XiaoMi-AI文件搜索系统
World File Search Systemnorm
没有新的化石燃料项目:我们需要的规范
全球生产和化石燃料的使用继续扩大,使巴黎协定的目标变得更加困难。与气候倡导者多年来作出的呼吁,这是2023年末联合国气候会议的开创性决定(COP28)对当事方的呼吁,“为……从能源系统中的福斯燃料过渡为……贡献……在能源系统中过渡”。最终淘汰化石燃料的规范案例很强,在某些情况下,在经济寿命结束之前逐步逐步项目是可行的。但是,该运动应集中在更可行的,但至关重要的一步,沿着化石燃料播出的道路:停止化石燃料的扩展。雄心勃勃的气候行动的支持者应指导政策和倡导努力,以建立全球“无新化石”规范,

根据弱规范
在1960年代[17,34,41]定居,而端点案例L∞TL 3 X仅在很多年后由Acsepauriaza,Seregin和šverák定居[12]。终点案例的主要困难与以下事实有关:L 3是3D Navier-Stokes的关键空间,[12]使用爆破程序和新的独特的延续结果通过矛盾来解决它。此结果意味着,如果t 0> 0是(1)的推定爆炸时间,那么∥u(t)∥3必须至少沿着time t k→t-0的序列吹来。Seregin [38]表明L 3 Norm必须按照任何时间汇聚到T-0的时间爆炸,但根据L 3 Norm的定量控制u的定量控制问题一直保持开放,直到Tao最近的突破性作品[44]
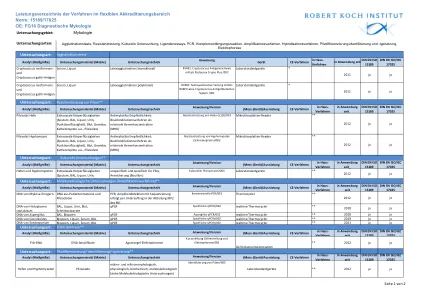
灵活认证领域服务列表 标准:15189 和 17025 OE:FG16
曲霉菌 BAL 活检 DNA qPCR 曲霉菌 qPCR/002 实时热循环仪 ** 2018 是 是 球孢子菌活检 DNA、脑脊液、血清、BAL qPCR 特定 qPCRs/002 实时热循环仪 ** 2019 是 是 赛多孢子菌活检 DNA、脑脊液、血清、BAL qPCR 特定 qPCRs/002 实时热循环仪 ** 2021 是 是 检查类型:

使用多图正则化核范数最小化预测药物-靶标相互作用
在制药科学中,识别药物和靶标蛋白之间的潜在相互作用至关重要。在基因组药物发现中,相互作用的实验验证费力且昂贵;因此,需要高效、准确的计算机模拟技术来预测潜在的药物-靶标相互作用,以缩小实验验证的搜索空间。在这项工作中,我们提出了一个新框架,即多图正则化核范数最小化,它从三个输入预测药物和靶标蛋白之间的相互作用:已知的药物-靶标相互作用网络、药物之间的相似性以及靶标之间的相似性。所提出的方法侧重于寻找一个低秩相互作用矩阵,该矩阵由图编码的药物和靶标的接近度构成。先前关于药物靶标相互作用 (DTI) 预测的研究表明,结合药物和靶标的相似性有助于通过保留原始数据的局部几何形状更好地学习数据流形。但是,对于哪种相似性以及哪种组合最能帮助完成预测任务,目前还没有明确的共识。因此,我们建议使用各种药物间相似性和靶标间相似性作为多图拉普拉斯(药物/靶标)正则化项,以详尽地捕获近似值。使用标准评估指标(AUPR 和 AUC)对四个基准数据集进行的大量交叉验证实验表明,所提出的算法提高了预测性能,并且大大优于最近最先进的计算方法。软件可在 https://github.com/aanchalMongia/ MGRNNMforDTI 上公开获取。
FSU新闻佛罗里达州议员承认罕见疾病日,敦促其他人“挑战规范”
为确保患有罕见疾病的人获得所需的治疗,安德森说,过去的努力包括罕见的疾病咨询委员会,该委员会是由佛罗里达州立法机关在2021年成立的,以建议佛罗里达卫生部如何改善患有罕见疾病的佛罗里达人的健康状况。

