XiaoMi-AI文件搜索系统
World File Search Systempresentations

海报展示
CDT Charles Christianson,虽然航空车可以访问比地面系统更大的空间,但传统上,它们无法操纵工具或物体来在环境上执行有用的工作。 这样的能力可以大大扩展可以通过机器人执行的任务类型,从而提供增强的人类安全。 但是,对于有限的有限载荷,对稳定性敏感的平台(例如无人机),实现多种物体形状和尺寸的强大抓地力是具有挑战性的。 在本文中,我们描述了符合UAV上使用的符合干扰夹的设计和制造。 然后,我们在各种不同的物体特征形状和尺寸上分析了抓地力的性能。 最终,我们证明,由于其多功能性,合规性和易于操作,这种抓手是空中抓地的好候选者。 关键字:干扰,机器人,空中,抓握,操纵联系人:Raymond Vonwahlde先生,RDRL-VTA BLDG 1120B 1120B,APG,MD 21005CDT Charles Christianson,虽然航空车可以访问比地面系统更大的空间,但传统上,它们无法操纵工具或物体来在环境上执行有用的工作。这样的能力可以大大扩展可以通过机器人执行的任务类型,从而提供增强的人类安全。但是,对于有限的有限载荷,对稳定性敏感的平台(例如无人机),实现多种物体形状和尺寸的强大抓地力是具有挑战性的。在本文中,我们描述了符合UAV上使用的符合干扰夹的设计和制造。然后,我们在各种不同的物体特征形状和尺寸上分析了抓地力的性能。最终,我们证明,由于其多功能性,合规性和易于操作,这种抓手是空中抓地的好候选者。关键字:干扰,机器人,空中,抓握,操纵联系人:Raymond Vonwahlde先生,RDRL-VTA BLDG 1120B 1120B,APG,MD 21005

演示清单
不仅世界的人口在不断增长,而且全球许多城市也会遭受永久性增长,即使在人口数量不断甚至缩小的国家和地区也是如此。全球城市化不仅在基础架构,流动性,住房和空间计划方面引起了新的挑战,而且在缓解气候变化和采用方面尤其是在技术变革方面,尤其是数字化,在不利条件下对多种自然和人造挑战的韧性以及对多种自然和人造挑战的韧性以及对生活质量提高生活质量的抗韧性。在世界大城市中,必须大规模应对这些挑战 - 必须应对所有技术,组织,行政障碍。中型和较小的城市呢?在创新方面,它们是否比“大型油轮”更快,更灵活,更高效?他们可以带领前往光明的未来吗?他们可以带我们去解决以前没有城市去过的解决方案,尤其是在可持续性,韧性,尤其是整个社会生活质量的标准时?一方面可以将较小规模开发的解决方案提高到大都市,甚至可以滴入小城市和农村地区吗?可以轻松地上下缩放措施,还是需要完全不同的方法?因此,我们邀请所有参与城市发展和空间规划及相关领域的学科的贡献,以便以整体方式分析城市空间未来的挑战。真正的公司会议自1996年以来每年举行。除了基于科学的贡献外,我们还欢迎有关城市和区域发展的短期措施和/或长期策略的基于实践的报告。您正在处理哪些问题和主题,您所在城市或您曾经或正在努力的地方面临哪些挑战?传统上,我们一直在保持真实公司会议的主题范围非常广泛 - 因为我们坚信,使用会议来听取其他主题的启发,并可能完全不同的方法和非常重要的方式来了解其他主题,这是有利的,并且是必不可少的:与他们一起发展的专业和个性,以使他们与他们的专业和个性相同,从而使他们与他们发展的态度 - 不可能开发出来,并且可以使他们的范围和庞大的态度发展,并且可能会发展壮大,并可能会发展壮大,并可能发展壮大,并且可以使您的范围和网络发展壮大,并可能会发展壮大,并且可以努力发展,并可能发展壮大,并且可以通过勇敢的范围进行启发。 前。来自城市规划,智能城市,流动性和交通计划,信息和通信技术,建筑,社会和环境科学,房地产,GIS,GIS,测量和遥感的数百名专家,以及更多的跨越国际和跨学科的城市规划,地区规划和信息社会的主题。在会议日提供了150至180个专家讲座,演讲,圆桌讨论,讲习班和小型展览,由传统的广泛社会计划组成,非正式的欢迎,晚间接待,向公司进行旅行或在该地区实施城市解决方案等。
口头演示
会议1A:全体会议I会议椅:Xiuling Li和Luke Mawst,星期一,星期一,5月13日,2024年5月13日,凡尔赛塔,诺曼底舞厅2楼1 8:15 AM开幕词上午8:30 AM *1A.1 ALN -MOVPE ZLATKO ZLATKO SITAR; NCSU,美国单晶铝氮化铝的直接带隙为6.1 eV,还带来了实现深紫外光电子,极端RF和功率设备的技术机会,此外还可以进行量子相互作用。由于ALN底物实际上没有位错,可以将Movpe同型的表面形态从2D-核的控制到阶梯流增长,甚至逐层生长。生长过程通过全包表面动力学框架进行定量描述,该框架连接输入蒸气过饱和,表面过饱和,表面扩散长度和底物不良方向角度。表面特征的管理对于三元合金和均匀掺杂的生长至关重要。从历史上看,ALN的电导率非常有限,大概是由于DX - 过渡形成受体状态和随后的自我补偿,这对可实现的自由载体浓度施加了严重的上限。然而,最近的结果表明,该过渡代表了从浅层到深层供体状态的平衡热力学转变,该状态可以动力学控制。