XiaoMi-AI文件搜索系统
World File Search Systemtanf

工资出版
SALARY PUBLICATION REPORT - SUMMARY JOB TITLE TOTAL ANNUAL SALARY PAID Division Chief 162,692.00 Academy Instructor 22,345.77 Deputy District Attorney IV 57,801.56 Deputy/Technician - Senior 129,504.43 Academy Instructor 9,176.24 Sergeant 147,393.61 Permit Coordinator II 74,183.36 Records Supervisor 115,980.66代理/技术员 - 高级114,782.88领先法律助理84,159.78车队运营经理126,082.64指挥官150,044.74儿童抚养服务REP 65,447.41 88,025.32法律助理72,647.07人类服务调查员74,840.08中士150,203.69行政助理I 65,149.90拘留专家34,379.35案件经理 - tanf 21,786.68司令150,044.74 Detective 117,7,5221.5221.5221.5221.68 4. 106,162.16指挥官140,990.04设施维护-PEMP 23,340.04环境服务技术技术48,359.68指挥官151,418.48 GIS专家73,736.06部门部门首席162,692.00高级/高级技术人员-114,14,231.90代表 - 助理RP2 41,633.86县专员125,913.06指挥官150,044.74法律助理65,756.02高速公路工人III 93,259.42法律助理61,828.33公园维护公园维护维护II 71,560.08

年度绩效报告
人与社区服务部(HCSD)HCSD监督资格服务以及与蒙大拿州为有需要家庭的临时援助(TANF)计划,补充营养援助计划(SNAP),医疗补助计划,医疗补助计划和健康蒙大拿州儿童(HMK)计划相关的计划和流程。该部门还管理社区服务块赠款,该赠款已由全州十个人力资源发展委员会使用,以提供广泛的基于社区的人类服务计划。儿童抚养服务部(CSSD)CSSD致力于通过建立和执行子女抚养费和医疗抚养费来改善家庭的经济稳定。服务包括定位父母,建立亲子关系,建立财务和医疗支持令,并执行或修改包括医疗支持命令在内的子女抚养费。儿童和家庭服务部(CFSD)CFSD管理儿童保护服务,虐待和忽视服务,预防服务以及其他旨在确保儿童安全和家庭强大的计划。CFSD分为六个地区和一个管理蒙大拿州儿童福利计划的中央办公室。CFSD地区办事处由当地家庭服务咨询委员会提供建议,该委员会是当地社区与DPHHS之间的联系。

为非影片的经济救济付款申请...
###税收和税收部通过提供公平有效的税收和机动车服务来为新墨西哥州服务。IT管理35多个税收计划,并向整个新墨西哥州的州以及地方和部落政府分配收入。TRD努力通过更清晰的沟通,法规,法规,表格,信件和说明来减轻纳税人负担。在税收上与我们联系。最简单的方法是确保您的地址是在Yes-NM网站上最新的:www.yes.state.nm.us。用户可以使用那里的聊天功能简单而轻松地更新其地址。有关如何更新地址的分步说明,请参见此处。我们用所有语言说话,解释和微笑。HSD通过我们的提供商CTS语言链接提供58种语言,向我们的客户提供书面信息,并提供英语和口译服务。在我们的听力和言语障碍客户中,我们使用Relay New Mexico,这是一项免费的24小时服务,可确保通过电话与聋哑人,难以听见,聋哑或言语残疾的个人进行平等的沟通访问。人类服务部通过多个计划,包括:医疗补助计划,有需要家庭的临时援助(TANF)计划,补充营养援助计划(SNAP),儿童抚养计划,儿童抚养计划和几种行为健康服务,为1,062,823个新墨西哥州提供服务和福利。

录取办公室实用护理计划申请指示
•官方辅助阅读理解能力测试分数。阅读任何其他安置考试的分数将不接受。•反思性的陈述描述了您的独特经验和属性(背景,身份,文化,信念,价值观或经验)将如何为您在实际护理计划中的成功做出贡献,并与奥林匹克大学护理计划的任务保持一致。反射性语句的不得超过两页,具有1英寸边缘的双间隔,尺寸为12个字体(Arial或Times New Roman)。•当前的简历描述了您的专业和学术经验的特定活动和责任。包括与医疗保健相关的任何活动,证书和技能。,如果寻求多种语言的文化财富点,请指出简历上使用的任何语言和熟练程度。简历不得超过两页,尺寸为12个字体(Arial或Times New Roman),并具有1英寸边缘。•验证华盛顿州医疗保健专业执照(如果适用)。•DD214或DD215验证兵役(如果适用)。•信件记录了以下州或联邦政府授予的财政援助计划的资格(如果适用):基本的食品就业和培训(BFET)临时援助(TANF),机会赠款,工人赠款,佩尔培训,佩尔·格兰特,华盛顿州财务援助申请(WASFA),华盛顿州需求,免费和减少午餐。颁奖函必须在申请截止日期的12个月内进行日期。

