XiaoMi-AI文件搜索系统
World File Search Systemlf

doh-administrative-rorder-no-2021-0001.pdf
2018 - 2022年的菲律宾LF可持续发展计划是作为一份工作文件发布的,详细介绍了将国家战略转化为具体行动,是实现程序化目标所需的人类,技术和财务资源的蓝图,以及衡量菲律宾实现LF消除LF的变化和记录进度的指南。上述计划的两个主要目标是1。)加强持续感染省份的干预措施和中断传播和2.)加强发病率管理和预防残疾活动,以减轻慢性病患者的痛苦。
产品列表 - 疫苗 - 印度
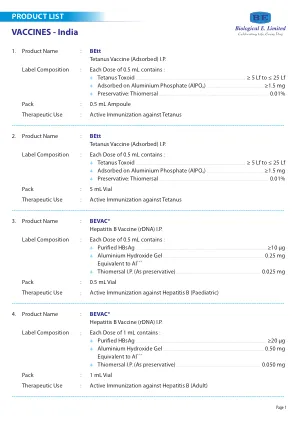
标签成分: 每剂量 0.5 mL 含: 白喉类毒素 ≥30 IU(≥20 Lf 至 ≤30 Lf)S .............................................................. 破伤风类毒素 ≥60 IU(≥5Lf 至 ≤ 25 Lf)S .............................................................................. 百日咳杆菌(全细胞) ≥4 IU S ............................................................................................. r-HBsAg 12.5 µg S ............................................................................................................. (毕赤酵母产生的重组 HBs 抗原) 纯化的 Hib 荚膜多糖 (PRP) S 与 20 至 36.7 µg 破伤风类毒素 11 µg 共价连接 .............................................

乳铁蛋白,先天免疫的月光蛋白质
乳铁蛋白(LF)是一种天然存在于先天免疫的糖蛋白,在牛牛奶中首先发现[1],后来是从人牛奶中纯化的[2]。近年来,由于其多种功能和应用,LF对不同领域的研究人员变得越来越有吸引力。除了最初发现的抗菌作用[3]外,LF当前被公认为是一种有效的多目标营养素,并具有免疫调节性[4] [4],抗渗透性[5],抗氧化剂[3],抗氧化剂[3]和抗癌症[6]。值得注意的是,LF显示了广泛的耐受性,被分类为美国食品药品监督管理局[7]的“通常被认为是安全的(GRAS)物质[7],并由欧洲食品安全局[8]作为饮食补充。在机械水平上,LF发挥的某些功能与其铁结合能力和高度阳离子电荷有关,这使其能够与宿主和病原体受体和抗原的广泛曲目相互作用[9,10]。但是,其大多数生物学效应尚未得到充分的欣赏和揭幕。此外,LF最近已成为用于递送生物活性纳米颗粒的有效载体[11,12]。这个特殊问题,标题为“乳铁蛋白是先天免疫的月光蛋白质”,其中包括五种供出版的文章。Bukowska-o´sko及其同事回顾了有关LF捍卫宿主免受化学和生物学剂诱导的DNA损害的能力的最新研究[13]。Bukowska-o´sko等人的评论。有趣的是,有益的效果这种DNA结构和序列的这种变化会导致过早衰老,细胞变性和死亡,从而导致严重的组织和器官衰竭[14]。几种包括癌症在内的疾病与此过程有关,因此最近的研究集中在可以抵消/逆转这些作用的有希望的化合物上[15,16]。在这种情况下,已进化为预防疾病和修复受损的遗传物质的天然产品正在成为安全,耐受性和辅助物质,以维持身体体内平衡,包括基因组完整性。介绍了LF在保护人类遗传物质免受内部和外部损害的保护中的新作用,这是通过其所有水平和修复机制的细胞周期调节机制描述的[13]。作为祖先的监护人,LF针对病原体及其后遗症的主要防御活动在本期特刊的不同研究中已剖析。li及其同事研究了LF给药在脂多糖(LPS)诱导的肠道免疫屏障损伤模型中的有益作用[17]。肠道的先天性障碍在人类健康中起着至关重要的作用,尤其是在婴儿和患有未成熟免疫系统的婴儿和幼儿中[18]。首先,在小鼠肠道组织,胃组织和血液中,LF的药代动力学分析表明,口服膨胀的效率更高,以改善腹膜内注射的LF生物利用度。另外,通过体外和体内模型的婴儿肠道免疫屏障大坝,LF被证明可以显着提高LPS诱导的原发性肠上皮细胞的存活率,并下调了脑膜细胞因子的表达在原发性肠上皮细胞和小鼠的血液中,干扰素(IFN)-γ。