iii-V复合半导体现在通过各种方式与基于SI的电子设备集成了电信和数据通信的光纤网络中,以扩展集成系统的性能和功能。这些事态发展不仅具有强大的UV光电设备,而且还采用了近乎理想的基于ALN的Schottky二极管,支持高达3 ka/cm 2的电流,并且稳定的操作高达700°C,以高达700°C,证明了ALN作为极端环境电源设备的平台。上午9:15 *1A.2在SOI上集成III-V主动设备的新范式 - 沿左侧选择性Movpe Kei May Lau;香港科学技术大学,香港高性能高频和光子设备由复合半导体主导,复合半导体具有先天波长的灵活性,并可以促进电子的高速运输,并结合了异性结构。除了速度和带宽优势外,通过光子而不是电子发送数据可能会更多的能量


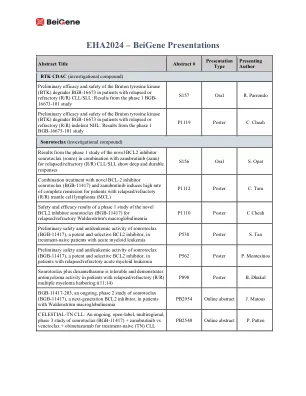
EHA2024 - Beigene演示
与新型BCL-2抑制剂SONROTOCLAX(BGB-11417)和Zanubrutinib的组合处理可诱导复发/难治(R/R)地幔细胞淋巴瘤(MCL)患者的高缓解率。



简短的演示和海报
简短的演示和海报1。使用陀螺仪Gyrolab XP系统支持高通量AAV样品测试。夏洛特·科克希尔(Charlotte Corkhill),保罗·杨(Paul Young),英国Pharmaron。2。通量采样表明高抗体产生CHO细胞的代谢特征。Kate Meeson,Jean Marc Schwartz,Magnus Rattray,曼彻斯特大学;英国比林汉姆(Billingham)的富士夫(Fujifilm Diosynth Biotechnologies)Leon Pybus,富士夫。 3。 将行业领先的数据集与基因组规模的代谢模型集成到指导CHO细胞系工程。 Ben Strain,Cleo Kontoravdi,伦敦帝国学院; Holly Corrigall,Pavlos Kotidis,GSK,Stevenage,英国。 4。 绿色藻类衣原体中的叶绿体工程,用于生产新型重组产品。 Luyao Yang,Saul Purton;英国伦敦大学学院。 5。 哺乳动物细胞培养物中乳酸代谢转移的分子驱动因素。 毛罗·托雷斯(Mauro Torres),埃莉·霍克(Ellie Hawke),安德鲁·海斯(Andrew Hayes),艾伦·J·迪克森(Alan J Dickson),曼彻斯特大学; Robyn Hoare,Rachel Scholey,Leon Pybus,Alison Young,Fujifilm Diosynth Biotechnologies,英国Billingham。 6。 使用单个整体可发展性参数合理化mab候选筛选。 Leon F Willis,William Davis Birch,David Westhead,Nikil Kapur,Sheena Radford,David Brockwell,Leeds大学; Isabelle Trayton,Janet Saunders,Maria Bruque,Katie Day,Nicholas Bond,Paul Devine,Christopher Lloyd,Nicholas Darton,Astrazeneca,英国。 7。 用于生物医学应用的磁体鸡尾酒的生物制造和配方。 8。 9。 10。Kate Meeson,Jean Marc Schwartz,Magnus Rattray,曼彻斯特大学;英国比林汉姆(Billingham)的富士夫(Fujifilm Diosynth Biotechnologies)Leon Pybus,富士夫。3。将行业领先的数据集与基因组规模的代谢模型集成到指导CHO细胞系工程。Ben Strain,Cleo Kontoravdi,伦敦帝国学院; Holly Corrigall,Pavlos Kotidis,GSK,Stevenage,英国。 4。 绿色藻类衣原体中的叶绿体工程,用于生产新型重组产品。 Luyao Yang,Saul Purton;英国伦敦大学学院。 5。 哺乳动物细胞培养物中乳酸代谢转移的分子驱动因素。 毛罗·托雷斯(Mauro Torres),埃莉·霍克(Ellie Hawke),安德鲁·海斯(Andrew Hayes),艾伦·J·迪克森(Alan J Dickson),曼彻斯特大学; Robyn Hoare,Rachel Scholey,Leon Pybus,Alison Young,Fujifilm Diosynth Biotechnologies,英国Billingham。 6。 使用单个整体可发展性参数合理化mab候选筛选。 Leon F Willis,William Davis Birch,David Westhead,Nikil Kapur,Sheena Radford,David Brockwell,Leeds大学; Isabelle Trayton,Janet Saunders,Maria Bruque,Katie Day,Nicholas Bond,Paul Devine,Christopher Lloyd,Nicholas Darton,Astrazeneca,英国。 