目标、计划、执行、审查和修订 (GPDR/R) 指南
执行功能技能对于我们一生的成功至关重要——它们是基础技能,可帮助我们集中注意力、做出决定、设定目标、控制冲动、制定和执行计划以及在必要时修改和调整计划和目标。虽然在培养儿童执行功能技能方面有着悠久的历史和许多资源,但直到最近,人们才开始关注支持或培养成年人的执行功能技能。(这些技能也称为核心成人能力或执行技能。)明确关注培养和支持执行功能技能以用于人力服务和求职计划的方法的发展在很大程度上源于哈佛大学儿童发展中心为提升成年人在为儿童创造突破性成果方面所发挥的重要作用而做出的努力。安妮·E·凯西基金会希望推动这一框架的发展,以帮助成年人成为成功的工作者和父母,因此资助了多项计划,旨在确定就业和相关人力服务计划如何利用执行功能和自我调节原则和概念来改善父母的结果。出于这种考虑,他们为本指南的开发以及人力服务人员的配套虚拟培训提供了资金。在编写本手册的过程中,我们借鉴了许多人的成果,包括:神经心理学家和应用行为分析师 Richard Guare 以及教育心理学家 Peg Dawson(《Smart But Scattered》系列的作者);明尼苏达大学的神经科学家 Phil Zelazo;儿童国家医疗中心(《目标、计划、执行、检查》)的神经心理学家 Lauren Kenworthy 和她的同事;认知连接(《Ready、Do、Done》)的言语治疗师 Sarah Ward 和 Kristen Jacobsen;伯克利大学的神经科学家 Silvia Bunge;以及纽约大学心理学教授兼《重新思考积极思考》的作者 Gabriele Oettingen。预算和政策优先中心家庭收入支持副总裁 LaDonna Pavetti 领导了目标、计划、执行、审查/修订(GPDR/R)模型的开发以及本手册的编写。 Global Learning Partners 的所有者兼高级合伙人 Valerie Uccellani 和独立顾问 Megan Stanley 担任联合创作者。Global learning Partners 的 Meg Logue 负责了手册的设计工作。Mathematica 的 Michelle Derr 和 Jonathan McCay 是这项工作的重要思想合作伙伴。在本指南的开发和多次修订过程中,我们受益于该领域众多合作伙伴的见解,包括拉姆齐县劳动力解决方案(明尼苏达州)、加州县福利主任协会(CalWORKs 2.0 计划)、俄勒冈州第 2 区 TANF 办公室、经济机会办公室和佛蒙特州的布拉特尔伯勒和拉特兰 TANF 办公室以及纽约市(曼哈顿和布鲁克林)的 NADAP 职业指南。公共咨询集团的 Deb Joffe 和独立顾问 Terri Feely 对初稿提供了有用的反馈。我们中的许多人现在通过执行功能的视角来看待人类服务计划,这在很大程度上要归功于理查德 (Dick) Guare,他教会了我们许多人执行技能如何在成年人生活的各个方面发挥作用,并提供了如何将培养和支持这些技能的策略融入人类服务计划的实用解决方案。

俄克拉荷马州 SoonerSelect 质量战略 2023 年 6 月 13 日
俄克拉荷马州卫生保健局 (OHCA) 成立于 1993 年,负责管理俄克拉荷马州的医疗补助计划,通常称为 SoonerCare。医疗补助计划为没有保险或保险不足的人提供医疗保健。SoonerCare 致力于确保符合条件的俄克拉荷马州人能够获得医疗保健福利和服务,主要基于收入资格要求。资格类别包括老年人、盲人和残疾人 (ABD);根据联邦贫困家庭临时援助 (TANF) 指南符合条件的家庭;合格的医疗保险受益人;根据税收公平和财政责任法案 (TEFRA) 符合条件的儿童;患有乳腺癌和宫颈癌的妇女;以及某些儿童和孕妇。根据联邦批准的州计划,州医疗补助计划由联邦和州政府资助;从 2021 年 7 月 1 日起,俄克拉荷马州的医疗补助计划增加了一个新的成人扩展组。 SoonerCare 一直采用按服务收费的交付系统,由众多供应商为多样化的会员群体提供服务。目前约有 1,351,000 名会员,他们具有不同的背景和医疗保健需求。这约占俄克拉荷马州人口的 34%;在 COVID-19 公共卫生紧急事件结束后,SoonerCare 预计将覆盖俄克拉荷马州约 25% 的人口,即近 100 万居民。约 40% 的会员属于非白人种族/民族。截至 2023 年 1 月,共有 69,529 名签约供应商,其中 9,073 名是初级保健供应商。OHCA 致力于以经济高效的方式改善 SoonerCare 会员的健康和生活质量,正如其愿景和使命中所述:

