XiaoMi-AI文件搜索系统
World File Search Systemforecasting

射频识别预测
摘要 — 我们的研究假设是,通过设计基于停放和转发算法、射频识别 (RFID) 反馈和马尔可夫决策过程的新型集成制造企业系统,我们能够改善传统供应链管理 (SCM) 的健康状况。我们研究的目标是优化取决于 RFID 系统粘度的成本函数。RFID 的粘度可以定义为通过 RFID 网络的数据流。该过程可以通过信号停放和转发的熵来衡量,从而实现可持续的供应链系统。该系统的动态由微分方程控制。利用该熵模型,我们通过模拟验证了集成供应链健康制造系统风险故障降低。我们的方法采用模糊卡尔曼滤波器,改进了系统,减少了延期交货,并证明了 RFID 粘度是实现这一目标的有效手段。马尔可夫毯熵方法证明它可以捕获并提供 RFID 粘性停车和转发算法的理论,作为降低 SCM 成本、减少浪费和提高可持续性的网络解决方案。
射频识别预测
摘要 — 我们的研究假设是,通过设计基于停放和转发算法、射频识别 (RFID) 反馈和马尔可夫决策过程的新型集成制造企业系统,我们能够改善传统供应链管理 (SCM) 的健康状况。我们研究的目标是优化取决于 RFID 系统粘度的成本函数。RFID 的粘度可以定义为通过 RFID 网络的数据流。该过程可以通过信号停放和转发的熵来衡量,从而实现可持续的供应链系统。该系统的动态由微分方程控制。利用该熵模型,我们通过模拟验证了集成供应链健康制造系统风险故障降低。我们的方法采用模糊卡尔曼滤波器,改进了系统,减少了延期交货,并证明了 RFID 粘度是实现这一目标的有效手段。马尔可夫毯熵方法证明它可以捕获并提供 RFID 粘性停车和转发算法的理论,作为降低 SCM 成本、减少浪费和提高可持续性的网络解决方案。


1 AD26.COV2.s covid- ...
此预印本版本的版权持有人于2023年3月8日发布。 https://doi.org/10.1101/2023.03.07.23286952 doi:medrxiv preprint


国际应用预测杂志
这里的问题是,如果我们重新审视原始M4的结果(Makridakis及其同事,2020年,表4),我们将看到竞争实际上是通过方法ES-RNN赢得的,OWA的OWA为0.821。第二名是Fforma,OWA为0.838。陈述的OWA的时间网将将其置于第七位,在根本不使用深度学习的方法后面,甚至没有使用ML。这仍然不是一个不好的地方(在61名原始参与者中),但肯定不是SOTA,通常理解为方法是一种方法能够在该数据集中取得的最佳结果。另一个感兴趣的方面是他们对N-Beats的处理。这种方法不久前首次出现,正是通过声称在M4中实现SOTA的情况,其OWA为0.795(Oreshkin and Caleagues,2019,Table1)。时网确实确实报告了N-Beats的结果,但OWA为0.855。

预测石墨烯纳米颗粒的强度 - ...
comsats伊斯兰堡大学的土木工程系,阿伯塔巴德校园,22060,巴基斯坦b民事和基础设施工程系,阿拉伯联合阿拉伯联合酋长国美国拉斯阿拉伯大学公民与环境工程系新罕布什尔大学,新罕布什尔大学,杜勒姆大学,杜勒姆大学,纽约市,纽约市,纽约市,纽约市03824,美国纽约市,ard od od and ard osthair and arthair and arthha and ersield and ersision of Eromentan&eregrising and sardan and ersisiring of Ergemising and of Ergemisering and of Ergineering and preganies,运营,维护和声学,卢利亚技术大学民用,环境和自然资源工程系Sector H-12,伊斯兰堡,44000,巴基斯坦H军事工程师服务(MES),国防部(MOD),Rawalpindi,43600,巴基斯坦

可再生能源预测的未来
随着这些来源产生的能量的增加,对风和太阳能可再生能源的预测变得越来越重要。预测技能正在改善,但使用预测的方式也在提高。在本文中,我们简要概述了预测风能和太阳能的最先进。我们描述了在确定性和概率预测的统计和物理建模中的时间尺度的统计和物理建模方法。我们的重点会改变,然后考虑预测可再生能源的未来。我们讨论了最近的进步,这表明了预测技能的大幅提高的潜力。除了预测本身之外,我们考虑了新产品,这些产品将被要求进行决策受风险限制。未来的预测产品将需要包括概率信息,但以针对最终用户及其特定决策问题量身定制的方式进行交付。在该领域运营的业务可能会看到商业模式发生变化,因为越来越多的人在这个领域竞争,而不同产品所需的技能,数据和建模组合不同。数据本身的交易可能会随着区块链技术的采用而发生变化,这可以使提供者和最终用户可以以可信赖但分散的方式进行交互。最后,我们讨论了具有大量可再生能源的新行业需求和挑战。新的预测产品有可能建模可再生能源对电源系统的影响,并在保证系统安全方面进行辅助调度工具。
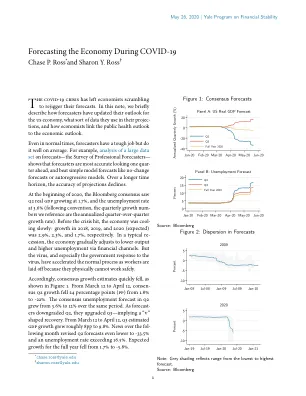
预测新冠肺炎疫情期间的经济
最近几周,一些高频数据点变得尤为重要。常用的高频指标的非详尽列表包括:谷歌移动报告、电影上座率、电力发电量、红皮书同店零售额、首次失业保险索赔、最终用户的燃料销售额、拉斯穆森消费者指数、美国劳动力指数、粗钢产量、美国运输安全管理局旅行者人数、破产统计数据、旧金山联储的新闻情绪,等等。谷歌移动数据尤其新颖,因为它提供了细粒度的位置数据,让人大致了解封锁有多严格以及有多少劳动力比例待在家里。纽约联邦储备银行现在发布每周经济指数,该指数将几个高频指标汇总到 GDP 单位。

可再生能源预测的未来
随着风能和太阳能可再生能源发电量的增加,对这些能源的预测变得越来越重要。预测技能正在提高,但预测的使用方式也在提高。在本文中,我们简要概述了风能和太阳能预测的最新进展。我们描述了从几分钟到几天时间尺度的统计和物理建模方法,包括确定性和概率性预测。然后我们的重点转移到考虑可再生能源预测的未来。我们讨论了最近的进展,这些进展表明预测技能有巨大的改进潜力。除了预测本身,我们还考虑了在风险约束下辅助决策所需的新产品。未来的预测产品将需要包含概率信息,但要以适合最终用户及其特定决策问题的方式提供这些信息。随着越来越多的人在这个领域竞争,在这个领域运营的企业可能会看到商业模式的变化,不同的产品需要不同的技能、数据和建模组合。随着区块链技术的采用,数据交易本身可能会发生变化,区块链技术可以让提供商和最终用户以可信但去中心化的方式进行交互。最后,我们讨论了可再生能源大量使用的情况下的新行业要求和挑战。新的预测产品有可能模拟可再生能源对电力系统的影响,并帮助调度工具保证系统安全。