XiaoMi-AI文件搜索系统
World File Search Systemnetworks

绿色未来网络 - 可持续网络计量
过去几年,承诺在 2050 年或之前实现净零排放目标的移动网络运营商 (MNO) 数量显著增加。降低功耗是 MNO 实现这些目标并降低运营费用的关键。为了优化能源消耗,MNO 必须详细了解能源消耗的地点和时间,以及哪些因素影响了这种消耗。因此,准确的计量系统是确保正确监测、测量和优化能源消耗的先决条件。它将允许所有参与移动网络部署和运营的参与者(即 MNO 和塔台公司)开发精确的优化流程、预测维护并远程控制网络,从而减少人工干预。简而言之,应该在 MNO 和网络设备供应商(包括制造商和供应商)之间建立一个接口。该接口应包括有价值的功能和机制,以便将测量数据安全地传输到 MNO 站点,使他们能够分析数据并得出可负担的改进措施或解决方案,这些措施或解决方案可以由 MNO 自己实施或与制造商和/或供应商合作实施。虽然本白皮书主要关注基站 (BS) 站点,该站点被认为是移动网络中耗能最多的部分,但其见解和建议也适用于移动网络的其余部分,包括回程、核心和网络功能虚拟化 (NFV)。本白皮书中以通用方式使用术语“计量”,不仅指传感,还指收集、传输和使用所获得信息以更好地管理和改进网络所需的基础设施。这包括一种方法,即如何使用不同的通信通道、协议和接口将信息从测量站点传输到中心点,以便能够执行操作或分发有关网络状态的信息。有了这些信息,就可以规划网络的发展,以降低能耗并提高网络效率。本白皮书介绍了移动网络不同部分计量的目的,以及借助智能设施、可再生能源使用和管理、新运营模式、分解和虚拟化网络等多种用例可以实现的优势。对计量要求进行了分析,考虑了需要监控的方面,包括能源消耗、环境因素、站点安全等,以及如何在 BS、站点设施、核心网络和虚拟环境中实施计量。要节省能源,最重要的测量量是能耗、电流、和电压。应使每个 BS 设备以及技术站点设备(BS 站点)都能够通过计量来测量这些参数。由于不同能耗规模的各种设备在 BS 站点内交互工作,因此应确定和协调功率计的精度等级。因此,建议遵循既定的国际标准来制定测量原则以及测量精度。


计算机网络
随着终端用户和服务提供商对网络连接的需求不断增加,网络也变得高度复杂;其生命周期管理也变得如此。自动化、数据分析、人工智能、分布式账本技术(例如区块链)和数据平面编程技术的最新进展激发了研究人员社区探索和利用这些技术实现可信自动驾驶网络(SelfDN)这一迫切愿景的希望。本着这一思路,本文提出了一个新颖的框架,以支持跨多个域的完全分布式可信 SelfDN。该框架愿景通过以下方式实现:(i)利用可编程数据平面的功能实现实时网络内遥测收集;(ii)利用 P4(作为数据平面编程语言的重要示例)和 AI 的潜力(重写)网络组件的源代码,使网络能够自动将策略意图转换为可在网络组件上执行的可执行操作;以及(iii)利用区块链和联邦学习的潜力实现域间去中心化、安全和可信的知识共享。介绍并讨论了相关用例,以证明预期愿景的可行性。获得并讨论了令人鼓舞的结果。


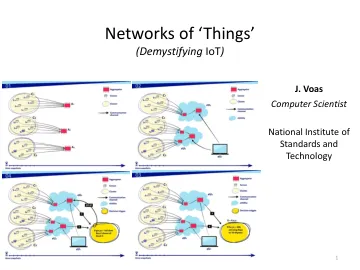
“物联网”网络
“我们必须首先定义‘事物’的含义。它可以是非常简单的对象,也可以是复杂的对象。事物不需要直接连接到公共互联网,但它们必须通过网络(可以是 LAN、PAN、体域网等)连接。物联网是包含嵌入式技术以与外部环境进行通信和交互的物理对象的网络。物联网包括硬件(“事物”本身)、嵌入式软件(运行在事物上并启用事物连接功能的软件)、连接/通信服务以及与事物相关的信息服务(包括基于使用模式和传感器或执行器数据分析的服务)。物联网解决方案是产品(或产品集)与服务的组合,两者的关系可以是一对一或一对多。这意味着一项服务与一个(一组)产品相结合,或者一项服务与多个(组)产品相结合。”“物联网在能源效率中的应用”,Francois Jammes。 Ubiquity:ACM 出版物,2016 年 2 月,第 2 页

神经网络
神经网络与逻辑回归具有相同的数学相同。但是,神经网络比逻辑回归更强大,而且确实可以证明一个最小的神经网络(从技术上讲,一个具有单个“隐藏层”)可以显示任何功能。神经网络分类器与逻辑回归不同。通过逻辑回归,我们通过基于域知识开发许多丰富类型的特征模板,将回归分类器应用于许多不同的任务。在使用神经网络时,更常见的是避免大多数使用丰富的手派生功能,而是构建以原始单词为输入的神经网络,并学会诱导功能作为学习分类的过程的一部分。我们在第6章中看到了嵌入的这种表示的示例。非常深的网属于代表学习。因此,深神经网是提供足够数据以自动学习功能的任务的正确工具。在本章中,我们将作为分类器介绍FeedForward网络,并将它们介绍为语言建模的简单任务:将概率分配给单词序列并预测即将到来的单词。在随后的章节中,我们将介绍神经模型的许多其他方面,例如复发性神经网络(第8章),变压器(第9章)和蒙版语言建模(第11章)。


神经网络
基于多模态神经生理时间序列(多导睡眠图 PSG)的计算睡眠评分已在临床上取得了令人瞩目的成功。仅使用 PSG 中单个脑电图 (EEG) 通道的模型尚未获得同样的临床认可,因为它们缺乏快速眼动 (REM) 评分质量。这一缺陷是否可以完全弥补仍然是一个重要问题。我们推测,主要的长短期记忆 (LSTM) 模型不能充分表示远处的 REM EEG 段(称为时期),因为 LSTM 将这些段压缩为来自独立过去和未来序列的固定大小向量。为此,我们引入了 EEG 表示模型 ENGELBERT(electro En cephalo G raphic E poch L ocal B idirectional Encoder R epresentations from T Transformer)。它联合关注过去和未来的多个 EEG 时期。与语言中的典型标记序列(注意力模型最初就是为其设计的)相比,夜间脑电图序列很容易跨越 1000 多个 30 秒的时期。重叠窗口上的局部注意力将关键的二次计算复杂度降低到线性,从而实现了从一小时以下到全天的灵活评分。ENGELBERT 至少比现有的 LSTM 模型小一个数量级,并且易于在一个阶段从头开始训练。它在 3 个单脑电图睡眠评分实验中超越了最先进的宏 F1 分数。REM F1 分数被推高到至少 86%。ENGELBERT 实际上将与基于 PSG 的方法的差距从 4-5 个百分点 (pp) 缩小到不到 1 pp F1 分数。© 2022 作者。由 Elsevier Ltd. 出版。这是一篇根据 CC BY 许可开放获取的文章(http://creativecommons.org/licenses/by/4.0/)。