XiaoMi-AI文件搜索系统
World File Search Systemtokenizer

Allam-1-13b-Instruct
从变形金刚导入automodelforcausallm,autotokenizer allam_model = automodelforcausallm.from_pretrataining(“ allam-1-13b-instruct”)#用模型文件夹路径替换'Allam-1-13B-Instruct')tokenizer = autotokenizer.from_pretrataining(“ allam-1-13b-instruct”)#用模型文件夹路径替换'Allam-1-13b-Instruct'。messages = [{“角色”:“用户”,“ content”:“ toputs = tokenizer.apply_chat_template(消息,tokenize = false)inputs = tokenizer = tokenizer(inputs,return_tensors,return_tensors,return_tensors ='pt'pt'pt',rether_token_tef feldresssssss = kentossss = kento) )对于k,v in Inputs.items()} allam_model = allam_model.to('cuda')响应= allam_model.generate(** inputs,max_new_tokens = 4096,do_sample = true,true,true,true,true,top_k = 50,top_p = 50,top_p = 0.95,top_p = 0.95,温度=。 skip_special_tokens = true)[0])


occworld:学习一个自主驾驶的3D占用世界模型
摘要。了解3D场景如何发展对于在自动驾驶中做出决策至关重要。大多数现有方法通过预测对象框的运动来实现这一目标,该对象框的运动无法捕获更细粒度的场景信息。在本文中,我们探讨了在3D占用空间中学习世界模型OCCWorld的新框架,以同时预测自我汽车的运动和周围场景的演变。,我们建议学习基于3D占用率的世界模型,而不是3D边界框和分割图,原因有三个:1)表现力。3D占用可以描述场景的更细粒度的3D结构; 2)效率。3D占用率更为经济(例如,从稀疏发光点点)。3)差异。3D占用率可以适应视力和激光雷达。为了促进世界发展的建模,我们在3D占用率上学习了基于重建的场景令牌,以获得离散的场景令牌

drivelm:用图形驾驶视觉问题回答
模型。drivelm-agent采用轨迹令牌092,可以应用于任何一般VLM [17、19、23、34],093,以及图形提示方案,该方案模型logi-094 cal依赖关系作为VLMS的上下文输入。结果095是一种简单,优雅的方法,可有效地重新利用096 VLMS用于端到端AD。097我们的实验提供了令人鼓舞的结果。我们发现098在Drivelm上的GVQA是一项具有挑战性的任务,其中Cur-099租金方法获得适中的得分,并且可能需要更好地获得逻辑依赖的100型,以实现101强质量质量质量强大的效果。即使这样,在开放环计划环境中进行测试时,Drivelm-Agent已经有102个已经在最先进的驾驶特定103型型号[13]中竞争性地发挥作用,尽管其任务不合时宜和通用架构,但仍有104个模型。fur-105 Hoperore,采用图形结构可改善零弹性106概括,使Drivelm-Engent在训练或部署期间在108 Waymo DataSet [28]进行训练或仅在NUSCENES [3] 109数据上训练后,在108训练或部署期间都看不见新颖的对象。从这些结果中,我们认为,提高GVQA 110具有建立具有强烈概括的自动驾驶111代理的巨大潜力。112

phanaki:可变长度视频生成
我们提出了一个能够实现现实视频综合的模型,给定一系列文本提示。由于计算成本,数量有限的高质量文本视频数据和视频长度的变化,因此从文本中生成视频尤其具有挑战性。为了解决这些问题,我们介绍了一种新的模型,以学习视频表示,该模型将视频压缩为一小部分离散令牌。这个令牌仪会及时使用因果关注,这使其可以与可变长度视频一起使用。为了从文本生成视频令牌,我们使用的是在预先计算的文本令牌上进行的双向蒙版变压器。随后对生成的视频令牌进行了解密以创建实际的视频。为了解决数据问题,我们演示了大量图像文本对的联合培训以及少量的视频文本示例如何导致概括超出视频数据集中的可用内容。与以前的视频生成方法相比,Phanaki可以生成以一系列提示为条件的任意长视频(即时间变量文本或故事)在开放域中。据我们所知,这是第一次研究从开放域时间变量提示中生成视频的论文。此外,与每个框架基线相结合,所提出的视频编码器计算每个视频的代币较少,但会导致更好的时空一致性。

