XiaoMi-AI文件搜索系统
World File Search Systemgaps

估算水稻 SDP 项目区作物产量差距
在新冠疫情导致的封锁和行动限制期间,赖斯 SDP 项目管理部门在全球农业和粮食安全计划 (GAFSP) 的资金支持下探索了远程监控项目实施的方法。为了估计每个作物季节项目受益人的生产力提高情况,数据科学家和人工智能专家绘制了地块边界,估计了单个地块的作物产量,并根据作物调查、卫星数据和对被调查的单个地块的地理标记,绘制了九个灌溉方案内估计产量的分布图。

食品安全预测过敏原预测的研究差距和未来需求
食品安全中的过敏性和蛋白质风险评估正面临着新的挑战。对更健康,更可持续的食品系统的需求导致了生物技术的显着进步,更复杂的食物的开发以及寻找替代蛋白质来源。所有这一切都增加了对安全评估预测方法的压力,该方法固定在90年代后期定义的要求中。 2022年,EFSA关于遗传修饰的生物的小组发表了一种科学意见,重点介绍了对生物技术产生的新产品所需的发展和蛋白质安全评估所需的发展。在这里,我们进一步详细介绍了该科学意见中描述的主要要素,并优先考虑需要关注的发展需求。任何新建议的起点将需要关注临床相关性以及针对特定风险评估目标的目标数据库的开发。此外,必须审查和阐明过敏性风险评估的主要目的。就过敏性风险评估的总体目的达成了国际商定的共识,将加速使用方法的方法,在这种方法中,应该更好地确定暴露的作用。考虑到过去25年中获得的经历以及生物技术,过敏和风险评估领域的最新科学发展,现在是时候修改和改善过敏性安全评估,以确保对未来食品的过敏性评估的可靠性。

非洲痴呆症:当前的证据,知识差距和未来方向
在全球范围内,阿尔茨海默氏病和其他痴呆症构成了主要的公共卫生优先事项,具有实质性的负面个人,社会和经济影响。1,2世界卫生组织(WHO)目前的估计表明,到2050年,有1.5亿人比2017年增加了204%,将患有痴呆症。3,4迹象表明,这些增加中的大多数将在包括非洲境内在内的低收入和中等收入国家(LMIC)中找到。3–5全球,痴呆症是死亡的第5个主要原因,也是神经系统疾病死亡的第二大贡献者。最近的6个估计表明,每年在全球痴呆症相关护理上花费了超过8180亿美元,到2028年,全球痴呆症护理的成本估计为20万亿美元。7这些包括直接医疗以及其他正式和非正式的健康和社会护理费用。

白皮书 马来西亚癌症治疗的挑战、差距和机遇
在新冠疫情期间,估计 2020 年马来西亚约有 49,000 人新诊断出癌症,预计到 2030 年,这一数字将上升至每年 66,000 多例。4 几十年来,马来西亚通过其卫生系统,特别是通过公共医疗服务,在癌症治疗的全民覆盖方面取得了进展。然而,有效的癌症控制仍然难以实现,这种疾病仍然摧毁着成千上万的生命、家庭和社区。预防和治疗癌症的干预措施必须应对具有挑战性的环境,包括疾病的晚期表现、人口老龄化、快速城市化、不活跃和久坐的生活方式以及不健康的饮食。疾病的晚期表现导致晚期癌症的患病率很高,自 1990 年代以来一直是一大障碍,当时槟城癌症登记处首次发现 53% 的病例是在 III 期和 IV 期被诊断出来的。5 这往往导致诊断和治疗的延误,从而导致更差的结果和低

将生物多样性数据中的差距和偏见视为缺失的数据问题
大生物多样性数据集具有较大的分类,地理和时间范围,具有监测和研究的巨大潜力。此类数据集对于评估物种种群和分布的时间变化尤为重要。可用数据中的差距,尤其是空间和时间差距,通常意味着数据不能代表目标人群。这阻碍了大规模推论,例如关于物种的趋势,并可能导致放错了保护作用。在这里,我们概念化了生物多样性监视数据的差距是缺少的数据问题,该数据为不同类型的生物学数据集的挑战和潜在解决方案提供了一个统一的框架。我们将典型的数据差距类型表征为不同类别的缺少数据类别,然后使用丢失的数据理论来探讨有关物种趋势和影响事件/丰富性的因素的含义。通过使用此框架,我们表明,当影响采样和/或数据可用性与影响物种的因素重叠时,可能会由于数据差距而产生的偏差。,但数据集本身没有偏见。结果取决于生态问题和统计方法,该方法确定了围绕哪些变异来源考虑的选择。我们认为,使用监视数据进行长期物种趋势建模的典型方法特别容易受到数据差距的影响,因为这种模型不倾向于说明驱动缺失的因素。为了确定解决此问题的一般解决方案,我们回顾了实证研究并使用仿真研究来比较一些最常使用的方法来处理数据差距,包括亚采样,加权和插补。所有这些方法具有减少偏差的潜力,但可能以增加参数估计的不确定性成本。加权技术可以说是迄今为止生态学中最不使用的,并且具有减少参数估计的偏差和方差的潜力。无论方法如何,降低偏见的能力都取决于对数据差距的知识和数据的可用性。在处理数据收集和分析工作流的不同阶段的数据差距时,我们使用此评论概述了必要的考虑。
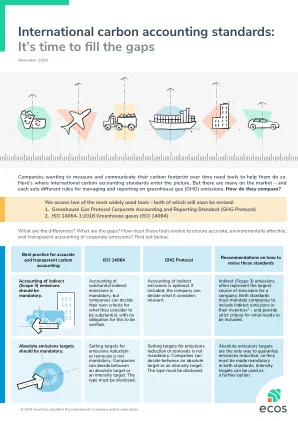
国际碳会计标准:是时候填补空白
消耗的脱碳电力应额外匹配,并与实际生产相匹配。这可以通过以市场为基础的会计获得严格的质量标准来实现,以确保声称绿色电力的添加性(如长期PPA)。其他方法,例如可再生能源证书和原产地保证,不足。