俄克拉荷马州 SoonerSelect 质量战略
该质量战略是《联邦法规》第 42 条 (CFR) § 438.340 和 42 CFR § 457.1240(e) 的一项要求,它确定了 SoonerSelect 计划的目标,该计划将于 2024 年 4 月开始实施。SoonerSelect 计划将为 Medicaid 内的特定人群提供全面、综合的医疗服务。俄克拉荷马州卫生保健管理局 (OHCA) 成立于 1993 年,负责管理俄克拉荷马州的 Medicaid 计划,通常称为 SoonerCare。Medicaid 为没有保险或保险不足的人提供医疗保健服务。SoonerCare 致力于确保符合条件的俄克拉荷马州人能够获得医疗保健福利和服务,主要根据收入资格要求。资格类别包括老年人、盲人和残疾人 (ABD);根据联邦贫困家庭临时援助 (TANF) 准则符合条件的家庭;合格的 Medicare 受益人;符合《税收公平与财政责任法案》(TEFRA)资格的儿童;患有乳腺癌和宫颈癌的妇女;以及某些儿童和孕妇。根据联邦批准的州计划,州医疗补助计划由联邦和州政府共同资助,从 2021 年 7 月 1 日起,俄克拉荷马州医疗补助计划增加了一个新的成人扩展组。SoonerCare 由众多供应商根据收费服务交付系统管理,会员群体多种多样。目前约有 1,351,000 名会员,他们具有不同的背景和医疗保健需求。这约占俄克拉荷马州人口的 34%;在 COVID-19 公共卫生紧急事件结束后,SoonerCare 预计将覆盖俄克拉荷马州约 25% 的地区,即近 100 万居民。大约 40% 的会员属于非白种人/族裔。截至 2023 年 1 月,共有 69,529 名签约提供商,其中 9,073 名是初级保健提供商。OHCA 致力于以经济高效的方式改善 SoonerCare 会员的健康和生活质量,正如其愿景和使命中所述:

