XiaoMi-AI文件搜索系统
World File Search Systemtilling

电池操作的耕作机
环境,这对人类健康很危险。为了解决此问题,我们创建了此便携式电源转换器。它是经济的,没有污染。没有理由怀疑农业的新技术,如今,耕种者的工作能力为8至10小时,重量为30至40公斤。此程序包括一个电子转换器。该程序包括链条和链轮,轴承,电动机,自行车轮,轮毂,电池,电气和电缆,安装和连接,框架支撑,螺丝和配件的机械设计和开发。我们在本报告中提出的电耕作非常适合行耕种。这台机器的种植距离为3小时,距离为100米,并使用12伏电池,可以在3至4小时内更换和充电,依此类推。电动机用于机器上。这台机器易于操作,小,易于携带,结构易于维护,易于维护,并且占用了很少的空间。电耕地主要用于在小农场和山区种植种子,也可用于喷洒园艺和粮食作物。比拖拉机相比,较小的农民将养殖用电线杆用于农业。电力的第一个成功示例是电力,电拖拉机。农业是印度经济的骨干,可直接就业人口的69%。是数百万人民的最大就业来源和收入来源,我们的工业产品有一个废物市场。该国的食品谷物生产的两倍从1970 - 71年的5500万吨

这是植物科学领域TILLING时代的终结吗?
自 2000 年推出以来,TILLING 策略已广泛应用于植物研究,以创造新的遗传多样性。TILLING 基于化学或物理诱变,然后快速识别目标基因内的突变。TILLING 突变体可用于基因的功能分析,并且由于是非转基因的,因此可直接用于预育种程序。然而,经典诱变是一个随机过程,会导致整个基因组发生突变。因此,TILLING 突变体携带背景突变,其中一些可能会影响表型并应被消除,这通常很耗时。最近,已经开发并优化了新的靶向基因组编辑策略,包括基于 CRISPR/Cas9 的方法,用于许多植物物种。这些方法精确地仅针对感兴趣的基因,并且几乎不会产生脱靶。因此,问题出现了:植物研究中的 TILLING 时代是否已经结束?在本综述中,我们回顾了 TILLING 策略的基本原理,总结了植物 TILLING 研究的现状并介绍了最近的 TILLING 成果。基于这些报告,我们得出结论,TILLING 仍然在植物研究中发挥着重要作用,是基因组学和育种项目产生遗传变异的宝贵工具。

谷物作物发展的耕作技术战略
1 巴基斯坦费萨拉巴德农业大学植物育种与遗传学系 2 摩洛哥本格里尔穆罕默德六世理工大学农业、肥料与环境科学学院 3 巴基斯坦费萨拉巴德农业大学农业生物化学与生物技术中心 4 巴基斯坦费萨拉巴德农业大学结构与环境工程系 * 联系方式:noumankhalidpbg@gmail.com 摘要

跨界调整的现实世界证据
资料来源:Latimer NR,White IR,Tilling K,Siebert U.改进了两阶段的估计,以调整随机试验中的治疗切换:g-估计以解决时间依赖性混杂。Stat方法Med Res。2020; 29(10):2900-2918;缩写:PFS:无进展生存; pps:后期生存; OS:总体生存; ITT:打算

在...
12 Hermetia Illucens(黑色士兵飞蝇)的遗传特征及其在东北山地区的家禽种植中的替代蛋白质来源的潜在用途。tilling tayo,Robin Bhuyan,Samir Das,Sourabh Deori,Srinivas Kandhan,Kekungu-u Puro,Durlav Bora,Durlav Bora,Sandeep Gangasani,Lakhyajyoti Borah,Papori talukdar,Papori talukdar,Papori talukdar,Adib Haque,Shantanu tamul tamul tamul tamul s. Nabil,L。Sushitra,Meenaksi Kalita和Tanay Ghosh
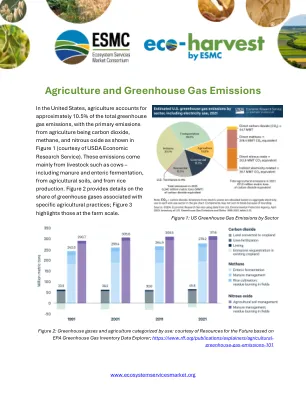
农业和温室气体排放
减少耕作/无耕作可以增加土壤有机碳。耕作的行为可以产生大量一氧化二氮和二氧化碳的释放。减少/否直到将碳保存在土壤中,并避免了一氧化二氮的排放,这本来可以通过全耕作产生的。根据USDA的说法,“无耕种系统用有机物丰富了土壤,增加土壤水的能力并在干旱和洪水期间保护农作物。土壤表面上留下的农作物残留物也可以防止风和水侵蚀,从而使水和空气质量受益”(https://www.climatehubs.usda.gov/hubs/international/international/topic/no-till-till-till-farming-climate-climate-climate-cililienience)。

