XiaoMi-AI文件搜索系统
World File Search Systempred

太平洋经济发展路线图(PRED)。......
2022 年,经济部长们指出,新冠肺炎疫情给经济造成了前所未有的创伤,并重申疫情迫使该地区采取不同的做法,并采取更积极主动的措施。部长们随后指出,需要优先制定太平洋经济发展路线图 (PRED)(以前称为蓝色太平洋经济战略 (BPES)),以探索应对疫情经济影响的创新和集体方法,并使该地区能够加强未来对此类事件的区域应对措施。部长们进一步强调,迫切需要加强所有区域经济集体参与的战略和协调,以避免重复。经济部长们指示,制定 PRED 并与蓝色太平洋大陆 2050 年战略实施计划保持一致。
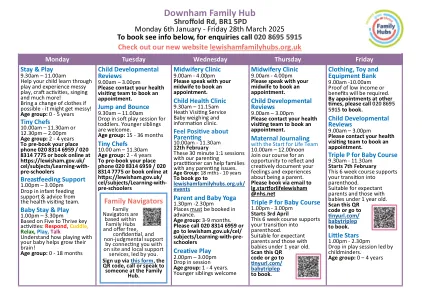
唐姆家庭中心
星期一星期三星期三星期五星期五逗留和玩耍和玩耍,上午9.30 - 11.00am,帮助您的孩子通过玩耍和体验杂乱的玩法,CraōAcɵviɵes,唱歌等等!如果可能的话,请换衣服 - 可能会凌乱!年龄组:0 - 5年小厨师10.00 am - 11.30am – 11.30 am或12.30pm - 2.00pm - 年龄组:2 - 4年预订 - 预订您的位置电话020 8314 6959/020 8314 77775或在hʃps://lewisham.gov.uk/ cel/pred -pree -pree -preepm -pree -preed -preed -preed -preed -preed -pred -pred -pred -pred -pred -pred -pred -pred -pred -pred -pred -pred -preecim-在婴儿喂养支持和咨询中的婴儿visiɵng团队的建议中。婴儿住宿和玩耍1.00pm - 3.30pm基于五个壮成长的钥匙:响应,拥抱,放松,玩耍,谈话,了解如何与宝宝玩耍有助于增长他们的大脑!年龄组:0-18个月

脚和口疾病:Red Book Pred Prep 2020年10月7日
FMD响应计划可以指向其他各种联邦和州机构和私人组织的链接。这些链接仅用于用户的信息和便利性。如果您链接到该网站,请注意,您将受到该网站的政策的约束。此外,请注意,USDA无法控制,也不能保证这些外部材料的相关性,及时性或准确性。此外,在超文本中包含链接或指示与特定项目的链接或指示并不是要反映其重要性,也不旨在构成在这些外部网站上,或在这些组织上赞助网站上表达的任何观点或提供的产品或服务的认可。

评估外推法预测谷浓度以指导口服抗癌药物的治疗药物监测
Methods: Plasma concentrations of abiraterone, dabrafenib, im- atinib, and pazopanib at a random time (C t,sim ) and at the end of the dosing interval (C min,sim ) were simulated from population pharma- cokinetic models including 1000 patients, and the values were con- verted into simulated observed concentrations (C t,sim,obs and C min,sim,obs ) by adding a residual error.,以C T,SIM,SIM,OBS和典型的种群浓度的比率(方法1)与C Min,SIM,SIM 2)的典型种群值(方法2)和log-linearearearearexextral(方法3)相乘。通过比较c min进行比较,评估了目标的目标,即与拟议的相关靶标与效率相关和计算阳性预测和负预测值有关。

Alpha Pro Tech,Ltd。宣布200万美元的扩张
公司联系:投资者关系联系:Alpha Pro Tech,Ltd。Hayden ir Donna Millar Cameron Donahue 905-479-0654 651-653-1854电子邮件:ir@alphaprotech.com:ir@alphaprotech.com电子邮件:cameron@cameron@haydenir.com Nogales,Arizona,Alizona,Alizona - Alse Sech 23224-23,2024年,PROD:PROD:PROD:PROD:PRED:PRED:PRED: - lapla; APT)是旨在保护人员,产品和环境(包括一次性保护服装和建筑产品)的产品的领先产品制造商,今天宣布其董事会已授权对公司现有的股票回购计划进行2000万美元的扩张。有了这一授权扩张,该公司现在有大约280万美元可用于回购公司普通股,其中80万美元属于上一家扩张,最近在2024年10月宣布。管理层预计通过公开市场购买或通过私人协商的交易来回购股票,并打算退休通过股票回购计划购买的所有股票。开放市场购买可以通过预先安排的回购计划执行,该计划根据规则10B5-1和1934年《证券交易所法》规则10B-18规则的指南进行操作,该计划经修订。回购计划下的任何交易将根据计划的条款进行,包括指定的价格,数量和时机条件,并将根据公司股票回购计划的授权金额申请。其他开放市场和私人谈判的购买可能会不时地基于市场和一般业务条件在回购计划之外,但要遵守适用的规定和法规。关于Alpha Pro Tech,Ltd。Alpha Pro Tech,Ltd。是Alpha Pro Tech,Inc。和Alpha Protech Engineered Products,Inc。Alpha Pro Tech,Inc。的母公司。Alpha Protech Engineered Products,Inc。生产和销售建筑气候产品,包括建筑包装和屋顶衬里。该公司在亚利桑那州Nogales设有制造设施;佐治亚州瓦尔多斯塔;以及印度的合资企业。

