XiaoMi-AI文件搜索系统
World File Search Systemocr

成人精神分裂症大脑中的神经元染色质景观与早期胎儿发育有关
图1:人脑中的种群尺度染色质可及性分析。a)从469个独特的供体中获得脑组织标本,其中包括精神分裂症(SCZ)(n = 157),BD(n = 77)和对照组(n = 235)。风扇分离出神经元和非神经元核,并进行了ATAC-SEQ分析以产生总共1,393个文库。b)Venn图显示了已识别OCR的细胞类型(左)和脑区域(右)(右)特异性。c)顶部:示意图显示增强器启动器链接。灰色盒子,浅灰色盒子和黑色箭头分别代表OCR,TSS和基因体。底部:饼图中的分布显示了注释到神经元(红色的阴影)和非神经元(蓝色)OCR的19,749个基因的分层。神经元中的精神分裂症OCR富含精神分裂症风险变体,我们接下来研究了与精神分裂症和BD相关的染色质可及性模式的变化

IX 条款/性行为不当行为协调员
3 第九条并不涉及课程,也不以任何方式禁止或限制使用特定的教科书或课程材料。见28 CFR § 54.455;34 CFR § 106.42。此外,OCR 的 2001 年指导指出,“第九条旨在保护学生免受性别歧视,而不是规范言论内容……某些学生认为某种表达具有冒犯性,单凭这一点,在法律上不足以根据第九条建立性敌意环境。”教育部民权办公室,修订的性骚扰指导(2001 年),第 22 页。另见 OCR 亲爱的同事关于第一修正案的信,2003 年 7 月 28 日(解释“OCR 的规定不应被解释为导致在公立或私人校园压制受保护的言论。”)。
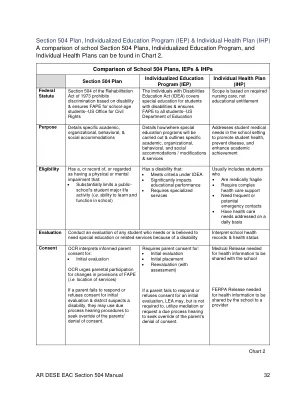
学校 504 计划、IEP 和 IHP 的比较
解释学校健康记录和健康状况同意 OCR 解释知情父母同意的内容:• 初步评估 OCR 敦促父母参与改变 FAPE 的规定(即服务地点)如果父母未能回应或拒绝同意初步评估并且学区怀疑有残疾,他们可以使用正当程序听证程序来寻求推翻父母的拒绝同意。

阅读障碍的光学特征识别
阅读障碍是一种学习障碍,会影响阅读,写作和咒语的能力。患有阅读障碍的人可能难以清晰,流利和理解。已经证明,使用光学特征识别(OCR)技术使阅读障碍的人更容易阅读。在这项工作中,我们描述了一种Android软件,该软件可帮助患有阅读障碍的人通过使用OCR技术更加流利地阅读。该程序使用相机收集文本图像,然后使用OCR算法将其转换为数字格式。然后,数字文本以文本到语音功能以及可自定义的字体样式和颜色显示在屏幕上。通过用户测试,确定了应用程序的有效性,结果表明它可以帮助阅读障碍者更快,准确地阅读。通过给他们一种促进更轻松,更深入阅读的工具,本研究中描述的Android软件有可能极大地提高阅读障碍患者的生活质量

福利和承保范围摘要:该计划涵盖了什么以及您支付的承保服务覆盖范围:01/01/2025–12/31/2025 Anthem Blue Cross
这就是为什么我们在健康计划和活动中遵循联邦民权法的原因。我们不会根据种族,颜色,国籍,性别,年龄或残疾来歧视,排除人或对待他们。对于残疾人,我们提供免费的艾滋病和服务。对于主要语言不是英语的人,我们通过口译员和其他书面语言提供免费的语言援助服务。对这些服务感兴趣?在您的身份证上致电成员服务号码以寻求帮助(TTY/TDD:711)。如果您认为我们无法根据种族,颜色,国籍,年龄,残疾或性别提供这些服务或歧视,则可以提出投诉,也称为申诉。您可以书面形式向我们的合规协调员提出投诉。框27401,邮件DROP VA2002-N160,里士满,弗吉尼亚州23279。,您可以向美国卫生与公共服务部,西南独立大道200号公民权利办公室提出投诉; HHH建筑物509F房间;华盛顿特区20201或致电1-800-368-1019(TDD:1- 800-537-7697)或在线https://ocrportal.hhs.gov/ocr/portal/portal/lobby.jsf。 投诉表格可在http://www.hhs.gov/ocr/office/file/index.html上找到。,您可以向美国卫生与公共服务部,西南独立大道200号公民权利办公室提出投诉; HHH建筑物509F房间;华盛顿特区20201或致电1-800-368-1019(TDD:1- 800-537-7697)或在线https://ocrportal.hhs.gov/ocr/portal/portal/lobby.jsf。投诉表格可在http://www.hhs.gov/ocr/office/file/index.html上找到。