pqca.pdf
指示基金参与协议感谢您对加入Quantum Cryptography Alliance(“指导基金”)的兴趣,这是Linux Foundation的指示基金项目(“ LF”)。指示基金的目的是筹集,预算和支出资金,以支持各种开源数据,开放数据和/或与量化后密码学有关的开发和促进项目,包括基础架构和与之相关的计划(每个这样的项目,一个“技术项目”)。指示基金的治理将根据指示基金宪章(“宪章”)的运作,并以展览B为B,并在未来由指导基金的理事委员会在LF批准的情况下修改。请注意,您必须是LF的成员,必须有资格作为指导基金的成员参加。有关更多信息,请访问LF网站的公司会员页面。参与者将享受特权,并承担宪章中描述的义务,并遵守LF董事会和/或有指导基金的理事委员会等所有这些政策,可能会不时地收养并通知会员。LF保留拒绝具有已偿还付款义务或其他LF指示资金的成员提交的任何参与协议的权利。该技术项目的适用技术宪章中规定了任何技术项目的技术监督治理。请由名为下面的会员公司的授权代表执行此参与协议(“协议”)(“成员”)。如果不使用电子签名系统,请通过电子邮件发送pdf表格的副本至会员effermhip@linuxfoundation.org。当您的有资格确认会员资格并将发票发送给您以支付适用会员费用时,将通过电子邮件向您退还给您以获取记录。请注意,这不是关注的迹象;该协议的执行为会员公司造成了不可撤销的,具有约束力的义务,以便根据其条款提供付款并以其他方式执行。联系信息:如果您是现有的LF成员,则与您参与有关的LF的所有法律,计费和财务通知都将发送给已与LF一起存档的个人,除非您在展览中指定其他个人。会员水平和费用:成员资格水平和费用在图表C中定义。Premier会员条款:Premier会员资格要求最初的两年会员资格承诺。一年的费用应作为会员的接受,第二年的费用应在成员成立一周年纪念日。在成员第二周年纪念日,如果会员资格至少在成员第二周年之前未取消会员资格,则适用的
![arxiv:2409.17759v1 [eess.iv] 26 Sep 2024](/simg/2\2a76c65d7eeb83c3905c9889ad37609048111e07.webp)
arxiv:2409.17759v1 [eess.iv] 26 Sep 2024
在同一场景中捕获不同的强度和光线的方向,光场(LF)可以将3D场景提示编码为4D LF映像,该图像具有广泛的范围(即,捕获后的重新集中和深度感测)。LF图像超分辨率(SR)旨在通过LF相机传感器的性能来改善图像分辨率。尽管现有方法取得了令人鼓舞的结果,但这些模型的实际应用是有限的,因为它们不够轻巧。在本文中,我们提出了一个名为LGFN的轻量级模型,该模型集成了不同视图的Lo local和全局特征以及LF Image SR的不同频道的特征。具体而言,由于不同的子孔径图像中相同像素位置的相邻区域表现出相似的结构关系,因此我们设计了一个基于CNN的轻质CNN特征表演模块(即DGCE),以更好地通过特征调节提取局部特征。同时,随着LF图像中边界之外的位置呈现出很大的差异,我们提出了一个有效的空间注意模式(即ESAM)(即ESAM),使用可分解的大内核卷积来获得扩大的接受场,并获得了一个扩大的接收场和效率的通道注意模块(即,Ecam)。与具有较大术语的现有LF图像SR模型相比,我们的模型的参数为0.45m,拖失术为19.33G,这已经达到了竞争效果。进行消融研究的实验实验证明了我们提出的方法的效率,该方法对NTIRE2024光场超级分辨率挑战的赛道2忠诚度和效率排名,这是赛道1 Fidelity的第七名。