制造指南RO1200材料
工具:RO1200材料与许多工具系统兼容。选择是否使用圆形或开槽的引脚,外部或内部固定,标准或中心线(多行)工具,以及pre ded pred vs.后冲孔将取决于电路设施的功能和偏好以及最终的注册要求。一般而言,开槽的销钉,中心线工具格式和后口气的打孔将满足大多数需求。无论采用哪种方法,都可以在工具孔周围保留铜。一般而言,建议只有在使用36或72微米铜箔的加工芯上,只有在加工芯上涂抹芯时,建议使用18微米铜箔在核心两侧的工具孔周围保持铜。
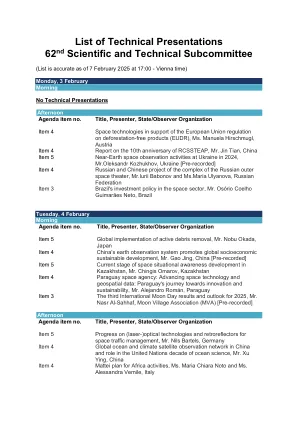
技术演示清单第62科学和...
议程项目编号。Title, Presenter, State/Observer Organization Item 9 Peaceful Applications of Space Rocks: JAXA's Contributions to Science and Humanity, Mr. Tomohiro Usui, Japan Item 6 Space based information for emergency management in China (2024), Ms. Liu Longfei, China Item 8 Development of space weather monitoring system components in Kazakhstan, Mr. Serik Nurakynov, Kazakhstan Item 6 ASI activities on space-system-based灾难管理,意大利的Simona Zoffoli女士[预先录制]项目5的状态和韩国共和国的太空情境意识的计划,Choi Eun Jung女士,韩国共和国第8项目8,太空阳光系统创造的一般问题,Anatolii P. Alpatov先生和Erik O. Lapkhanov先生,Pred Record,ucukraine [Predive] precriped

技术演示清单第62科学和...
议程项目编号。Title, Presenter, State/Observer Organization Item 9 Peaceful Applications of Space Rocks: JAXA's Contributions to Science and Humanity, Mr. Tomohiro Usui, Japan Item 6 Space based information for emergency management in China (2024), Ms. Liu Longfei, China Item 8 Development of space weather monitoring system components in Kazakhstan, Mr. Serik Nurakynov, Kazakhstan Item 6 ASI activities on space-system-based灾难管理,意大利的Simona Zoffoli女士[预先录制]项目5的状态和韩国共和国的太空情境意识的计划,Choi Eun Jung女士,韩国共和国第8项目8,太空阳光系统创造的一般问题,Anatolii P. Alpatov先生和Erik O. Lapkhanov先生,Pred Record,ucukraine [Predive] precriped


基于软件成本估算的基于降低和机器学习模型
软件成本估计(SCE)是构建网络物理 - 社会系统(CPSS)的研究重点和挑战之一。在CPSS中,要准确处理环境和社会信息并使用它来指导社会实践。因此,在回应SCE的预测准确性低,鲁棒性和可解释性差的问题时,本文提出了基于自动编码器和随机森林的SCE模型。首先,预处理项目数据,删除异常值,然后构建回归树以在数据中缺少属性中填充。第二,构建一个自动编码器,以降低影响软件成本的因素的维度。随后,使用三个数据集上的XGBoost框架(Cocomo81,Albrecht和Desharnais)对模型的性能进行了训练和验证,并与常见的成本预测模型进行了比较。实验结果表明,COCOMO81数据集上提出的模型的MMRE,MDMRE和PRED(0.25)值分别达到0.21、0.16和0.71。与其他模型相比,所提出的模型在准确性和鲁棒性方面取得了重大改进。