XiaoMi-AI文件搜索系统
World File Search Systemprediction

多动症中的个性化预测模型
越来越多的努力为支持个性化检测,预测或多动症治疗的预测模型做出了越来越多的努力。我们概述了ADHD中预测科学的当前状态:(1)系统地审查和评估可用的预测模型; (2)定量评估影响已发表模型性能的因素。我们进行了Prisma/Charms/Tripod符合的系统评价(Prospero:CRD42023387502),直到20/12/2012/2023,在ADHD中进行了内部和/或外部验证的诊断/或外部验证的诊断/或外部验证的诊断/治疗响应预测。使用元回归,我们探索了影响模型曲线(AUC)下面积的因素的影响。我们使用偏见评估工具的预测模型风险(Probast)评估了偏见的研究风险。从7764个识别记录中包括100个预测模型(诊断为88%,预后5%和7%的治疗响应)。分别在内部和外部验证96%和7%。在临床实践中没有实施。只有8%的模型被视为偏见的风险低; 67%被认为是偏见的高风险。临床,神经影像学和认知预测因子分别用于35%,31%和27%的研究。与不包括临床预测因子在内的那些模型相比,ADHD预测模型的性能增加了(β= 6.54,p = 0.007)。验证类型,年龄范围,模型类型,预测因子的数量,研究质量和其他类型的预测变量并未改变AUC。已经开发了几种预测模型来支持多动症的诊断。但是,预测结果或治疗反应的努力受到限制,并且没有一个可用模型可以准备在临床实践中实施。使用临床预测因子的使用可能与其他类型的预测指标相结合,似乎可以提高模型的性能。新一代研究应通过进行高质量,可复制和外部验证的模型,然后进行实施研究来解决这些差距。
机器人加速器的碰撞预测
摘要 - 动态环境中的动作计划是自动机器人技术的重要任务。新兴方法采用可以通过观察(例如人类)专家来学习的神经网络。此类运动计划者通过不断提出候选路径以实现目标来对环境做出反应。这些候选路径中的一些可能是不安全的,即导致碰撞。因此,必须使用碰撞检测检查提议的路径以确保安全。我们观察到,如果我们可以预期哪些查询将返回不安全的结果,则可以消除25% - 41%的碰撞检测查询。我们利用这一观察结果提出了一种机制坐标,以预测沿拟议路径的给定机器人位置(姿势)是否会导致碰撞。通过优先考虑对预测碰撞的详细评估,坐标可以快速消除神经网络和其他基于采样的运动计划者提出的无效路径。坐标通过利用不同机器人姿势的物理空间位置并使用简单的哈希和饱和计数器来实现这一目标。我们证明了在包括CPU,GPU和ASIC在内的不同计算平台上碰撞预测的潜力。我们进一步提出了一个硬件碰撞预测单元(COPU),并将其与现有的碰撞检测加速器集成在一起。这平均17。2% - 32。跨不同运动计划算法和机器人的碰撞检测查询数量减少了1%。当应用于最先进的神经运动计划者[41]时,坐标会提高性能/瓦特1。平均而言,针对不同难度水平的运动计划查询。此外,我们发现碰撞预测的好处随着运动计划查询的计算复杂性增加并提供1。30×在狭窄的段落和混乱的环境中进行性能/瓦特的迹象。索引术语 - 机器人,硬件加速度,运动计划,碰撞检测,碰撞预测

用于预测...
代表Länsförsäkringar,本研究重点是使用三种不同的机器学习算法构建的三个模型在接受与Länsförsäkringar当前模型相同的数据进行培训时执行的。使用的算法是随机森林,XGBoost和人工神经网络,所使用的数据集由持有2007年至2019年之间的私人客户组成。此外,该研究还涵盖了现场的当前文献,特征分析,可变选择以及对模型优化的超参数培训。根据选定的性能度量AUC,Brier分数和对数损失的模型是XGBoost模型,该模型与以前的几项研究的发现一致。发现该模型的透明度和解释性不如逻辑回归,但该模型并不完全缺乏透明度。研究表明,如何在PD建模领域实施这些模型以及如何解释和更改Finansinspektionen和EU的要求,以使风险管理中的实施机器学习。

泰国的3个月气候预测
通常2月,本月是在从冬季到夏天的过渡期。换句话说,泰国盛行的高压空气质量区域将开始削弱。仍然,泰国的常见天气仍然与早晨的雾气保持凉爽,而北部和东北部的雾气仍然在某些地区冷至非常寒冷,大部分是在本月的一半。之后,温度升高是由于盛行的热风替换了东北季风。因此,自本月中旬以来,夏天开始出现。此外,泰国南部的降雨将少于过去一个月,尤其是在东海岸。

机械精炼机的可靠性预测
可靠性是指系统在运行过程中的质量、对要求的满足以及最终产品的质量生产。磨浆机也是一种工业设备,用于改善原材料的性能,并为最终产品的生产做好准备。在机械纸浆生产行业中,磨浆机在产品生产中的作用及其对产品质量和总成本的影响非常重要。本文介绍了机械磨浆机的结构,研究了决定和提高可靠性的主要部件,并计算了它们的可靠性值。根据计算,该设备最有影响力的元件是机械密封,在选择和监控其状态时应比其他元件更加小心,以达到目标的可靠性。


