XiaoMi-AI文件搜索系统
World File Search Systemnx

多联机空调 - 大金
1969 年,大金在日本开发了第一台多分体空调系统。自这一里程碑诞生以来的 45 多年里,我们凭借产品的质量、可靠性和先进技术建立了国际声誉。Super Multi NX 仅需一台室外机即可在最多五个房间内保持最佳舒适度。多分体系统提供的诸多优势通过 NX 系列的高效直流逆变器技术得到了增强。

数据中心照明技术概述
所有 NX 无线传感器均配备我们专有的 IntelliSCOPE™ 功能,只需单击按钮即可实现真正的无梯编程和安装。IntelliSCOPE™ 提供实时占用数据,帮助优化任何应用中的传感器检测,从而节省时间和金钱。带有站点管理器的 NX 区域控制器为建筑业主和设施经理提供多建筑照明控制、照明系统洞察以及与建筑管理系统 (BMS) 控制操作顺序的集成。

安装要求和产品规格
型号 STERRAD ® NX ® 系统是一种先进的过氧化氢气体等离子系统,可实现快速终端灭菌,标准循环时间为 28 分钟,高级循环时间为 38 分钟。*该系统可对各种器械进行灭菌,包括单通道柔性内窥镜、半硬性输尿管镜、电钻、电池、照相机、灯线、硬性内窥镜、一般手术器械等。该系统可灵活地在需要时准备好干燥、包装好的无菌器械。STERRAD ® NX ® 系统提供多种独特功能,包括网络连接、诊断程序和易于阅读的触摸屏。其紧凑的尺寸和简单的插件使其非常适合放置在各种位置,例如手术室亚无菌室、手术室外科核心、门诊手术中心、无菌处理部门和专科部门(例如泌尿科)。只有 STERRAD ® NX ® 系统可以提供所有这些功能,使医疗机构能够处理更多的病例,而不会出现延误,从而确保手术室按时进行。

引用:Ashish Pandey。 “ AI驱动的机器人牙科:微创程序的未来”。ACTA科学临床病例报告5.11(202
1在重复的无脂肪干样品(平均值±SD)中确定为蛋白质百分比(NX 6.25)。行中具有相同上标的平均值没有显着差异(p <0.05)。

NanoXplore Days FPG-AI 11_06_2024v2.pdf
Ø “确保该工具支持所有最先进的设备,尤其是 NanoXplore (NX) FPGA,使这些设备能够用于 AI 应用并追求欧洲主权”

通过超声波输送进行生物墨水气溶胶喷射打印
作者 NX Williams · 被引用 42 次 — 这项工作得到了国防部的支持。国防部国会指导的医学研究。计划 (CDMRP),奖励编号为 W81XWH-。17-2-0045 和...
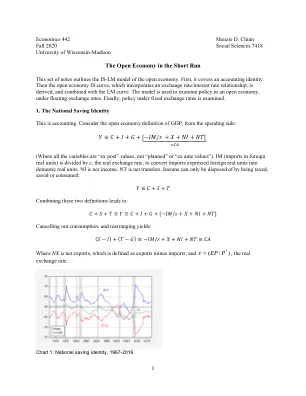
1短期中的开放经济
让NET出口重新编写:εεεεε /),(),(),( * * * y im y x y y y y nx- nx - =替换为等式(19.1),使用函数形式,用于对14章的汇总需求的家庭组成部分的函数形式,从第14章中获得了开放经济的收益率: 𝑁𝑋(𝑌,𝑌∗,𝜀)(19.1)如果假设在国内外价格是恒定的,而1 / * = p p,则E =ε此外,以恒定的价格水平,通货膨胀为零,实际利率等于名义。因此,等式(19.1)变为:),(),()( * e y y y nx g i y i t y c y c y + + + + + + + - =(19.2)(我保持通货膨胀的恒定,所以I和H的问题与IS曲线的表述有关,即汇率的任何变化可能会使E曲线变化; Ever e curve the Curve e e e evirap e e e eviept e evie e rusport e div funcort of foruct e div funcort

人工智能无线电收发器 (AIR-T)
AIR7311 将 NVIDIA Jetson Orin NX 16GB 片上系统与 NVIDIA Ampere GPU 架构的计算能力相结合,以支持最新的深度学习方法,包括边缘生成 AI。

太空探索技术公司 (SpaceX) 案例研究
最初,SpaceX 的设计人员尝试使用中档计算机辅助设计 (CAD) 程序来开发猎鹰 1 号。经过大约一年的挫折,组件加载时间超过一小时(或者更糟的是,创建后无法打开),该公司开始寻找更强大的软件。SpaceX 开发运营副总裁 Chris Thompson 知道,除了需要功能更强大的设计软件外,该公司还需要一个解决方案来管理猎鹰 1 号项目中不断增加的设计数据、规格、CNC 程序、流程等。尽管 Thompson 和他的同事分别评估了 CAD、有限元分析 (FEA) 和产品数据管理 (PDM) 解决方案,但他们最终选择了 Siemens PLM Software 的所有技术来创建托管开发环境。产品生命周期管理 (PLM) 解决方案包括 NX™ 软件(包括 NX

超越峰值性能:比较 AI 优化 FPGA 和 GPU 的实际性能
1 英特尔公司可编程解决方案事业部 2 多伦多大学和矢量研究所 3 卡内基梅隆大学 { andrew.boutros, eriko.nurvitadhi } @intel.com 摘要 — 人工智能 (AI) 的重要性和计算需求日益增长,导致了领域优化硬件平台的出现。例如,Nvidia GPU 引入了专门用于矩阵运算的张量核心,以加速深度学习 (DL) 计算,从而使 T4 GPU 的峰值吞吐量高达 130 int8 TOPS。最近,英特尔推出了其首款针对 AI 优化的 14nm FPGA Stratix 10 NX,其内置 AI 张量模块可提供高达 143 int8 TOPS 的估计峰值性能,堪比 12nm GPU。然而,实践中重要的不是峰值性能,而是目标工作负载上实际可实现的性能。这主要取决于张量单元的利用率,以及向/从加速器发送数据的系统级开销。本文首次对英特尔的 AI 优化 FPGA Stratix 10 NX 进行了性能评估,并与最新的 AI 优化 GPU Nvidia T4 和 V100 进行了比较,这些 GPU 都运行了大量的实时 DL 推理工作负载。我们增强了 Brainwave NPU 覆盖架构的重新实现,以利用 FPGA 的 AI 张量块,并开发了工具链支持,使用户能够仅通过软件对张量块进行编程,而无需在循环中使用 FPGA EDA 工具。我们首先将 Stratix 10 NX NPU 与没有张量块的 Stratix 10 GX/MX 版本进行比较,然后对 T4 和 V100 GPU 进行了详细的核心计算和系统级性能比较。我们表明,我们在 Stratix 10 NX 上增强的 NPU 实现了比 GPU 更好的张量块利用率,在批处理 6 时,与 T4 和 V100 GPU 相比,平均计算速度分别提高了 24 倍和 12 倍。即使在允许批处理大小为 32 的宽松延迟约束下,我们仍分别实现了与 T4 和 V100 GPU 相比 5 倍和 2 倍的平均速度提升。在系统级别,FPGA 的细粒度灵活性及其集成的 100 Gbps 以太网允许以比通过 128 Gbps PCIe 本地访问 V100 GPU 少 10 倍和 2 倍的系统开销延迟进行远程访问,分别用于短序列和长序列 RNN。索引术语 — FPGA、GPU、深度学习、神经网络