sansgpt:在梵语中推进生成预培训
在过去的十年中,在数字化梵语文本和推进语言的计算分析方面取得了重大进展。然而,为促进NLP的努力促进了诸如语义类比预测,命名实体识别和其他人的复杂语义下游任务,而其他人仍然有限。此差距主要是由于缺乏建立在大规模梵文文本数据上的坚固,预先训练的梵文模型,因为这需要大量的计算资源和数据准备。在本文中,我们介绍了Sansgpt,这是一种生成的预培训模型,已在大量的梵文文本上进行了培训,旨在促进下游NLP任务的微调和开发。我们的目标是该模型是推进梵语NLP研究的催化剂。此外,我们开发了一种专门针对梵语文本优化的自定义令牌,从而实现了复合词的有效令牌化,并使其更适合生成任务。我们的数据收集和清洁过程涵盖了各种各样的可用梵文文献,以确保培训的全面代表。我们通过对语义类比预测和明喻元素提取进行微调来进一步证明该模型的疗效,分别达到了大约95.8%和92.8%的令人印象深刻的精度。
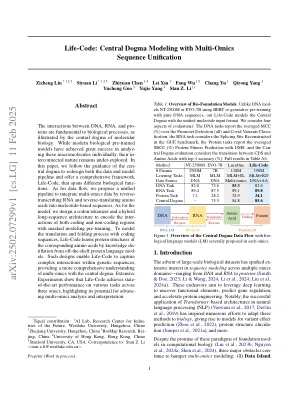
生命代码:具有多词序列统一的中央教条建模
如分子生物学的中心教条所示,DNA,RNA和蛋白之间的相互作用是生物过程的基础。现代生物学预训练的模型在分析这些大分子方面取得了巨大的成功,但它们的感染性质仍未得到探索。在本文中,我们遵循Central Dogma的指导来重新设计数据和模型管道,并提供一个全面的框架,即生命代码,这些框架涵盖了不同的生物功能。至于数据流,我们提出了一条统一的管道来通过将RNA转录并反向翻译为基于核苷酸的序列来整合多词数据。至于模型,我们设计了一个密码子令牌和混合长期架构,以用遮罩的建模预训练编码编码和非编码区域的相互作用。通过编码序列对翻译和折叠过程进行建模,生命代码通过从现成的蛋白质语言模型中的知识分离来学习相应的氨基酸的蛋白质结构。这样的设计使生命代码能够在遗传序列中捕获复杂的相互作用,从而更全面地了解了与中央教条的多摩学。广泛的实验表明,生命代码在三个OMIC的各种任务上实现了状态绩效,突出了其进步多摩学分析和解释的潜力。

genad:生成端到端的自主驾驶
摘要。直接产生原始传感器的计划结果一直是长期以来的自动驾驶解决方案,最近引起了人们的关注。大多数现有的端到端自主驾驶方法将此问题分解为感知,运动预测和计划。但是,我们认为传统的渐进式管道仍然无法全面地对整个流量演化过程进行建模,例如,自我汽车与其他交通量之间的未来相互作用以及事先的结构轨迹。在本文中,我们探索了一种新的端到端自动驾驶范式,其中关键是预测自我汽车和周围环境如何发展给给定的场景。我们提出了Genad,这是一种生成框架,将自主驱动式驱动为生成的建模问题。我们提出了一个以实例为中心的场景令牌,它首先将周围的场景转换为地图意识到的实例令牌。然后,我们采用差异自动编码器来学习结构潜在空间中的未来轨迹分布,以进行先验建模。我们进一步采用时间模型来捕获潜在空间中的代理和自我运动,以生成更有效的未来轨迹。genad最终同时通过在实例令牌的条件下并使用学习的时间模型来生成期货的学习结构潜在空间中的采样分布来同时执行运动前词和计划。在广泛使用的Nuscenes基准上进行的广泛实验表明,拟议的Genad在以高效率上实现了以视觉为中心的端到端自动驾驶的状态表现。代码:https://github.com/wzzheng/genad。