引用方式:Rovani BT、Rissi VB、Rovani MT、Gasperin BG、Baumhardt T、Bordignon V、Bauermann LF、Missio D、Gonçalves PBD。核成熟分析
放射治疗会破坏肿瘤细胞,但也会威胁到周围正常细胞的完整性和存活率。因此,接受放射治疗的妇女可能会出现永久性卵巢损伤,导致生育能力受损。本研究的目的是调查用于治疗人类卵巢癌的治疗剂量电离辐射 (IR) 对作为实验模型的牛卵丘-卵母细胞复合体 (COC) 的影响。牛卵巢分别暴露于 0.9 Gy、1.8 Gy、3.6 Gy 或 18.6 Gy IR,然后收集 COC 并用于评估:(a) 卵母细胞核成熟;(b) 磷酸化 H2A.X (γH2AX) 的存在,作为 DNA 双链断裂 (DSB) 的指标;以及 (c) 参与 DNA 修复 ( TP53BP1、RAD52、ATM、XRCC6 和 XRCC5 ) 和细胞凋亡 ( BAX ) 的基因表达。本研究中测试的辐射剂量对核成熟没有不利影响,也没有增加卵母细胞中的 γH2AX。然而,IR 处理改变了 RAD52 (RAD52 同源物,DNA 修复蛋白) 和 BAX (BCL2 相关 X 蛋白) 的 mRNA 丰度。我们得出结论,虽然 IR 剂量对卵母细胞核成熟和 DNA 损伤没有明显影响,但参与 DNA 修复和细胞凋亡的分子通路受到卵丘细胞中 IR 暴露的影响。

产品列表 - 疫苗 - 国际
白喉类毒素 25 Lf (≥ 30 IU) S ...................................................................................... 破伤风类毒素 5.5 Lf (≥ 60 IU) S .............................................................................................. B. 百日咳 16 IOU (≥ 4.0 IU) S ................................................................................................ 吸附于磷酸铝上 AIPO ≥ 1.5 mg 4 S ............................................. 防腐剂:硫柳汞 0.01 % w/v S ................................................................................

基于放射组学的脑转移瘤患者术后立体定向放射治疗局部控制率预测
摘要背景。手术切除是治疗大型或有症状的脑转移瘤 (BM) 患者的标准方法。尽管辅助立体定向放射治疗后局部控制得到改善,但局部失败 (LF) 的风险仍然存在。因此,我们旨在开发并外部验证一种基于治疗前放射组学的预测工具,以识别高 LF 风险的患者。方法。数据来自 BM 切除腔立体定向放射治疗多中心分析 (AURORA) 回顾性研究(训练队列:来自 2 个中心的 253 名患者;外部测试队列:来自 5 个中心的 99 名患者)。从增强 BM(T1-CE MRI 序列)和周围水肿(T2-FLAIR 序列)中提取放射组学特征。比较了不同的放射组学和临床特征组合。最终模型在整个训练队列上进行训练,使用先前通过内部 5 倍交叉验证确定的最佳参数集,并在外部测试集上进行测试。结果。使用放射学和临床特征组合训练的弹性网络回归模型在外部测试中表现最佳,一致性指数 (CI) 为 0.77,优于任何临床模型(最佳 CI:0.70)。该模型在 Kaplan-Meier 分析中有效地根据 LF 风险对患者进行分层(P < .001),并显示出增量的净临床效益。在 24 个月时,我们发现低风险组和高风险组分别有 9% 和 74% 出现 LF。结论。临床和放射学特征的组合比单独的任何临床特征集更能预测无 LF。LF 高风险患者可能会受益于更严格的随访程序或强化治疗。

多年代际和湍流变化之间的能量转移
摘要:解释北大西洋海面温度数十年变化的建议机制之一是,由于时间平均环流的大规模斜压不稳定性,自发形成了一种大规模低频内部模式。尽管这种模式已在浮力方差预算方面得到广泛研究,但其能量特性仍然知之甚少。在这里,我们执行了这种内部模式的完整机械能预算,包括可用势能 (APE) 和动能 (KE),并将预算分解为三个频带:平均、与大规模模式相关的低频 (LF) 和与中尺度涡旋湍流相关的高频 (HF)。这种分解使我们能够诊断不同储存器之间的能量通量并了解源和汇。由于该模式的规模很大,它的大部分能量都包含在 APE 中。在我们的配置中,LF APE 的唯一来源是从平均 APE 到 LF APE 的转移,这归因于大规模斜压不稳定性。反过来,LF APE 的汇点是参数化的扩散、流向 HF APE 的通量,以及在较小程度上流向 LF KE 的通量。额外风应力分量的存在削弱了多年代振荡并改变了不同能量库之间的能量通量。在所有实验中,与其他涉及 APE 的能量源相比,KE 转移似乎对多年代模式的影响很小。这些结果突出了完整 APE – KE 预算的实用性。
