XiaoMi-AI文件搜索系统
World File Search Systemonce
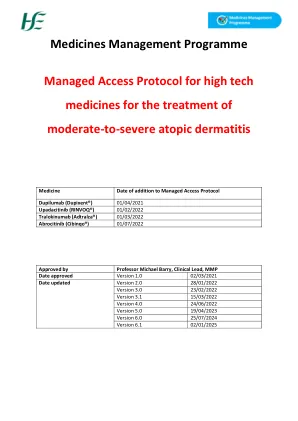
高科技药物的托管访问协议...
每天15毫克口服一次。 如果患者每天不能每天15 mg反应,则每天可以将剂量增加到30 mg。 基于个体患者的表现III kg:千克;毫克:毫克; SC:建议每天使用100毫克的开始剂量,建议患有静脉血栓栓塞(VTE),主要不良心血管事件(MACE)和恶性肿瘤的患者。 每天每天一次200毫克的剂量可能适用于没有疾病负担高的VTE,MACE和恶性肿瘤风险的患者。 在治疗期间,基于耐受性和功效,磨蚀剂的剂量可能会降低或增加。 应考虑维护的最低有效剂量。 酰胺替尼的最大每日剂量为200 mg。每天15毫克口服一次。如果患者每天不能每天15 mg反应,则每天可以将剂量增加到30 mg。基于个体患者的表现III kg:千克;毫克:毫克; SC:建议每天使用100毫克的开始剂量,建议患有静脉血栓栓塞(VTE),主要不良心血管事件(MACE)和恶性肿瘤的患者。每天每天一次200毫克的剂量可能适用于没有疾病负担高的VTE,MACE和恶性肿瘤风险的患者。在治疗期间,基于耐受性和功效,磨蚀剂的剂量可能会降低或增加。应考虑维护的最低有效剂量。酰胺替尼的最大每日剂量为200 mg。
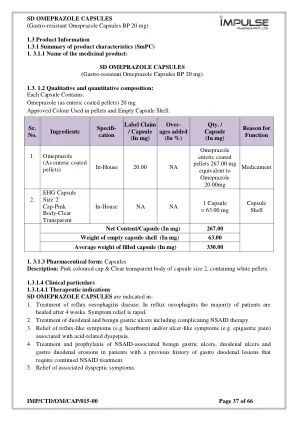
冲动
证明有效地消除了消化性溃疡疾病中幽门螺杆菌(HP)。7。预防酸抽吸。 8。 Zollinger-Ellison综合征。 1.3.1.4.2屈服和行政途径方法:口服食道反流疾病,包括反流性食管炎:通常的起始剂量为20 mg奥美拉唑每天服用一次,持续4周。 对于那些在最初的4周课程后未完全愈合的患者,通常会在另外4-8周的治疗中进行愈合。 奥美拉唑也每天一次使用40毫克的剂量,用于反流性食管炎的患者对其他疗法的难治性。 治愈通常在8周内发生。 可以以20 mg的剂量考虑治疗的延续。 胃酸反流疾病:对于长期管理,建议每天服用10 mg一次,如果症状恢复,则增加到20 mg。 十二指肠和良性胃溃疡:通常的剂量为20 mg奥美拉唑。 在十二指肠溃疡中,大多数患者通常在治疗4周后治愈。 大多数良性胃溃疡患者在8周后愈合。 在严重或经常性的情况下,每天剂量可能增加到40 mg奥美拉唑。 对于具有复发性十二指肠溃疡病史的患者,建议每天以20毫克奥美拉唑的剂量进行长期治疗。 为防止复发,在十二指肠溃疡患者中,建议的剂量为奥美拉唑10 mg,每天一次,增加到20毫克,每天一次,如果症状恢复。 症状缓解速度很快,大多数患者在4周内进行了愈合。预防酸抽吸。8。Zollinger-Ellison综合征。1.3.1.4.2屈服和行政途径方法:口服食道反流疾病,包括反流性食管炎:通常的起始剂量为20 mg奥美拉唑每天服用一次,持续4周。对于那些在最初的4周课程后未完全愈合的患者,通常会在另外4-8周的治疗中进行愈合。奥美拉唑也每天一次使用40毫克的剂量,用于反流性食管炎的患者对其他疗法的难治性。治愈通常在8周内发生。可以以20 mg的剂量考虑治疗的延续。胃酸反流疾病:对于长期管理,建议每天服用10 mg一次,如果症状恢复,则增加到20 mg。十二指肠和良性胃溃疡:通常的剂量为20 mg奥美拉唑。在十二指肠溃疡中,大多数患者通常在治疗4周后治愈。大多数良性胃溃疡患者在8周后愈合。在严重或经常性的情况下,每天剂量可能增加到40 mg奥美拉唑。对于具有复发性十二指肠溃疡病史的患者,建议每天以20毫克奥美拉唑的剂量进行长期治疗。为防止复发,在十二指肠溃疡患者中,建议的剂量为奥美拉唑10 mg,每天一次,增加到20毫克,每天一次,如果症状恢复。症状缓解速度很快,大多数患者在4周内进行了愈合。以下患者患有复发性溃疡复发的风险:幽门螺杆菌感染,年轻患者(<60岁),这些症状持续了一年以上。这些患者将需要每天使用20毫克奥美拉唑的初始长期治疗,如有必要,每天每天减少10毫克。与酸相关的消化不良:通常的剂量为10 mg或20 mg奥美拉唑,每天2-4周,具体取决于症状的严重程度和持久性。如果患者在4周后不对治疗反应或治疗后不久谁复发,则应研究患者。用于治疗与NSAID相关的胃溃疡,十二指肠溃疡或胃十二指肠腐蚀:建议的奥美拉唑的推荐剂量每天20毫克。对于那些可能在初始病程后可能无法完全治愈的患者,通常会在另外4周的治疗中进行愈合。用于NSAID相关的胃溃疡,十二指肠溃疡,胃十二指肠抑制剂和胃十二指肠病史患者的患者需要继续进行NSAID治疗的患者:推荐的剂量为20 mg Omeprazole。

OFFER LETTER COMPONENTS FORM