将生物多样性数据中的差距和偏见视为缺失的数据问题
大生物多样性数据集具有较大的分类,地理和时间范围,具有监测和研究的巨大潜力。此类数据集对于评估物种种群和分布的时间变化尤为重要。可用数据中的差距,尤其是空间和时间差距,通常意味着数据不能代表目标人群。这阻碍了大规模推论,例如关于物种的趋势,并可能导致放错了保护作用。在这里,我们概念化了生物多样性监视数据的差距是缺少的数据问题,该数据为不同类型的生物学数据集的挑战和潜在解决方案提供了一个统一的框架。我们将典型的数据差距类型表征为不同类别的缺少数据类别,然后使用丢失的数据理论来探讨有关物种趋势和影响事件/丰富性的因素的含义。通过使用此框架,我们表明,当影响采样和/或数据可用性与影响物种的因素重叠时,可能会由于数据差距而产生的偏差。,但数据集本身没有偏见。结果取决于生态问题和统计方法,该方法确定了围绕哪些变异来源考虑的选择。我们认为,使用监视数据进行长期物种趋势建模的典型方法特别容易受到数据差距的影响,因为这种模型不倾向于说明驱动缺失的因素。为了确定解决此问题的一般解决方案,我们回顾了实证研究并使用仿真研究来比较一些最常使用的方法来处理数据差距,包括亚采样,加权和插补。所有这些方法具有减少偏差的潜力,但可能以增加参数估计的不确定性成本。加权技术可以说是迄今为止生态学中最不使用的,并且具有减少参数估计的偏差和方差的潜力。无论方法如何,降低偏见的能力都取决于对数据差距的知识和数据的可用性。在处理数据收集和分析工作流的不同阶段的数据差距时,我们使用此评论概述了必要的考虑。

围绕淡水软体动物生态系统服务的知识获得和差距
摘要生态系统为包括食物,水,气候调节和审美体验在内的人们提供必不可少的服务。生物多样性可以增强和稳定生态系统功能,并提供自然系统提供的服务。淡水软体动物是一个多元化的群体,通过其喂养习惯(例如过滤器喂养,放牧),对食物网的自上而下和自下而上的影响,提供各种生态系统服务,提供栖息地,提供栖息地,用作人们的食品资源以及文化重要性。研究重点是量化软体动物影响生态系统服务的直接和间接方式,可以帮助政策制定者和公众了解软体动物社区对社会的价值。淡水软体动物保护协会强调了在其2016年国家保护本地淡水软体动物的国家战略中评估软体动物生态系统服务的必要性,尽管已经取得了显着的进步,但在整个研究,管理和外展社区中取得了大量的工作,但仍有大量工作。我们将回顾本地淡水软体动物的全球状况,评估有关其生态系统服务的当前知识状态,并重点介绍最近的进步和知识差距,以指导进一步的研究和保护行动。我们的意图是为生态学家,保护主义者,经济学家和社会科学家提供信息,以改善基于科学的软体动物社区对健康水生系统的社会,生态和经济价值的考虑。

设计以人为本的人工智能系统时的要求、实践和差距
背景:工程人工智能 (AI) 软件是一个相对较新的领域,面临许多挑战、未知数和有限的经过验证的最佳实践。谷歌、微软和苹果等大公司提供了一套最新指南,以帮助工程团队构建以人为本的 AI 系统。目标:目前从业者为开发此类系统所采用的实践,尤其是在需求工程 (RE) 期间,迄今为止很少被研究和报道。方法:本文介绍了一项调查的结果,该调查旨在了解 AI 需求工程 (RE4AI) 的当前行业实践,并确定应遵循哪些以人为本的关键 AI 指南。我们的调查基于对现有行业指南、最佳实践和文献中的努力的映射。结果:我们调查了 29 名专业人士,发现大多数参与者都同意我们映射的所有以人为本的方面都应该在需求工程中得到解决。此外,我们发现大多数参与者都在使用 UML 或 Microsoft Office 来提出需求。结论:我们发现,目前使用的大多数工具都没有配备管理基于 AI 的软件的功能,而使用 UML 和 Office 可能会对捕获 AI 需求的质量造成问题。此外,指南中映射的所有以人为本的实践都应包含在 RE 中。© 2023 作者。由 Elsevier B.V. 出版。这是一篇根据 CC BY-NC-ND 许可开放获取的文章(http://creativecommons.org/licenses/by-nc-nd/4.0/)。

非洲负责任的人工智能政策与法规:差距与前进方向
在非洲,与人工智能接触时间最长的人口是年轻一代。这是因为人工智能作为数字领域的下一个新兴技术,已经在非洲站稳脚跟。因此,随之而来的问题之一是,非洲是否已准备好在政策基础设施方面深入人工智能世界,造福其人民。考虑到这一点,了解政策干预生态系统将是一项重要的任务,即使人工智能干预仍然是向非洲大陆提供解决方案的平台。需要有证据来指导政策制定和部署战略,以成功开发受监管且为预期接受者所接受的负责任的人工智能。因此,这项研究对非洲国内外现有的负责任人工智能对话做出了重要贡献。本研究采用探索性研究。