XiaoMi-AI文件搜索系统
World File Search Systemimage

基于自然图像统计特征的剪接图像检测算法的研究
1 University of Electronic Science and Technology of China, School of Computer Science & Engineering (School of Cybersecurity), Digital Media Technology, Chengdu, Sichuan, China 2 The University of Chicago, The Division of the Physical Sciences, Analytics, Chicago, IL, USA 3 University of Electronic Science and Technology of China, School of Integrated Circuit Science and Engineering (Exemplary School of Microelectronics), Microelectronics Science and工程,成都,四川,中国4号华盛顿大学,位于圣路易斯,奥林商学院,金融,圣路易斯,莫5哥伦比亚大学,FU工程基金会和应用科学学院,运营研究,纽约,纽约,纽约,纽约州a xiangao1434964964935@gmail@gmail.com,bimonajue.com,bsimonajue.com@yconajue.com@yqmail.com,dd99797979. liyang.wang@wustl.edu,e yucheng576@gmail.com

使用 Python 探索图像处理
深度学习的兴起:卷积神经网络 (CNN) 等深度学习技术越来越多地用于图像分类、对象检测、分割等,这将巩固 Python 作为首选语言的主导地位。基于云的图像处理:随着向云计算的转变,Python 利用基于云的资源处理大规模图像处理工作负载的能力将成为一大优势。边缘计算:Python 适用于资源受限的环境,这使其成为边缘计算场景的关键,在这种场景中,图像处理任务在更靠近数据源的设备上执行。实时应用:Python 的效率和低延迟对于实时图像处理应用(如自动驾驶汽车、医学图像分析和增强现实)至关重要。可解释的人工智能和人机系统:随着对图像处理算法的透明度和可解释性的需求不断增长,Python 的可解释人工智能和人机系统工具将变得非常宝贵。
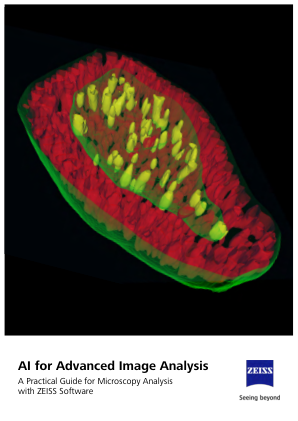
用于高级图像分析的人工智能
图 4:(a) 高压冷冻的 HeLa 细胞 FIB-SEM 体积切片。样品由 EMBL 的 Anna Steyer 和 Yannick Schwab 提供。(b) 传统机器学习的分割结果。使用在预训练的 VGG16 模型中应用第一个卷积层获得的特征来训练随机森林算法。该模型使用 ZEISS ZEN 软件中的 AI 工具包进行训练。(c) 该图描绘了与 (b) 相同的结果,不同之处在于使用条件随机场清理了输出以去除孤立像素。虽然分割能够检测到来自线粒体的大多数像素,但无法识别这些物体中的大量像素,因此很难将它们与背景完全区分开来。此外,大量非线粒体像素被错误地标记为线粒体。

Shotzr AI 图像资产
我们采用一流的深度学习来应对图像位置数据的挑战。这种方法大大降低了将位置数据应用于每幅图像的成本。无论是识别社交帖子中出现的零售地点,还是评估 1 亿张图像的位置,LocationID 都可以扩展以提供图像的位置标签。

住房 - UFDC 图像阵列 2
18-19 超低能耗住宅创造新基准,作者:Justin Ward 19 GSA 呼吁提名房地产奖 20-21 布拉格堡回收利用延长垃圾填埋场使用寿命,作者:Tom McCollum 21 路易斯维尔完成安装环境研究,作者:Todd Hornback 22-23 斯图尔特堡通过回收利用成功进入社区,作者:Ron King 23-24 燃料囊 - 一个“持续”问题,作者:Dale Amberger 和 Paul B. Olsen 中校 24-25 PWTB 关注具有修复潜力的本地物种,作者:Ryan Busby 25 PWTB 解决选址范围的环境考虑因素,作者:Heidi Howard 和 Niels Svendsen 26 不可能但却是事实:平民住在军用住房中,作者:Heather D. Lettow

Abaconian - UFDC 图像阵列 2
ufl.edu › ... PDF 2000 年 8 月 25 日 — 2000 年 8 月 25 日 一架双引擎 Cessna 402-B 载着流行的 R&B 歌手 Aaliyah 和七个...飞机右翼的油箱...可靠性。

迈向图像标准化评估...
数字机载相机系统及其高几何分辨率要求新的算法和图像数据分析和解释程序。描述图像质量的参数对于各种应用领域都是必需的(例如传感器和任务设计、传感器比较、算法开发、仪器在轨行为)。有效传感器分辨率是一个重要参数,它全面评估给定成像传感器-镜头组合的光学质量。虽然分辨力的测定是一个研究得很好的领域,但在标准化(最终是绝对的)测定方面仍有一些科学问题需要回答。这也是“德国标准化研究所”委员会的研究对象,给出的贡献概述了有关机载相机系统有效分辨力的当前研究状态。因此,将描述一种使用信号处理技术来计算有效图像分辨率的方法。将介绍、解释和回答一些尚未解决的科学问题。