o Submit a detailed budget outlining how you will be spending the funds in support of your research/creative activity program within the first month of contract start date. o A statement of work outlining the research program the funds will be used on, including a timeline of expected research/creative activity output, to be submitted within the first month of contract start date. o Complete an annual report showing how your funding was utilized, to be submitted no later than 12 months post contract start date. For those disciplines that are supported through funds made through extramural grants, it is expected that a first grant application is produced together with and submitted after approval by the Office of Research Development within the first two years of employment. • Failure to meet research goals and/or submit an external grant or other significant research/creative activity output through the Office of Research in your second year of employment at the university or submission and approval of your annual report, will result in the termination of subsequent startup funds. Once a proposal or other discipline-specific research/creative activity output has been submitted externally, funds for summer salary will be made available. These policies apply whether you begin work at KSU in the fall or in the spring semester. • Startup funds must be spent in accordance with all KSU and University System of Georgia rules and regulations.

咯利普兰作为磷酸二酯酶-4 抑制剂如何影响大鼠急性异烟肼诱发的癫痫发作和戊四唑点燃
第III组“PTZ点燃模型组”(n=24),又细分为第IIIA组“未治疗模型组,健康大鼠腹腔注射30mg/kg PTZ,隔日1次,连用1个月,后隔日1次,连用1个月;第IIIB组“DZ点燃大鼠”,点燃大鼠腹腔注射10mg/kg DZ,隔日1次,连用1个月,后隔日1次,连用1个月,每次ip 30mg/kg PTZ后10分钟注射;第IIIC组“Rol治疗点燃大鼠”,点燃大鼠腹腔注射0.5mg/kg Rol,隔日1次,连用1个月,后隔日1次,连用1个月,每次ip 30mg/kg PTZ后10分钟注射“根据Giorgi等[30]改进”,每天注射PTZ,连用30天。
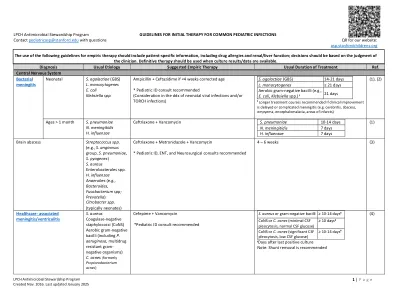
指导原始治疗 - 普通 - 佩蒂科 -
抑制性疗法:Valacyclovir 10 mg/kg(最大500 mg)PO BID *或Valacyclovir 20 mg/kg(最大1 g)PO每天一次或Acyclovir 20-25 mg/kg(最大400 mg)PO BID; *对于患有非常频繁复发(每年≥10次发作)的患者的有效性较低,淋病婴儿和儿童≤45kg≤45kg,肿瘤炎性炎,宫颈炎,宫颈炎,尿道炎,咽炎,咽炎或前炎或前炎:Ceftriaxone 50 mg/kg(Max 500 mg),曾经是45 mg),> 45淋球菌性外阴炎,宫颈炎,尿道炎,咽炎或脑炎:头孢曲松酮500毫克IM一次(如果≥150kg,1g),如果尚未排除并发的胰chmy虫感染,则添加100 mg bid bid x 7天(如果庆大霉素240毫克IM曾经 +阿奇霉素2 g PO曾经淋巴植物瘤

策略 9 - 增加大学参与度报告 2022。...
