XiaoMi-AI文件搜索系统
World File Search Systemtool


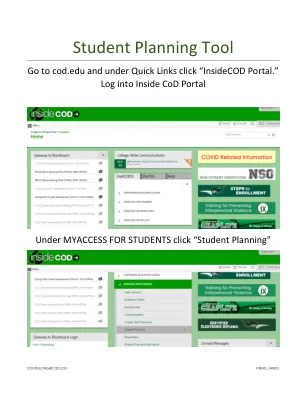
学生计划工具说明
课程类型描述 - 混合 (HYB) 课程在校园内面对面授课,并要求在线学习。学生将在校园内进行实验室、工作室或临床工作。每个部分的面对面会议日期和时间将根据课程和学习需求而有所不同。虚拟课堂会议 (VCM) 课程在指定的日期和时间使用视频聊天软件完全在线实时开会。所有作业均在线提交。这种形式旨在让学生以虚拟形式进行定期的面对面接触。在线 (NET) 课程完全按照讲师的时间表和学习成果在线授课。学生主要通过讨论板、书面信息和作业进行互动,所有作业均在线提交。重要提示:以上所有交付格式都有在线组件。为了确保成功,学生应尽最大努力获得足够的计算机硬件和软件,包括网络摄像头和足够的 Wi-Fi 服务。如果学院需要关闭,这可能尤为重要。


一种了解消费者行为的工具
摘要本文研究了消费者行为中神经营销的概念,强调了一个事实,即消费者在决策过程中并不完全比例,因为情绪会影响他们的行为。因此,神经营销领域是一种理解消费者潜意识动机的一种方式。本文的科学问题是分析如何有效地与传统的营销研究方法相结合,以提供对消费者行为的全面理解。它强调了一个事实,即传统的营销研究工具可能无法揭示对消费者行为研究的所有基本见解。因此,市场研究实践应采用神经营销工具,例如眼睛跟踪,面部表达分析,生物识别技术和神经元活动测量。首先,确定了六个主要的神经营销研究领域:品牌,产品设计和创新,广告效率,购物者决策,在线体验和娱乐效率。接下来是一个简化的人类行为模型,由三个阶段组成,无意识,有意识和可观察到,这是令人不快的。最后,本文着重于对神经营销和道德问题的批评。关键词:神经营销,神经营销工具,消费者行为。

DSMES图表审核工具
4。dsmes遭遇:在每次遇到的文档中需要下面的每个项目。然后是下一步(参与者将在两个单独的相遇中记录的DSMES会话之间进行的工作)5。沟通至少每次推荐给参考提供商一次,其中包括提供的DSME的摘要,参与者成果和后续计划(需要其他推荐/关键时期)。


药剂师自我评估和自我声明工具...
• 进行自我评估时,您可能需要参考相关法律章节和 PSI 指南。您可以通过 www.irishstatutebook.ie 或 PSI 网站 www.psi.ie 查阅药房和药品法律。 • 国家免疫咨询委员会 (NIAC) 的“爱尔兰免疫指南”可通过国家免疫办公室 (NIO) 网站 www.immunisation.ie 获取。 • 每种疫苗和/或急救药品的产品特性摘要 (SPC) 可通过健康产品监管局 (HPRA) 网站 www.hpra.ie 获取。 • 培训模块的有效性在 PSI 网站上列出,或由培训提供商(如果是 CPR 证书)列出。

量子电路调试工具
摘要 — 随着量子程序的规模不断增长,以匹配传统软件的规模,量子软件工程这一新兴领域必须成熟,调试器等工具将变得越来越重要。然而,由于量子计算机的性质,开发量子调试器具有挑战性;偷看量子态的值将导致叠加部分或完全崩溃,并可能破坏必要的纠缠。作为开发完整量子电路调试器的第一步,我们设计并实现了一个量子电路调试工具。该工具允许用户将电路垂直或水平划分为较小的块(称为切片),并管理它们的模拟或执行,以进行交互式调试或自动测试。该工具还使开发人员能够跟踪整个电路和每个块内的门,以更好地了解它们的行为。早期用户对实用性和可用性的反馈表明,使用该工具切片和测试他们的电路有助于使他们的调试过程更省时。索引术语 — 量子电路、调试、量子软件

网站作为沟通工具和品牌
本研究旨在调查印度尼西亚电信行业中公司官方网站作为沟通媒介和在线品牌推广用途的使用情况。本研究使用了印度尼西亚七家电信公司的官方网站。这些指标用于分析网站内容、网站易用性和网站交互性。本研究的结果表明,印度尼西亚 100% 的电信公司都拥有可用作在线品牌推广策略的网站。这些公司用于在线品牌推广的主要指标是网站内容(100%)和网站易用性(93.65%),而网站交互性的使用(53%)仍需最大化。本研究的结果有助于揭示发展中国家的电信公司如何将其网站用作在线品牌推广的沟通媒介。关键词:社交网络分析、DANA、gopay、金融科技、初创企业。