类,高斯混合物,kamila - 适应性的K-均值和随机森林),涉及四个性能指标:敏感性,精度,精度,准确性和F1评分。与不使用组合模型相比,i)共识模型提高了精度0.1%; ii)潜在类模型带来了1%的精度改善(97% - 98%),而不会损害灵敏度(= 98.9%); iii)高斯混合模型和随机森林提供了更高精确度(> 99%)但敏感性较低的呼叫; iv)卡米拉提高了精度(> 99%),并保持高灵敏度(98.8%);它显示出最好的总体表现。根据精确和F1得分指标,比较了组合多个呼叫的非监督聚类模型能够改善测序性能与先前使用的监督模型。在比较模型中,高斯混合模型和卡米拉提供了不可忽略的精度和F1得分的改进。因此,可能建议将这些模型用于呼叫集重建(来自生物或技术重复),以进行诊断或精确医学目的。

放射治疗和肿瘤学
目标:本研究旨在探索多中心数据异质性对深度学习脑转移瘤 (BM) 自动分割性能的影响,并评估增量迁移学习技术,即不遗忘学习 (LWF),在不共享原始数据的情况下提高模型通用性的有效性。材料和方法:使用了来自埃尔朗根大学医院 (UKER)、苏黎世大学医院 (USZ)、斯坦福大学、加州大学旧金山分校、纽约大学 (NYU) 和 BraTS Challenge 2023 的总共六个 BM 数据集。首先,分别针对单中心专项训练和混合多中心训练建立 DeepMedic 网络的 BM 自动分割性能。随后评估了隐私保护双边协作,其中将预训练模型共享到另一个中心以使用迁移学习 (TL) 进行进一步训练(带或不带 LWF)。结果:对于单中心训练,在各自的单中心测试数据上,BM 检测的平均 F1 分数范围从 0.625(NYU)到 0.876(UKER)。混合多中心训练显著提高了斯坦福大学和纽约大学的 F1 分数,而其他中心的提高可以忽略不计。当将 UKER 预训练模型应用于 USZ 时,在组合 UKER 和 USZ 测试数据上,LWF 获得的平均 F1 分数 (0.839) 高于朴素 TL (0.570) 和单中心训练 (0.688)。朴素 TL 提高了灵敏度和轮廓绘制精度,但损害了精度。相反,LWF 表现出值得称赞的灵敏度、精度和轮廓绘制精度。当应用于斯坦福大学时,观察到了类似的性能。结论:数据异质性(例如,不同中心的转移密度、空间分布和图像空间分辨率的变化)导致 BM 自动分割的性能不同,对模型的通用性提出了挑战。LWF 是一种很有前途的点对点隐私保护模型训练方法。

用于深度学习脑转移瘤自动分割的多中心隐私保护模型训练
目标:本研究旨在探索多中心数据异质性对深度学习脑转移瘤 (BM) 自动分割性能的影响,并评估增量迁移学习技术,即学习而不遗忘 (LWF),在不共享原始数据的情况下提高模型通用性的有效性。材料和方法:使用了来自埃尔朗根大学医院 (UKER)、苏黎世大学医院 (USZ)、斯坦福大学、加州大学旧金山分校、纽约大学 (NYU) 和 BraTS Challenge 2023 的总共六个 BM 数据集。首先,分别针对单中心专项训练和混合多中心训练建立 DeepMedic 网络的 BM 自动分割性能。随后评估了隐私保护双边合作,其中将预训练模型共享到另一个中心以使用迁移学习 (TL) 进行进一步训练(带或不带 LWF)。结果:对于单中心训练,在相应的单中心测试数据上,BM 检测的平均 F1 分数范围为 0.625(NYU)至 0.876(UKER)。混合多中心训练显著提高了斯坦福大学和纽约大学的 F1 分数,而其他中心的改善可以忽略不计。当将 UKER 预训练模型应用于 USZ 时,在组合 UKER 和 USZ 测试数据上,LWF 获得的平均 F1 分数 (0.839) 高于朴素 TL (0.570) 和单中心训练 (0.688)。朴素 TL 提高了灵敏度和勾勒准确度,但损害了精度。相反,LWF 表现出令人称赞的灵敏度、精度和勾勒准确度。当应用于斯坦福大学时,观察到了类似的表现。结论:数据异质性(例如,不同中心的转移密度、空间分布和图像空间分辨率的变化)导致 BM 自动分割的性能不同,对模型的通用性构成挑战。LWF 是一种很有前途的点对点隐私保护模型训练方法。

多中心 - 私人 - 抛光模型 - 深度训练 -
目标:这项工作旨在探索多中心数据异质性对深度学习脑转移(BM)自动分量性能的影响,并评估增量转移学习技术的功效,即不忘记(LWF),以提高模型性能而无需共享原始数据。材料和方法:使用了埃尔兰根大学医院(UKER),苏黎世大学医院(USZ),斯坦福大学,纽约大学(纽约大学)和Brats Challenge 2023的六个BM数据集。首先,分别为单一中心训练和混合多中心训练建立了用于BM自动分量的DeepMedic网络的性能。随后评估了保护隐私的双边合作,其中有一个验证的模型将分享到其他带有LWF或不带有LWF的转移学习(TL)的进一步培训中心。结果:对于单中心训练,在各自的单中心测试数据上,BM检测的平均F1得分范围从0.625(NYU)到0.876(UKER)。混合的多中心训练明显提高了斯坦福大学和纽约大学的F1分数,其他中心的改进可以忽略不计。当将UKER预告量化的模型应用于USZ时,LWF的平均F1得分(0.839)比NAIVE TL(0.570)和单中心训练(0.688)高于UKER和USZ测试数据。幼稚的TL提高了灵敏度和轮廓精度,但会损害精度。相反,LWF表现出值得称赞的灵敏度,精度和轮廓精度。应用于斯坦福大学时,观察到类似的性能。结论:数据异质性(例如,转移密度,空间分布和图像空间分辨率的变化)导致BM自动分量的性能变化,从而对构建概括性提出了挑战。LWF是对点对点隐私模型培训的有前途的方法。