代理人的人际交往态度对虚拟现实情景中的服从和社会规范遵守的影响
图3:静止的图像来自陈述中所示的视频。(a)显示了女性友好的主导条件(b)显示男性友好的顺从状况(c)显示男性敌对的占主导地位(d)显示女性敌对的服从条件(E)显示女性中性言语状况(F)显示了男性中性的非言语状况(G)显示了男性对照条件。所有行为后来在主要研究中使用,除了(e)女性中性言语

类别间交通流量碳标签的影响以及存在社会规范提示对食品购买的影响
1 LPS, Aix-Marseille University, Aix-en-Provence, France 2 Psychic, Aix-Marseille University, Aix-en-Provence, France 3 University of Toulouse, Toulouse, France 4 University Grenoble Alpes, Inrae, CNRS, Grenoble INP, Gael, Grenoble, France Correspondence: Johann Suchier, LPS, Aix-Marseille University法国Aix-en-Provence。电子邮件:jsuchier@gmail.com资金信息:国家研究机构,授予/奖励号:ANR-2016-CE05- 0018

基于迭代加权范数的机载扫描雷达超分辨成像快速总变分方法
摘要:全变分(TV)方法已被用于实现机载扫描雷达在保持目标轮廓的超分辨成像。迭代重加权范数(IRN)方法是一种通过求解一系列最小加权L2范数问题来处理最小Lp范数问题的算法,已被用于求解TV范数。然而,在求解过程中,IRN方法每次迭代都需要更新权重项和结果项,涉及大矩阵的乘法和求逆,计算量巨大,严重制约了TV成像方法的应用。本文通过分析迭代过程中涉及矩阵的结构特点,提出了一种基于适当矩阵分块的高效方法,将大矩阵的乘法和求逆转化为多个小矩阵的计算,从而加速算法。所提方法称为IRN-FTV方法,比IRN-TV方法更节省时间,尤其适用于高维观测场景。数值结果表明,所提出的IRN-FTV方法具有较好的计算效率,且性能没有下降。

通过角色的选择和价值 - 信念 - 态度推理使大型语言模型与人类的意见结盟
用大语言模型(LLM)推理和预测人类意见是必不可少的但具有挑战性的。当前的方法采用角色扮演的角色,但面对两个主要措施:LLMS甚至对一个无关的角色也很敏感,最多可以改变预期的30%; LLM无法战略性地推理人类。我们提出了开场链(COO 1),这是一种简单的四步解决方案建模,如何用personae推理,由价值 - 宽容 - 态度(VBN)the-Ory进行推理。COO将明确的人(人口统计学和意识形态)和卑鄙的人物(历史观点)区分了:(1)将无关的属性与显式人物过滤; (2)将隐式人物排名为选择top-k的优先列表; (3)提出新颖的VBN推理,以提取用户的环境和个人价值,信念和规范变量,以进行准确可靠的预测; (4)迭代VBN推理,并逐渐更大的隐式角色列表来处理潜在的角色不足。COO通过仅提示5个推论呼叫来有效地实现新的最新观点预测,从而将先前的技术提高了多达4%。值得注意的是,通过COO的数据进行微调LMS导致观点一致的模型明显高达23%。

天然存在的放射性材料(规范)北塞浦路斯尼科西亚气溶胶粉尘的浓度和健康风险评估
颗粒,从而照射宿主有机体[2]。天然放射性核素在灰尘中的主张取决于其在原始土壤中的数量。此外,灰尘的起源主要与大气灰尘,农业活动,该地区的植物类型,土壤特征和环境污染有关。从辐射保护的角度来看,相关的放射学风险很重要,最近报告了一些研究[3-6]。自然存在的放射性材料(规范),例如40 K和238 U,232 TH及其腐烂产物,它们存在于土壤[7,8],岩石[5,9],水[10-12]和建筑材料[13-17]等环境材料中,可能对人类健康有害。基于土壤的地质形成,土壤中放射性的分布取决于其得出的岩石类型以及其地质位置的性质[18]。土壤不仅充当人类连续辐射暴露的来源,而且还充当以灰尘形式将放射性物质运输到呼吸系统中的一种手段[19]。许多因素影响不同地理环境组件(例如土壤,沉积物,水,尘埃)中规范的分布,包括风化过程,局部地质和气候条件[20]。如果不考虑气态ra吸入,则沉积物或土壤中规范的存在通常与外部辐射暴露有关。自从水中暴露于标准涉及多种途径,由于低水平