7。 用于生物医学应用的磁体鸡尾酒的生物制造和配方。 8。 9。 10。Ben Strain,Cleo Kontoravdi,伦敦帝国学院; Holly Corrigall,Pavlos Kotidis,GSK,Stevenage,英国。4。绿色藻类衣原体中的叶绿体工程,用于生产新型重组产品。Luyao Yang,Saul Purton;英国伦敦大学学院。 5。 哺乳动物细胞培养物中乳酸代谢转移的分子驱动因素。 毛罗·托雷斯(Mauro Torres),埃莉·霍克(Ellie Hawke),安德鲁·海斯(Andrew Hayes),艾伦·J·迪克森(Alan J Dickson),曼彻斯特大学; Robyn Hoare,Rachel Scholey,Leon Pybus,Alison Young,Fujifilm Diosynth Biotechnologies,英国Billingham。 6。 使用单个整体可发展性参数合理化mab候选筛选。 Leon F Willis,William Davis Birch,David Westhead,Nikil Kapur,Sheena Radford,David Brockwell,Leeds大学; Isabelle Trayton,Janet Saunders,Maria Bruque,Katie Day,Nicholas Bond,Paul Devine,Christopher Lloyd,Nicholas Darton,Astrazeneca,英国。 7。 用于生物医学应用的磁体鸡尾酒的生物制造和配方。 8。 9。 10。Luyao Yang,Saul Purton;英国伦敦大学学院。5。哺乳动物细胞培养物中乳酸代谢转移的分子驱动因素。毛罗·托雷斯(Mauro Torres),埃莉·霍克(Ellie Hawke),安德鲁·海斯(Andrew Hayes),艾伦·J·迪克森(Alan J Dickson),曼彻斯特大学; Robyn Hoare,Rachel Scholey,Leon Pybus,Alison Young,Fujifilm Diosynth Biotechnologies,英国Billingham。6。使用单个整体可发展性参数合理化mab候选筛选。Leon F Willis,William Davis Birch,David Westhead,Nikil Kapur,Sheena Radford,David Brockwell,Leeds大学; Isabelle Trayton,Janet Saunders,Maria Bruque,Katie Day,Nicholas Bond,Paul Devine,Christopher Lloyd,Nicholas Darton,Astrazeneca,英国。 7。 用于生物医学应用的磁体鸡尾酒的生物制造和配方。 8。 9。 10。Leon F Willis,William Davis Birch,David Westhead,Nikil Kapur,Sheena Radford,David Brockwell,Leeds大学; Isabelle Trayton,Janet Saunders,Maria Bruque,Katie Day,Nicholas Bond,Paul Devine,Christopher Lloyd,Nicholas Darton,Astrazeneca,英国。7。用于生物医学应用的磁体鸡尾酒的生物制造和配方。8。9。10。AlfredFernández-Castané,Hong Li,Moritz Ebeler,Matthias Franzreb,Tim W. Overton,Owen R.T.托马斯,阿斯顿大学。 使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。 James Harvey,Yukti Kataria,Titash Sen,Lonza,英国。 使用新型差异氟化和19F NMR研究脂多糖与单克隆抗体之间的相互作用。 詹姆斯·贝奇(James Budge),肯特大学。 使用Amperia生成高产生的克隆人群进行IgG滴定分析。 Matthew Reaney,Zeynep Betts,艾伦·迪克森(Alan Dickson),曼彻斯特大学; Jon Dempsey,Pathway Biopharma Ltd. 11. 脂质体过滤污垢的表征:压力变化对无菌过滤性能的影响。 大力神Argyropoulos,Daniel G. Bracewell,Thomas F. Johnson,UCL; Nigel Jackson,Kalliopi Zourna,Cytiva UK。 12。 一种混合化学计量/数据驱动的方法,可改善细胞内通量预测。 Morrissey J,Barberi G,Facco P,Strain B Kintoravdi C,英国伦敦帝国学院。 13。 无细胞的DNA扩增基因组医学 - 课程的马。 