• 共发送了 2,509 份录取短信,其中 40.77% 报名了课程。 • 给成人学习者打了 2,390 个电话,其中 28.62% 报名了课程。 • 从 11 月 11 日(实施日期)到 3 月 9 日(2022 年春季申请截止日期),招生成人团队通过 Schedule Once 预约了 292 次,比前四个月增加了一倍多。 • 虽然无法用数字量化,但招生成人学习者团队报告与学生的互动要好得多,通过入学与其中许多学生保持联系。虽然目前还没有办法通过 Salesforce/Enrollment Rx 自动化这个过程,但我们正在探索在 CRM 中使用“任务提醒”,看看是否有办法进一步自动化成人学习者的参与过程。关于西区工作,西区 CWT(现已更名为“参与社区”)一直积极参与塑造西谷市/卡恩斯社区的招聘和规划工作。特别令人感兴趣的是利用犹他大学在西谷中心南部 5600 West 建造的新医疗设施的机会。计划将 SLCC 的健康科学项目扩展到西谷中心,并最终为这些项目建造专用空间。与机构营销部门的合作还促成了附录 B - 西谷营销计划中包含的针对西班牙语的营销工作。有关参与社区 CWT 的完整详细信息可在其年终报告中找到。

使用 YOLOv10 进行脑肿瘤检测和分类...
洛克奈特戈皮纳特吉蒙德工程教育与研究学院 (LOGMIEER),纳西克,印度 摘要:先进的医学成像技术与人工智能 (AI) 的结合极大地提高了脑肿瘤的早期发现和诊断。本文介绍了一种使用 YOLOv10(You Only Look Once)模型进行脑肿瘤检测和分类的新型系统,该系统通过由大型语言模型 (LLM) 驱动的 AI 聊天机器人进行增强。利用 YOLOv10 的实时物体检测功能,该系统可以准确地将 MRI 图像中的脑肿瘤分为四类:神经胶质瘤、脑膜瘤、垂体和无肿瘤。这种基于深度学习的方法可以确保快速准确地分析复杂的医学图像。此外,还集成了一个 AI 聊天机器人,为患者和医疗专业人员提供无缝交互和信息检索。利用 LLM,聊天机器人提供高级对话能力,根据检测到的肿瘤特征提供有关肿瘤类型、潜在治疗方法和进一步医疗建议的详细解释。这种双系统方法旨在提高诊断准确性,同时提供实时、可访问的支持,最终改善医务人员的决策并改善患者的治疗效果。所提出的系统体现了尖端人工智能技术与医疗诊断之间的协同作用,展示了彻底改变患者护理的潜力。关键词:YOLOv1o、法学硕士、聊天机器人、脑肿瘤、松果

BENLYSTA(贝利木单抗)注射剂,供静脉注射 BENLYSTA(贝利木单抗)注射剂,供皮下注射 美国首次批准:2011 年
• 患有 SLE 或狼疮性肾炎的成人和儿童患者的静脉剂量:前 3 次剂量每 2 周一次,每次 10 mg/kg,之后每 4 周一次。配制、稀释后在 1 小时内静脉输注给药。(2.2)- 考虑预防性输液反应和超敏反应。(2.2)• 患有 SLE 的成人患者的皮下剂量:- 每周一次,每次 200 mg。(2.3)• 患有 SLE 的儿童患者的皮下剂量:- 体重大于或等于 40 kg:每周一次,每次 200 mg。(2.3)- 体重 15 kg 至 40 kg 以下:每 2 周一次,每次 200 mg。 (2.3) • 狼疮性肾炎成人患者的皮下注射剂量:每周一次 -400 毫克(两次 200 毫克注射),共注射 4 次,之后每周一次 200 毫克。 (2.3) • 有关完整的准备和给药信息,请参阅完整处方信息。 (2.2, 2.3)

BS微生物学(285120)地图表
Requirement 1 — Complete 1 of 3 CoursBIO 264es BIO 130 - Biology 4.0 CELL 120 - Science of Biology 3.0 MMBIO 121 - Gen Biology: Health & Disease 3.0 Requirement 2 —Complete 4 Courses MMBIO 151 - Microbiology 4.0 MMBIO 240 - Molecular Biology 3.0 MMBIO 241 - Molecular & Cellular Bio Lab 1.0 MMBIO 261 - Infection &免疫力3.0需求3 - 整盘12小时MMBIO 360-细菌遗传学4.0 MMBIO 363-微生物生态学2.0 MMBIO 364-细菌发病机理3.0 MMBIO 3.0 MMBIO 366-微生物生态学实验室1.0 MMBIO 385 -MMBIO 385-噬菌体3.0 Mmbio 418-医学parasogial parasogial parasogial parasologicy -41.20 2 2. 