ODM:文本图像进一步的对齐预训练方法,用于场景文本检测和发现
近年来,文本图像联合预训练技术在各种任务中显示出令人鼓舞的结果。然而,在光学特征识别(OCR)任务中,将文本实例与图像中的相应文本区域对齐是一个挑战,因为它需要在文本和OCR文本之间有效地对齐(将图像中的文本称为ocr-文本以与自然语言中的文本区分开来),而不是对整体图像内容的全面理解。在本文中,我们提出了一种新的预训练方法,称为o cr-text d估计化m odeling(ODM),该方法根据文本提示将图像中的文本样式传输到统一样式中。使用ODM,我们在文本和OCR文本之间实现了更好的对齐方式,并启用预训练的模型以适应场景文本的复杂和多样化的样式。此外,我们为ODM设计了一种新的标签生成方法,并将其与我们提出的文本控制器模块相结合,以应对OCR任务中注释成本的挑战,并以大量未标记的数据参与预培训。在多个Pub-LIC数据集上进行的广泛实验表明,我们的方法显着地证明了性能,并且在场景文本检测和发现任务中的当前预训练方法优于当前的预训练方法。代码在ODM上可用。
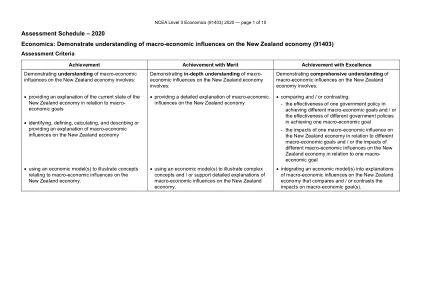
NCEA 3级经济学(91403)2020
降低OCR可能有效地减少失业率,例如,利率下降将增加消费和投资以及净出口,因为公司和消费者的借贷成本已下降。由于AD的三个组成部分直接受到OCR削减的影响,因此AD的增加将大于弱化全球活动引起的AD的减少,这可能只会导致AD的一个成分显着下降,即X – M。因此,实际GDP总体上将有所增加,失业率显着下降。其他响应可能。

一种检测和识别图片中文本的混合方法
为了创建能够自动从图像或图片中读取文本的计算机系统,研究人员专注于检测和识别图像中的文本。这个问题特别困难,因为图像通常具有复杂的背景和广泛的属性,包括颜色、大小、形状、方向和纹理。我们提出的方法基于形态学,它由膨胀和腐蚀过程组成,以提取文本并识别包含文档文本或图像的黑白文本区域。这种建议的方法已被研究,因为它能够自动识别与文本图片对齐的文本,例如商店名称、街道名称、横幅和海报。本文使用光学字符识别 (OCR) Tesseract 标准和优化的 OCR Tesseract 介绍了该设备实验的设计、应用和结果。我们的结果表明,优化的 OCR Tesseract 比标准性能好得多。图像预处理和文本处理模块构成了该设备的两个模块。该设备使用 Arduino Uno 和 drawbot/flutter 进行文本打印,是使用 Raspberry Pi 和 1.2GHz 处理器创建的。

品牌:安捷伦模型:Seahorse XFE24 Analyzer位置
•与粘附和悬浮细胞以及分离的线粒体和非哺乳动物样品的兼容性。•自动混合使用每孔最多可执行4次独立注射•自动计算氧气消耗率(OCR)和细胞外酸化速率(ECAR)。•同时测量OCR和ECAR在相同的井中•对小样本量的敏感性•实时无标签检测•与Windows兼容的桌面分析软件(WAVE)和基于Web的数据分析软件(Agilent Seahorse Analytics)用于绘制,报告,报告,分析和导出XF数据。
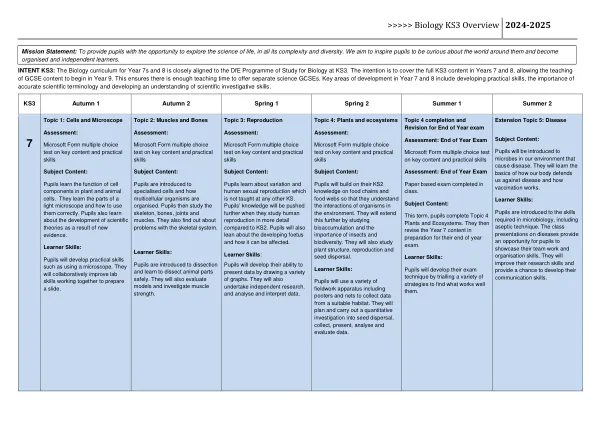
生物学KS3概述2024-2025 -Cranbrook School
在KS5学生研究OCR生物学A规范。 课程内容按我们在课堂上使用的OCR A级教科书的顺序。 这引入了细胞的生物学,移动到组织,器官,最后移至生态系统和栖息地。 这是一个逻辑上的顺序,始于基础话题,然后基于内容,因此到13年,学生将他们的理解应用于更具挑战性的概念。 教科书中的主题与班级主题手册匹配。 学生还为每个主题提供了一个考试练习问题手册,以练习他们的考试,写作和识字能力。 13年级课程在概念上比第12年课程更具挑战性。 考试问题的需求水平和数字问题的数学难度也有显着提高。在KS5学生研究OCR生物学A规范。课程内容按我们在课堂上使用的OCR A级教科书的顺序。这引入了细胞的生物学,移动到组织,器官,最后移至生态系统和栖息地。这是一个逻辑上的顺序,始于基础话题,然后基于内容,因此到13年,学生将他们的理解应用于更具挑战性的概念。教科书中的主题与班级主题手册匹配。学生还为每个主题提供了一个考试练习问题手册,以练习他们的考试,写作和识字能力。13年级课程在概念上比第12年课程更具挑战性。考试问题的需求水平和数字问题的数学难度也有显着提高。