信标:全面RNA任务和语言模型的基准
RNA在将遗传指令转化为功能外的功能中起着关键作用,强调了其在生物过程和疾病机构中的重要性。尽管出现了许多深度学习方法,尤其是通用RNA语言模型,但仍缺乏标准化的基准来评估这些方法的有效性。在这项研究中,我们介绍了第一个全面的RNA基准标签(Be NCHM A RK用于任务和语言模型)。首先,Beacon构成了13项不同的任务,这些任务涵盖了结构分析,功能研究和工程应用的广泛工作,从而可以对各种RNA理解任务的方法进行全面评估。第二,我们检查了一系列模型,包括CNN等传统方法以及基于语言模型的高级RNA基础模型,为这些模型的特定任务性能提供了宝贵的见解。第三,我们研究了从令牌和位置编码方面的重要RNA语言模型组件。值得注意的是,我们的发现强调了单个核苷酸令牌化的优势以及与传统位置编码方法相比,用线性偏见(Alibi)抚养的有效性。基于这些见解,提出了一个简单而强大的基线,称为Beacon-B,可以通过有限的数据和计算资源来实现出色的性能。我们的基准标准的数据集和源代码可在https://github.com/terry-r123/rnabchhench上获得。

临床环境 - 意识到生物医学文本摘要使用深神经网络:模型开发和验证
背景:自动文本摘要(ATS)使用户能够从生物医学存储库的大数据中检索有意义的证据,以做出复杂的临床决策。深度神经和经常性网络在自然语言处理和计算机视觉领域的传统机器学习技术优于传统的机器学习技术;但是,它们尚未在ATS域中探索,特别是对于医学文本摘要。目的:生物医学文本ATS中的传统方法遭受了基本问题,例如无法捕获临床环境,证据质量和目的驱动的段落选择。我们的目的是通过从可靠的已发表的生物医学资源中提取精确,简洁和连贯的信息来规避这些限制,并构建一个简化的摘要,其中包含最有用的内容,可以为临床需求提供特定的审查。方法:在我们提出的方法中,我们引入了一个新颖的框架,称为生物膜,可提供优质意识的患者/问题,干预,比较和结果(PICO)基于智能和上下文支持生物医学文本的摘要。BioMed-Summarizer将预后质量识别模型与临床环境感知模型相结合,以在生物医学文章的主体中找到文本序列,以在最终摘要中使用。首先,我们开发了一个深度的神经网络分类器,用于质量识别,以获取科学的声音研究并过滤其他研究。最后,我们从研究类型,发布可信度和新鲜度得分汇总的高得分PICO序列中产生了代表性摘要。第二,我们开发了一个双向长期记忆记忆复发性神经网络作为临床环境 - 意识分类器,该分类器是通过使用单词插入令牌制成的语义丰富特征进行培训的,该特征用于识别代表Pico文本序列的有意义的句子。第三,我们使用Jaccard相似性与语义富集计算了查询和PICO文本序列之间的相似性,其中使用医学本体学获得了语义富集。结果:使用与颅内动脉瘤相关的大型生物医学文献数据集评估预后质量识别模型,在识别质量文章方面,准确性为95.41%(2562/2686)。临床环境 - 意识到多类分类器优于传统的机器学习算法,包括支撑矢量机,梯度增强的树木,线性回归,k-neart邻居和天真的贝叶斯,通过实现93%(16127/17341)的准确性,用于分类五个分类:目标,互动,互动,互动,互动,结果,结果,结果。语义相似性算法在语义富集后,在众所周知的Biosses数据集(具有100对句子)上实现了明显的Pearson相关系数(0-1尺度),比基线JACCARD相似性提高了8.9%。最后,我们发现三个领域专家对不同指标进行的评估之间的高度正相关,这表明自动汇总是令人满意的。