0 2 2. 0 2 2. 0 2 2. 0 2 2. 0 2 2. Physiology 3.0 MMBIO 463 - Immunology 3.0 MMBIO 465 - Virology 3.0 MMBIO 466 - Virology Laboratory 1.0 MMBIO 467 - Immunology Lab 1.0 Requirement 4 —Complete 4 Courses CHEM 105 - Gen College Chem 1+Lab Integr 4.0 CHEM 106 - General College Chemistry 2 3.0 CHEM 107 - Gen Coll Chem Lab 1.0 PHSCS 105 - General Physics 1 3.0 Requirement 5 - 拼写1个课程化学285-启动生物有机化学4.0化学351-有机化学1 3.0要求6-校准1个课程数学数学112-微积分1 4.0 STAT 121-统计数据数据介绍到统计数据分析的介绍3.0要求7 - complete 7 - complete 14小时,用于满足需求1-6可能不满足1-6对于某些选修课程,有限数量的学时可以计入这一选修要求。Option 7.1 —Complete at least 10 hours up to 14 hours BIO 165 - Introduction to Bioinformatics 3.0 BIO 250 - Evolutionary Medicine 2.0 BIO 264 - Stat Analysis for Biologists 4.0 BIO 350 - Ecology 3.0 BIO 420 - Evolutionary Biology 4.0 BIO 463 - Genetics of Human Disease 3.0 CELL 305 - Human Physiology 4.0 CELL 325 - Tissue Biology (with lab) 3.0 CELL 360 - Cell Biology 3.0 CELL 362 - Advanced Physiology 3.0 CELL 363 - Adv Physiology Lab 1.0 CHEM 351 - Organic Chemistry 1 3.0 CHEM 352 - Organic Chemistry 2 3.0 CHEM 353 - Organic Chem Lab-Nonmajors 1.0v CHEM 481 - Biochemistry 3.0 CHEM 482 - Mechanisms of Molecular Biol 3.0 MMBIO 110R - Extremophiles - You may take once 1.0 MMBIO 122 - Gen Biol: Health/Disease Lab 1.0 MMBIO 162R - Careers in Biomed Sciences - You may take once 1.0 MMBIO 194 - Phage Discovery 3.0 MMBIO 195 - Phage Comparative Genomics 3.0 MMBIO 294R - Mentored Research - You may take up to 2.0 credit hours 0.5v MMBIO 350 - Genetic Counseling 3.0 MMBIO 360 - Microbial遗传学4.0 MMBIO 364-细菌发病机理3.0 MMBIO 366-微生物生态实验室1.0