和多波束声纳后向散射图像
(https://maps.ccom.unh.edu/portal/apps/webappviewer/index.html?id=28df035fe82c423cb3517295d9 bbc24c#. 2021 年 12 月 10 日) ........................................................................................................................... 20 图 19:R/V Gulf Surveyor (http://ccom.unh.edu/facilities/research-vessels/rv-gulf-surveyor)。 .......... 21 图 20:RVGS 图,其中包含关键位置和拖曳点相对于船舶参考点的偏移(未按比例绘制)。 ............................................................................................................................. 21 图 21:安装了拖缆的 R/V Gulf Surveyor 甲板上的 Klein 4K-SVY 侧扫。 ............................................................................................. 23 图 22:具有声学阴影、距离尺度、第一次回波和水柱的典型 SSS 数据示例。 ........................................................................................................................................................... 24 图 23:带有集成表面声速探头的 Kongsberg EM2040P MBES。 (https://www.kongsberg.com/maritime/products/ocean-science/mapping-systems/multibeam-echo- sounders/em-2040p-mkii-multibeam-echosounder-max.-550-m/) ........................................................................... 25 图 24:安装在 R/V Gulf Surveyor 中心支柱上的 EM2040P(照片:NOAA 的 Patrick Debroisse 中尉)。 ........................................................................................................................................... 26 图 25:在 50m 范围内布置用于位置置信度检查的 SSS 线。 ........................................................................... 27 图 26:相对于 MBES 目标位置(红色)的 SSS 接触位置(蓝色)。 ......................... 28 图 27:地理参考框架和船舶参考框架中的接触位置误差。接触位置主要位于 MBES 位置的东面。 ......................................................................... 28 图 28:应用地图校正后的 SSS 接触位置。 ......................................................................... 29 图 29:应用地图校正后,在地理和船舶参考框架中看到的 SSS 接触位置 ............................................................................................................................. 29 图 30:测量区域,其中 60m 和 80m 线路平面图以红色显示。 ........................................................................... 30 图 31:掩盖马赛克(左)隐藏接触,透过马赛克(右)显示接触。 ...... 32 图 32:使用自动所有数据,显示应用增益和定位校正之前的所有线路的 SSS 马赛克。覆盖在 RNC 13283 上。...................................................................................................... 33 图 33:使用 Auto-All 数据可视化应用地图校正和 EGN 后的 SSS。....... 34 图 34:DTM(顶部)显示折射伪影,与 ping 数据(底部)中看到的伪影相同。...................................................................................................................................................................... 35 图 35:EM2040P MBES 数据的全覆盖 DTM............................................................................................................. 36 图 36:EM2040P 数据从天底滤波到 45º 后的 DTM。............................................................................. 37 图 37:EM2040P 以 300 kHz 和 50cm 分辨率收集的 MBAB。西北采集点在左侧,东南采集点在右侧。后向散射强度以分贝表示,默认比例为 10 到 -70dB。 ........................................................................................................................... 38 图 38:调整后的 NW MBES 数据可视范围为 -4 至 -28db.................................... 39 图 39:SSS 接触位置(左)和 MBES 假定的“真实”位置(右)。........................................ 40 图 40:应用地图校正后的 SSS 接触位置。原始 SSS 位置以绿色标记标注。............................................................................................................. 41 图 41:地图校正前(左)和地图校正后(右)的另一个示例,最初显示两条独立的龙虾笼线。............................................................................................. 41 图 42:应用地图校正后,两条 SSS 线之间的差异约为 7.5 米。红色框突出显示了沙波应重叠的区域。............................................................................. 42 图 43:NW 采集站点:叠加之前的 MBES(顶部)、SSS(中)和 MBES 后向散射(底部)。 ........................................................................................................................................................... 44 图 44:SE 采集点:叠加前的 MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)。 ........................................................................................................................................... 45左侧为西北方向采集点,右侧为东南方向采集点。后向散射强度以分贝表示,默认范围为 10 至 -70dB。 ........................................................................................................................... 38 图 38:调整后的西北方向 MBES 数据可视范围为 -4 至 -28db........................................ 39 图 39:SSS 接触位置(左)和 MBES 假定的“真实”位置(右)。............................................................. 40 图 40:应用地图校正后的 SSS 接触位置。原始 SSS 位置以绿色标记标注。 .................................................................................................................... 41 图 41:地图校正前(左)和地图校正后(右)的另一个示例,最初显示两条独立的龙虾笼线。 .................................................................................................................... 41 图 42:应用地图校正后,两条 SSS 线之间的差异约为 7.5 米。红框突出显示了沙波应该重叠的区域。 ........................................................................... 42 图 43:NW 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 44 图 44:SE 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 45左侧为西北方向采集点,右侧为东南方向采集点。后向散射强度以分贝表示,默认范围为 10 至 -70dB。 ........................................................................................................................... 38 图 38:调整后的西北方向 MBES 数据可视范围为 -4 至 -28db........................................ 39 图 39:SSS 接触位置(左)和 MBES 假定的“真实”位置(右)。............................................................. 40 图 40:应用地图校正后的 SSS 接触位置。原始 SSS 位置以绿色标记标注。 .................................................................................................................... 41 图 41:地图校正前(左)和地图校正后(右)的另一个示例,最初显示两条独立的龙虾笼线。 .................................................................................................................... 41 图 42:应用地图校正后,两条 SSS 线之间的差异约为 7.5 米。红框突出显示了沙波应该重叠的区域。 ........................................................................... 42 图 43:NW 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 44 图 44:SE 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 45........... 42 图 43:NW 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 44 图 44:SE 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 45........... 42 图 43:NW 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 44 图 44:SE 采集点:MBES(顶部)、SSS(中间)和 MBES 背向散射(底部)在叠加之前。 ............................................................................................................................................................. 45

yashtech aes working.cdr-图像
企业现在比以往任何时候都更需要建立业务弹性并确保面对情况的连续性。随着重点的重新关注,企业需要重新想象他们稳定和控制业务的工作方式。使用光学角色识别和数据捕获解决方案捕获所有您可以的一切,这将确保您需要的所有内容都以可操作的方式存储。