XiaoMi-AI文件搜索系统
World File Search Systemfound

发现爱的劳动:社会关怀和工业战略......
成人社会护理部门体现了生育劳动力贬值的不良后果。但它只是更广泛的基础经济中遭受这种贬值的众多部门之一;其他例子包括零售、清洁和儿童保育。虽然女性——尤其是移民和少数民族女性——往往在基础经济劳动力中占比过高,但她们并不是唯一受到影响的群体。发展中国家传统产业的崩溃或结构调整越来越多地迫使男性寻求在基础部门就业。而且,不仅仅是这些部门的雇员遭受其贬值的后果。恶劣的工作条件及其所暗示的服务质量下降,可能会对广大民众的日常生活质量产生重大连锁反应。

丢失还是发现?理解南非的基准...
摘要从约翰内斯堡间的平均平均值(Jibar)到南非兰特通过夜指数平均值(Zaronia)的过渡是南非金融市场的关键转变,旨在提高透明度和稳健性。与南非储备银行(SARB)实施这种分阶段的过渡,了解其财务影响至关重要。本文通过风险分析的全面价值(VAR)探讨了这种变化的影响,并检查了与金融工具有关的交易对方信用风险。使用带有随机跳跃的Cox-Ingersoll-Ross(CIR)模型,模拟了Jibar和Zaronia之间的正向扩散,表明尽管预期速率收敛,但波动率仍然存在。对潜在的未来暴露(PFE)的分析表明,遗留吉巴链路链接的工具仍然具有很大的风险。虽然整体过渡看起来顺利,不确定性,但受波动性和经济冲击的驱动,但需要仔细的管理。转变的成功依赖于有效的风险管理策略和SARB与市场参与者的清晰沟通。

今天的演示可以在Neste的网站上找到
以下信息包含或可能被视为包含“前瞻性陈述”。这些陈述与未来的事件或我们未来的财务绩效有关,包括但不限于战略计划,潜在的增长,计划的运营变化,预期的资本支出,未来的现金来源和需求,流动性和成本节省,涉及已知和未知的风险,不确定性和其他因素,这些因素和其他因素可能会因其实际上或其其表达的成果,绩效的层次而造成的,或者在其上构成的层次,或者构成界面的级别,绩效,或者构成的效果,绩效,绩效,效果或成就级别,这些因素或其他因素是界面的,效果或成就级别语句。在某些情况下,可以通过术语来识别此类前瞻性陈述,例如“可能”,“意志”,“可能”,“将”,“应该”,“应该”,“期望”,“预期”,“预期”,“预期”,“相信”,“相信”,“估计”,“估计”,“预测”,“继续”,“继续”或“继续”或“继续”或“继续”,或这些术语的负面术语或其他比较术语或其他术语。

您可在 CCMS 网站上找到每门选修课的完整描述。
CTE 学期课程 工程学 1—技术设计探索 本课程旨在让学生有机会探索技术设计技术领域及其相关职业。学生将有机会使用各种工具、材料、流程和系统解决技术问题,同时了解技术设计技术对我们日常生活的影响。 工程学 2—绿色建筑探索 (8600590Z) 本课程旨在让学生有机会探索绿色建筑和建筑技术领域及其相关职业。学生将有机会使用各种工具、材料、流程和系统解决技术问题,同时了解绿色建筑和建筑技术对我们日常生活的影响。

Mankai植物发现糖尿病患者的餐后糖水平
该试验涉及45名参与者患有糖尿病和糖基化血红蛋白(A1C)水平在6.5%至8.5%之间。参与者被随机分配为食用300毫升的曼凯饮料或晚餐后两周的水量,然后再进行干预措施再进行两周。使用葡萄糖传感器和标准实验室连续监测血糖水平

化合物的定量LC-MS研究发现了COVID-19的严重程度和结果
总结在表1中的同类人群,由皇家利物浦大学医院(RLUH)组成141例患者,其中46例是对照组,而95例则为阳性。95个SARS-COV-2阳性患者是先前的发现和验证队列(Roberts等,2022)的子集,其中保留了足够的样品材料。COVID-19患者涵盖了28例轻度,23例中间和44例严重病例,随后有23例来自严重病例组的已故患者。严重的病例是根据启发的氧气(FIO 2)> 40%和/或所需的连续正气道压力(CPAP)和/或所需的侵入性通气和/或无法生存的持续正气道压力(CPAP)定义的。中间病例需要呼吸支持,但在严重患者和轻度病例的程度上不需要任何呼吸支持。

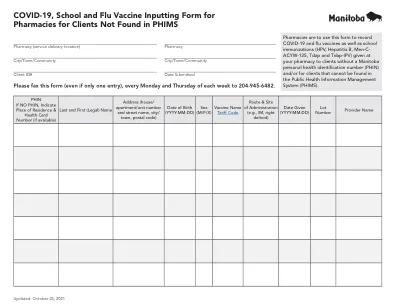
COVID-19,用于药房的学校和流感疫苗输入形式,用于PHIMS中未找到的客户
药房应使用此形式记录相互疫苗-19和流感疫苗以及学校免疫接种(HPV,乙型肝炎,Men-C- Acyw-135,TDAP和TDAP-IPV),向没有Manitoba个人健康识别号(PHIN)和/或无法在公共健康信息中找到的客户提供给没有Manitoba个人健康识别号(PHIN)的客户(phIM)的客户(PHIM)(PHIM)。

如果在 TDRL 重新评估中 PEB 认定我适合任职,会怎样?
什么是 TDRL?临时伤残退休名单 (TDRL) 是体能评估委员会 (PEB) 确定的因医疗原因暂时退役的士兵名单,这些士兵的一种或多种医疗状况尚未稳定到足以进行永久评估。最初将士兵列入 TDRL 的决定确定了 TDRL 重新检查的时间范围。在 TDRL 期间,士兵将以至少 50% 的残疾率暂时退役并维持平民生活。根据 PEB 发现的不稳定状况,士兵将在退役后六个月后(最长 18 个月)收到通知,接受 TDRL 重新检查。差旅费由陆军支付。陆军医生将重新评估需要列入 TDRL 的医疗状况。重新检查完成后,PEB 将根据新检查结果和医疗记录确定士兵的状况是否稳定,如果稳定,则确定士兵是否适合重返岗位。如果发现不适合,PEB 还将确定目前稳定的不适合状况的残疾等级,除非退伍军人事务部 (VA) 之前已重新评估不稳定状况并应用了永久性残疾等级。TDRL 重新评估通常每 12-18 个月进行一次。TDRL 限制不超过三年。

云 - 放射反馈发现是多种热带太平洋变暖预测的关键
东太平洋:东太平洋驱动器上的不同云 - 放射反馈不同,厄尔尼诺尼诺般的变暖大小。这是模型中预计TPSW的不确定性的主要来源,尤其是在远东赤道太平洋中。中太平洋:中部太平洋上的不同负云 - 放射反馈,再加上海洋 - 大气相互作用,包括风蒸发 - SST(WES)(WES)反馈和BJERKNES的反馈,决定了西太平洋的不同变暖。大多数模型低估了这种负面反馈,从而导致西太平洋的预测比多模型平均水平更强。