XiaoMi-AI文件搜索系统
World File Search Systemscripts
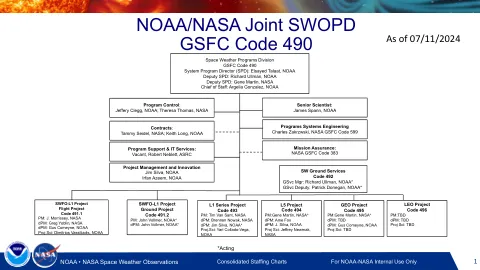
NOAA/NASA联合SWOPD GSFC代码490
代码491.1 PM:J。Morrisy,NASA DPM:Greg Yoblin,NASA DPM:Gus Comeyne,NOA Proj Scripts科学家,NOA

药房福利管理人员在处方药中的作用......
药房福利管理机构 (PBM) 作为药品制造商和医疗保险提供商之间的中介,理论上应该成为降低处方药成本的最佳实体。1 三大 PBM,CVS Caremark (Caremark)、Cigna Express Scripts (Express Scripts) 和 UnitedHealth Group 的 Optum Rx (Optum Rx) 控制着超过 80% 的市场,并与医疗保险公司、药房和提供商进行了垂直整合。2 作为大型医疗集团,有人认为这些 PBM 与保险公司和药房的垂直整合将使它们更有能力改善患者的用药渠道并降低处方药成本。3 但事实却恰恰相反:患者的费用明显更高,选择更少,护理更差。

人工智能中的知识表示 - ijrpr
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.
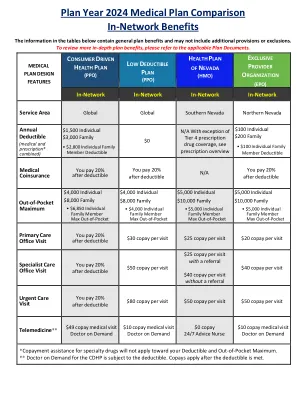
计划年度 2024 医疗计划比较网络内...
消费者驱动健康计划预防药物福利计划预防药物福利计划仅向消费者驱动健康计划的会员提供,参与者无需满足免赔额即可获得某些预防药物,而只需共同保险。根据福利支付的共同保险不适用于免赔额,但适用于自付最高费用。此福利涵盖的药物仅限于 Express-Scripts 确定的预防药物。预防药物包括用于预防高血压、哮喘和高胆固醇等疾病的处方药类别。您可以通过 E-PEBP 门户网站 https://pebp.nv.gov 访问 Express Scripts 网站或致电 Express Scripts 会员服务部 1-855-889-7708 来找到此福利涵盖的合格预防药物列表。

控制
参考:1。医学期刊武装部队印度,2022年9月1日; 78:S158-62 2。麻醉与镇痛,2019年6月1日; 128(6):1098-1105。3。麻醉学。2019年2月; 130(2):203-12。4。麻醉学。2017年2月; 126(2):268-75。5。麻醉学。2018 Jun; 128(6):1099-106。 6。 麻醉学。 2017; 126(2):268-275.11 7。 麻醉学。 2018 Jun; 128(6):1099-1106.7 8。 Anesth肛门。 2019; 128(6):1098-1105.3 9。 麻醉学。 2019; 130(2):203-212.5 10。 J Clin Pharmacol(2017)83 339–348 11. https:/www.accessdata.fda.gov/scripts/cder/cder/ob/search_product.cfm 12.国际临床心理药物学。 1999年7月1日; 14(4):209-182018 Jun; 128(6):1099-106。6。麻醉学。2017; 126(2):268-275.11 7。麻醉学。2018 Jun; 128(6):1099-1106.7 8。Anesth肛门。2019; 128(6):1098-1105.3 9。麻醉学。2019; 130(2):203-212.5 10。J Clin Pharmacol(2017)83 339–348 11. https:/www.accessdata.fda.gov/scripts/cder/cder/ob/search_product.cfm 12.国际临床心理药物学。 1999年7月1日; 14(4):209-18J Clin Pharmacol(2017)83 339–348 11. https:/www.accessdata.fda.gov/scripts/cder/cder/ob/search_product.cfm 12.国际临床心理药物学。1999年7月1日; 14(4):209-18
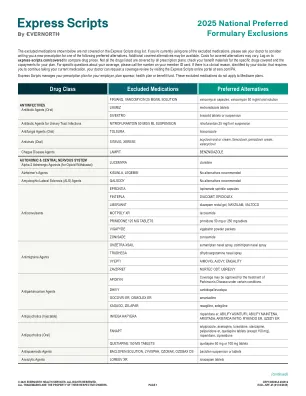
2025 National Preferred Formulary Eustrusions
以下所示的排除药物未涵盖Express Scripts药物清单。如果您当前正在使用一种排除的药物,请请您的医生考虑为您写下以下首选替代方案之一的新处方。可以提供其他涵盖替代方案。承保替代方案的成本可能有所不同。登录到express-scripts.com/covered以比较药品价格。并非所有处方计划都涵盖了所有列出的药物;检查您的福利材料是否涵盖了特定药物以及您的计划的共付额。有关您的覆盖范围的具体问题,请致电您的成员ID卡上的电话号码。如果您的医生确定有临床原因,这要求您继续服用当前的药物,您的医生可以通过访问ESRX.com/PA的Express Scripts在线门户网站,请求覆盖范围。
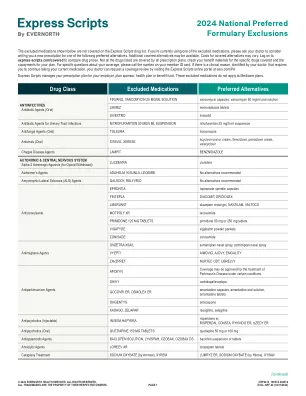
2024 National Preferred Formulary Eustrusions
以下所示的排除药物未涵盖Express Scripts药物清单。如果您当前正在使用一种排除的药物,请请您的医生考虑为您写下以下首选替代方案之一的新处方。可以提供其他涵盖替代方案。承保替代方案的成本可能有所不同。登录到express-scripts.com/covered以比较药品价格。并非所有处方计划都涵盖了所有列出的药物;检查您的福利材料是否涵盖了特定药物以及您的计划的共付额。有关您的覆盖范围的具体问题,请致电您的成员ID卡上的电话号码。如果您的医生确定有临床原因,这要求您继续服用当前的药物,您的医生可以通过访问ESRX.com/PA的Express Scripts在线门户网站,请求覆盖范围。

增强数字客户服务策略的 3 种方法
客户在旅程中会与许多不同的渠道和接触点进行互动;这可能包括客户门户、公共网站、应用程序等。这些互动不能孤立,而是必须在每个渠道上提供一致的信息,以便为客户提供统一的体验。例如,如果公司政策更新,则可能需要在网站、即时通讯机器人、实时聊天脚本、社交媒体渠道、呼叫中心脚本和其他可用接触点上进行更新;高效而成功地做到这一点将被证明是一种强大的竞争优势。

呼吸道合胞病毒疫苗给药疫苗给孕妇和幼儿<2岁<2岁时,向Vaers报告了2023 - 2024年的RESSI
* VAERS报告被归类为严重(基于FDA联邦法规标题21),如果有以下任何报告:住院,住院延长,危及生命的疾病,永久残疾,先天性异常或出生缺陷或死亡或死亡。https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfcfr/cfrsearch.cfm?fr