ADS TEK 解决方案目录 - device.report
这款坚固的鹤嘴锄由锻钢制成,具有两个金属头,一个尖头和一个平头。钢头经过热处理,经久耐用,并涂成黑色。这款工具的主要特点是坚固的硬木手柄,非常适合破碎岩石表面、混凝土或干土。• 36 英寸硬木手柄配有手柄护罩,可提供永久保护• 重型双锻造头配有鹤嘴锄,可用于种植、耕作、地面准备和耕种• 非常适合破碎岩石表面、混凝土和硬化干土• 坚固的木柄可承受反复敲击。• 还提供其他拆除工具。联系 ADS 了解更多信息

基于自然的碳解决方案(NBCS)
NBC旨在利用自然和建造的环境来减轻,适应和增强气候变化的弹性。这些项目采用自然和半天然生态系统的保护,恢复,创造和/或可持续管理,以从大气中清除碳和/或减少温室气体排放。温室气体发射和/或由天然来源存储的温室气体称为景观排放和移除。景观排放可能是由于各种土地使用活动所致,包括植被清理或收获,土壤/泥炭开挖或耕种,水文学或盐分的变化以及肥料等营养或有机物应用。这些实践可能导致景观碳存储的减少和景观排放的增加。当生态系统成分(例如,树木,灌木和土壤)充当碳汇和隔离

使用油料作物中的基因编辑对脂肪酸剖面和油含量进行修饰
基于各种化学和物理诱变剂的抽象突变育种会诱导并破坏非靶基因座。因此,视觉筛查需要大量人群,但是所需的植物很少见,这是识别理想突变体的进一步费用。生成的突变体由于非靶向突变而具有很高的缺陷,农艺性能差。突变技术通过靶向诱导的基因组局部病变(耕种)增强,促进了理想种质的选择。另一方面,通过CRISPR/CAS9进行编辑的基因允许将基因敲低以进行定位突变。这种方便的技术已被利用用于修饰脂肪酸剖面。在广泛的农作物中获得了高油酸遗传库存。此外,将淀粉,多乳糖和口味等不良种子成分积累的基因被拆除以提高种子质量,这有助于改善油含量并减少抗营养成分。

番茄功能基因组学研究职位
在番茄基因组资源库 (https://lifesciences.uohyd.ac.in/rtgr/),这是一个 DBT SAHAJ 国家设施和 DBT 生物技术卓越与创新中心 (CEIB):“番茄基因组工程计划支持”,我们正在研究番茄功能基因组学,涉及基因组编辑、全基因组测序、蛋白质组学和代谢组学以及 TILLING 方法来操纵番茄果实成熟。该小组目前的目标是分离番茄果实中番茄红素、β-胡萝卜素 (维生素原 A)、叶酸含量高的番茄突变体,并改善番茄植株的结构。有关该小组的最新出版物,请参阅(新植物学家 2023 https://doi.org/10.1111/nph.19510、植物科学前沿 2023 https://doi.org/10.3389/fpls.2023.1290937,园艺研究,2023,10:uhac235,https://doi.org/10.1093/hr/uhac235,植物杂志2022 https://onlinelibrary.wiley.com/doi/10.1111/tpj.15925;植物科学2022 https://doi.org/10.1016/j.plantsci.2022.111177;植物杂志2021 106:844-861。https://onlinelibrary.wiley.com/doi/10.1111/tpj.15206;植物杂志2021 106:95-112。 https://doi.org/10.1111/tpj.15148;等等)。