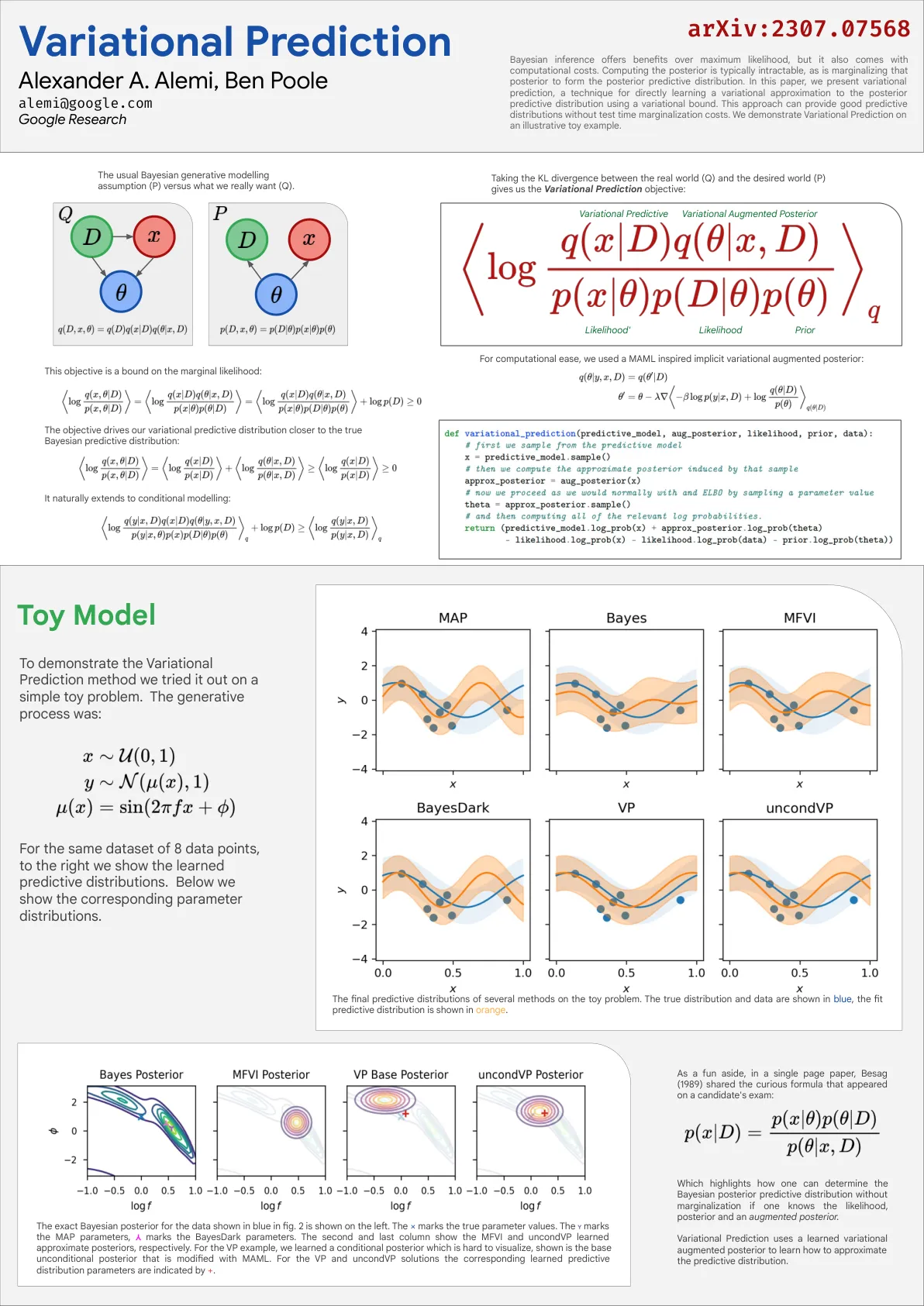

财务困扰预测模型
摘要。有关预测财务困境的研究是公司财务中的一个重要话题,因为它是债权人,投资者,监管机构和其他利益相关者的预警信号。许多研究专注于具有财务和宏观经济数据的预测模型,但并不多于财务,宏观经济,公司治理和智力资本数据结合在一起。本研究结合了这四个因素,形成了全面的财务困扰预测模型。本研究使用Prisma方法使用系统文献综述(SLR)。结果预计将有助于财务管理并支持可持续发展目标(SDG),因为公司财务健康支持可持续的经济增长,创新和基础设施。财务稳定的公司可以采用负责任的商业实践,尽早管理风险,避免破产,维持就业,并为经济和社会繁荣做出贡献,并支持整个可持续发展目标指标的实现。

传感器
摘要目的:这项研究的目的是在硅QSAR-神经网络模型中开发出强大的外部预测性,用于预测药物的血浆蛋白结合。该模型旨在通过减少化学合成和广泛的实验室测试的需求来增强药物发现过程。方法:使用277种药物的数据集来开发QSAR神经网络模型。使用滤波器方法构建模型,以选择55个分子描述符。通过预测平方相关系数Q2和均方根误差(RMSE)评估了验证集的外部精度。结果:开发的QSAR神经网络模型显示出鲁棒性和良好的适用性域。验证集的外部准确性很高,预测平方相关系数Q2为0.966,均方根误差(RMSE)为0.063。相对,该模型的表现优于文献中先前发布的模型。结论:该研究成功地开发了一种高级QSAR神经网络模型,能够预测人类血浆中277种药物的血浆结合。该模型的准确性和鲁棒性使其成为药物发现中的宝贵工具,有可能减少对资源密集型化学合成和实验室测试的需求。