Priya Srivastava,Daniel G. Bracewell,生物化学工程系,UCL;约翰·威尔士(John Welsh),英国Cytiva Europe Limited。 14。 合成生物学方法是为AAV CAPSIDS提高有效负载基因组上传的方法。 Tina Chen,Robert Whitfield,Darren Nesbeth,英国伦敦大学学院。 15。 使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。AlfredFernández-Castané,Hong Li,Moritz Ebeler,Matthias Franzreb,Tim W. Overton,Owen R.T.托马斯,阿斯顿大学。使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。James Harvey,Yukti Kataria,Titash Sen,Lonza,英国。使用新型差异氟化和19F NMR研究脂多糖与单克隆抗体之间的相互作用。詹姆斯·贝奇(James Budge),肯特大学。使用Amperia生成高产生的克隆人群进行IgG滴定分析。Matthew Reaney,Zeynep Betts,艾伦·迪克森(Alan Dickson),曼彻斯特大学; Jon Dempsey,Pathway Biopharma Ltd. 11. 脂质体过滤污垢的表征:压力变化对无菌过滤性能的影响。 大力神Argyropoulos,Daniel G. Bracewell,Thomas F. Johnson,UCL; Nigel Jackson,Kalliopi Zourna,Cytiva UK。 12。 一种混合化学计量/数据驱动的方法,可改善细胞内通量预测。 Morrissey J,Barberi G,Facco P,Strain B Kintoravdi C,英国伦敦帝国学院。 13。 无细胞的DNA扩增基因组医学 - 课程的马。 Priya Srivastava,Daniel G. Bracewell,生物化学工程系,UCL;约翰·威尔士(John Welsh),英国Cytiva Europe Limited。 14。 合成生物学方法是为AAV CAPSIDS提高有效负载基因组上传的方法。 Tina Chen,Robert Whitfield,Darren Nesbeth,英国伦敦大学学院。 15。 使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。Matthew Reaney,Zeynep Betts,艾伦·迪克森(Alan Dickson),曼彻斯特大学; Jon Dempsey,Pathway Biopharma Ltd. 11.脂质体过滤污垢的表征:压力变化对无菌过滤性能的影响。大力神Argyropoulos,Daniel G. Bracewell,Thomas F. Johnson,UCL; Nigel Jackson,Kalliopi Zourna,Cytiva UK。12。一种混合化学计量/数据驱动的方法,可改善细胞内通量预测。Morrissey J,Barberi G,Facco P,Strain B Kintoravdi C,英国伦敦帝国学院。 13。 无细胞的DNA扩增基因组医学 - 课程的马。 Priya Srivastava,Daniel G. Bracewell,生物化学工程系,UCL;约翰·威尔士(John Welsh),英国Cytiva Europe Limited。 14。 合成生物学方法是为AAV CAPSIDS提高有效负载基因组上传的方法。 Tina Chen,Robert Whitfield,Darren Nesbeth,英国伦敦大学学院。 15。 使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。Morrissey J,Barberi G,Facco P,Strain B Kintoravdi C,英国伦敦帝国学院。13。无细胞的DNA扩增基因组医学 - 课程的马。Priya Srivastava,Daniel G. Bracewell,生物化学工程系,UCL;约翰·威尔士(John Welsh),英国Cytiva Europe Limited。14。合成生物学方法是为AAV CAPSIDS提高有效负载基因组上传的方法。Tina Chen,Robert Whitfield,Darren Nesbeth,英国伦敦大学学院。 15。 使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。Tina Chen,Robert Whitfield,Darren Nesbeth,英国伦敦大学学院。15。使用Lonza的GS PiggyBac技术开发了高通量DWP的转染平台。James Harvey,Yukti Kataria,Titash Sen,R&D Lonza Biologics,英国。 div>
