XiaoMi-AI文件搜索系统
World File Search Systempython
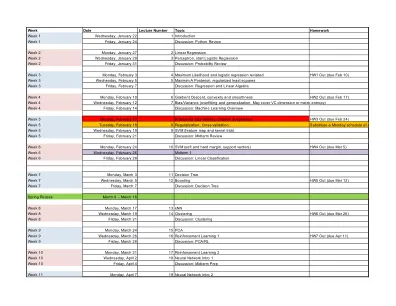


使用 Python 进行人工智能编程
成功的软件开发人员需要知道如何将深度学习模型融入日常应用中。任何带有摄像头的设备都将使用图像分类、对象检测和人脸识别,所有这些都基于深度学习模型。在这个项目中,您将实现一个图像分类应用程序。此应用程序将在图像数据集上训练深度学习模型。然后它将使用训练后的模型对新图像进行分类。首先,您将在 Jupyter 笔记本中开发代码,以确保您的训练实施效果良好。然后,您将代码转换为 Python 应用程序,然后从系统的命令行运行该应用程序。

使用 Python 进行数据可视化
目标大数据作为一个行业正在以惊人的速度增长,每天产生近 2.3 万亿 GB 的数据,数据总量每隔几年就会翻一番。因此,理解所有这些数据并利用它们改变我们的生活和互动方式的能力必将成为商业的重要组成部分。今年大数据市场规模预计将增长 73 亿美元,预计未来几个月将飙升至 400 亿美元大关,这就是为什么需要新一代训练有素的数据专家和分析师来引领潮流并建立更好的数据治理以赢得消费者。本次研讨会的目的是向学生介绍数据可视化的概念,并通过从探索性数据分析到 Covid-19 数据可视化分析的实际示例向他们传授基础知识。

python的ML简介
Srimanta Mandal博士于2017年获得印度IIT Mandi的博士学位。从2017年到2018年,他一直是印度IIT马德拉斯电气工程部的博士后研究员。自2018年10月以来,他一直在甘地纳加尔(Gandhinagar)担任Daiict,目前是副教授。在他的博士学位期间,他获得了IIT Mandi的旅行赠款,以在法国巴黎的2014年国际图像处理会议上介绍工作。到目前为止,他已经监督了20名硕士学生的论文/项目工作,并共同监督了1名博士生。他在国家/国际期刊和会议上发表了几篇文章。他在印度计算机视觉,图形和图像处理2018的印度会议上获得了最佳纸张奖(亚军)。他曾担任各种会议和期刊的审稿人。他从2019年至2022年担任IEEE SPS GUJARAT分会的执行委员会成员。他是Iuprai和ISRS的终身会员。他的研究兴趣包括图像处理,计算机视觉和机器学习。有关更多详细信息,请单击此处
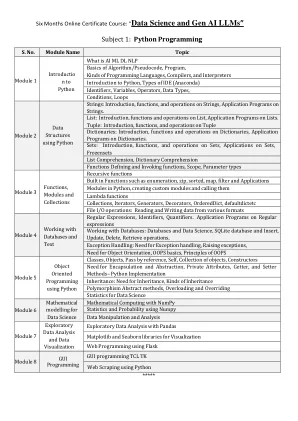
主题1:Python编程
字符串:在字符串上的引言,功能和操作,在字符串上的应用程序。列表:列表上的简介,功能和操作,列表上的应用程序。元组:元组词典上的简介,功能和操作:词典上的简介,函数和操作,词典上的应用程序。集合:集合的简介,功能和操作,集合上的应用程序,frozensets列表理解,字典理解函数定义和调用功能,范围,参数类型

Python 和 Tkinter 编程
4.1 Tkinter 控件导览 31 Toplevel 32, Frame 33, Label 35, Button 36, Entry 37, Radiobutton 37, Checkbutton 38, Menu 39, Message 42, Text 43, Canvas 44, Scrollbar 45, Listbox 45, Scale 46 4.2 字体和颜色 47 字体描述符 47, X Window System 字体描述符 47, Colors 48, 设置应用程序范围的默认字体和颜色 49 4.3 Pmw Megawidget 导览 49 AboutDialog 50, Balloon 50, ButtonBox 51, ComboBox 52, ComboBoxDialog 53, Counter 54, CounterDialog 55, Dialog 56, EntryField 56, Group 57, LabeledWidget 58, MenuBar 59, MessageBar 59, MessageDialog 61, NoteBookR 61, NoteBookS 62, NoteBook 63, OptionMenu 64, PanedWidget 65, PromptDialog 66, RadioSelect 66, ScrolledCanvas 67, ScrolledField 68, ScrolledFrame 69, ScrolledListbox 70, ScrolledText 70, SelectionDialog 71, TextDialog 72, TimeCounter 73 4.4 创建新的 megawidget 73 megawidget 的描述 73, 选项 74, 创建 megawidget 类 74

python在上下文中编程
Python编程在上下文中,第四版提供了对Python基本面的全面介绍。使用Python 3.10更新,第四版提供了多个应用领域的详细概述,包括图像处理,密码学,天文学,互联网和生物信息学。采用一种积极的学习方法,每章从一个全面的现实世界项目开始,该项目教授核心设计技术和Python编程,以立即吸引学生。Python为学习者进入计算机科学,数据科学和科学编程的快速扩展领域的理想母语,为学生提供了一个坚实的关键问题解决技能的平台,可以轻松地跨编程语言翻译。本文旨在成为计算机科学的第一门课程,专注于解决问题,并根据需要引入语言功能以解决手头的问题。

LEGO®能量表
Python编程课程2使用Lego®教育Spike™Prime Set概述在本课程中,学生将通过使用Lego®教育Spike™Prime Set扩展Python编程语言的基础以及编程最佳实践。通过一系列脚手架的课程,学生将学习使用功能,复合条件,数据和数学功能以及列表(数组)来控制程序的流程。他们将定义和记录自己的自定义程序,编写脚本并处理错误。最重要的是,学生将有多种和持续的机会在真实的环境中使用所有这些知识来练习和发展Python的编码技能。在课程结束时,学生将设计,迭代开发和编程机器人或模型的原型。协作工作,给予并接收反馈,并提出建议。调试和故障排除硬件和软件问题。使用算法,数据,复合条件,传感器,循环和布尔逻辑。文档程序,反馈,测试和调试。表达流程图或伪代码以解决复杂问题。将问题和子问题分解为各个部分。讨论偏见和可访问性问题。将解决方案传达到问题,包括模型和编程。学习承诺学生将创建工件并建立模型,以使用电动机,传感器,灯光和声音来创建Python程序有效地工作。他们将利用各种编程技术,包括使用条件语句,循环,布尔逻辑以及线性和计算思维来完成各种任务。学生将把他们的Python知识应用于各种有指导和开放式的项目,这些项目最终在为现实世界中提出解决方案方面达到了最终形式。