ESA 政策手册 - 华盛顿特区人类服务部
ESA 管理除 MA 之外的所有这些计划。MA 由卫生部管理。根据收入和其他资格要求,特区居民可享受这些福利。每个计划都在不同的联邦和特区立法机构下运作,并有自己的资格要求、收入限制、福利确定、福利水平、公平听证和行政审查程序以及其他规定。特区居民在其中一个 ESA 服务中心申请计划福利。在与 ESA 工作人员进行初步筛选面试后,申请人可能会被推荐到其他机构或其他福利和服务,包括就业机会推荐。该部门使用联合申请 (CA) 表格来申请 MA、TANF、GC、IDA 和 FS 福利,该表格收集了所有五个 ESA 计划的资格信息和文件。此外,特定申请人可以填写 MA 专用申请表,即 D.C.健康家庭申请表。此外,仅希望申请食品券的客户可以使用仅限食品券的申请表。居民有权在申请申请的同一工作日内收到并提交福利申请表。申请人、受助人和部门还拥有其他权利和责任,并在第二部分:基本权利和责任中详细描述。除了这五个主要计划外,ESA 还为难民提供两个计划:难民相关 MA 和难民现金援助。这些计划借鉴了四个主要计划使用的政策。因此,手册并未在每个部分都重点介绍难民计划。第 IV 部分中的第 7.5 节:与难民相关的现金和医疗援助描述了难民计划及其与五个主要 ESA 计划的关系。ESA 还管理丧葬援助计划。该计划在第九部分:特别地方计划中进行了详细讨论。以下各节描述了五个主要 ESA 计划中的每一个,并概述了每个计划的立法权力、资格标准和福利。本手册的后面章节将提供有关政策、资格和福利的更详细说明。医疗援助 (MA) 2.2
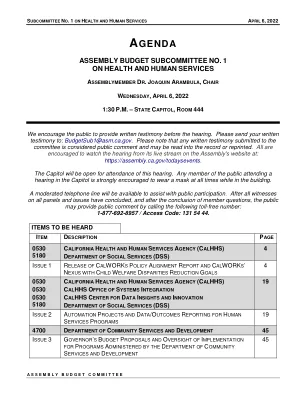
议程 - 议会预算委员会
许多人断言会阻碍家庭稳定,改善父母的结果以及Calworks计划的儿童发展目标?c al Works s P Olicy a strignment r eport报告于2022年4月1日发布。来自加利福尼亚的工作机会和责任对儿童(CALWORKS)成果和问责制审查(CAL-OAR)政策一致性工作组的报告已到期,并于2022年4月1日星期五由加利福尼亚社会服务部(CDSS或DSS)发布。该报告根据议会法案(AB)135(第85章,2021年法规)的要求提出了建议。该法案负责CDSS促进工作组审查CALWORKS法律法规,这可能会为成功实施Cal-OAR造成障碍并提出相关建议。该报告指出,CDSS是该过程的促进者,而不是工作组参与者,并且报告中的建议不一定反映了CDSS或州长政府的意见。在撰写本文时,该报告尚未发布在CDSS网站上,但应很快出现在:https://www.cdss.ca.gov/inforesources/information-formation-formation-resources/family-engement-engemance-and-engemance-and-empower-ypower-ypower-reports-reports-repports。该报告的背景和动力。以下内容来自报告的序言和执行摘要:SB 89(第24章,2017年法规)建立了Cal-OAR,创建了一个本地数据驱动的计划管理系统,该系统通过收集,分析,分析和传播淘汰和最佳实践和最佳实践来促进县Calworks计划的持续改进。该人口称为CalWorks安全网。县福利部门(CWDS)和县福利董事协会(CWDA),在Mathematica的帮助下,作为首席承包商和预算和政策优先级的中心,以及分包商,开发了CALWORKS 2.0,这是一个循证,目标驱动的服务驱动的服务交付框架,以确保独特的整个域中需要进行服务交付的独特服务。[正如先前议程所述,CalWorks]计划是加利福尼亚州的《有需要家庭的联邦临时援助》(TANF)计划的版本。该计划为60个月提供现金援助和服务,以满足家庭基本需求。除了成人60个月的终生援助之外,家庭中的儿童可能会继续得到帮助,直到他们18岁,或直到家庭不再满足收入资格为止。在2020-2021财政年度,Calworks每月在314,678例案件中平均为730,648名儿童。

年度成果目标计划 - 指示
指令一般概述这些说明旨在为完成年度成果目标计划提供帮助:绩效目标,实际和绩效叙事。为了您的方便,每年向所有国家难民协调员提供个性化表格,其中ORR从上一年批准的年度成果目标计划中输入的目标数据。对于每个数据点,请查看输入的信息并进行任何必要的更改。设定目标时,州/机构应建立旨在改善上一年实际情况的目标,同时根据对您州的就业市场和经济环境的知识来维持现实的方法。其他考虑因素包括就业服务的预期案件和/或局限性的就业服务以及影响客户进入就业的各种力量的局限性。为您的方便起见,这些说明附上了最终的完成清单。这是一种工具,可帮助您确保正确完成年度成果目标计划。它仅供您使用,不需要与您的年度成果目标计划:绩效目标,实际和绩效叙述。完成的年度成果目标计划:每年11月30日,应通过电子邮件将绩效目标,实际目标和实际绩效叙述提交给RADS数据库。如果您需要帮助,请通过goran.debelnogich@acf.hhs.gov或(330)907-3480与您的区域代表或Goran Debelnogich联系。1。仅接受州现金援助的难民也应包括在此类别中。案件在实际领域(上一年)的实际领域中,输入未建立的活跃的,可就业的成年人数量,这些成年人通过援助类别招募了就业能力服务。该表格将通过添加每个援助类别的难民数量来自动计算总案件。尚未获得有需要家庭的临时援助的难民(TANF),也不应将难民现金援助(RCA)纳入不应包括联邦现金援助的类别。案件量仅由45 CFR 400.154(a)(c)(d)和(e)下定义的那些积极接收就业服务的难民组成。这些部分的全文可以在ecfr.gov上找到。在FY [本年度]目标下的可用领域中,输入拟议的未建立活跃的,可就业的成年人,将通过援助类别招募就业服务。